結果データを上手にまとめるには?
結果をまとめ上げる難しさ パラレルクエリでは、結果をまとめ上げる段階でも大きな苦労があります。
2008年7月16日 20:00
結果をまとめ上げる難しさ
パラレルクエリでは、結果をまとめ上げる段階でも大きな苦労があります。
前回までのサンプルでは、最終的な結果が1つの数値に集約されるため非常に単純でしたが、実際には結果が巨大になることもしばしばあります。そして、結果が巨大であると場合は、通常、ソートや集計が行われています。例えば、検索エンジンの検索結果は、より意味のあるものが上位に表示されるよう何らかの法則でソートされています。
すなわち、各プロセスが分担して計算したぶつ切りの結果を、単純につなぎ合わせるだけでは終わらない場合が多いということです。
基本はデータベースにまとめる
上に記したことを実現するには、まとめ作業のために一時的にデータベースの力を借ります。
具体的には、データベース上に一時的なテーブルを作成し、そこに各プロセスの結果を追記していき、その一時的なテーブルに対して集計やソートを行うクエリを投げ、その結果を返します。
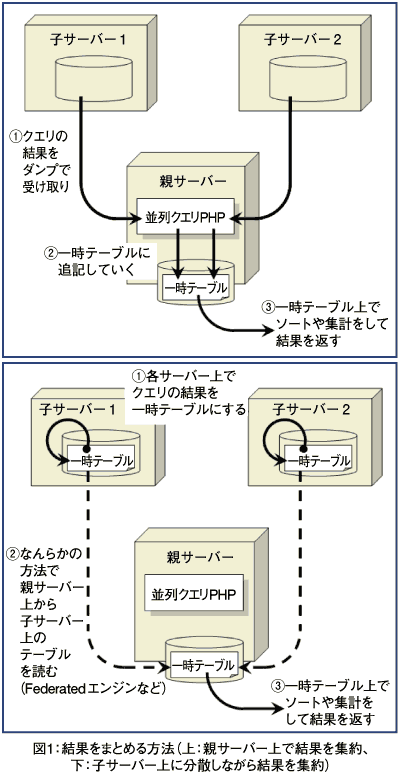
一時テーブルの作成する場所はいくつか考えられますが、シンプルなのは、図1の上に示すように、並列クエリを投げている親のサーバー上に構築することです。
このほかに、並列クエリの結果を集計するための専用のサーバーを設置し、そこで集計する方法などがあります。
また、分担してクエリを行った結果を、それぞれのサーバー上に一時テーブルを作成し、何らかの方法で、1つのサーバー上にこれらの一時ファイルをまとめるという方法もあります。例えば、図1の下に示すように、MySQL5.1以降でサポートされているFEDERATEDエンジンを用いることでこれを実現することができます。
図1の上に示した方法はシンプルですが、結果をまとめる一時テーブルが1つのディスク上に作成されるため、速度面でのネックになる場合があります。この問題は、図1下の方法にすることで理屈の上では解消しますが、FEDERATEDエンジンは本番稼動に適するほど成熟していないといううわさもあり、何より筆者が本格的に使ったことが無いので、自信を持ってお勧めできる状況ではありません。
以降は図1(上)の親サーバー上で結果を集約する方法で進めていきます。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
