ホスティングサーバ監視を自動化するAIアプローチ
GMOペパボは「インターネットで可能性をつなげる、ひろげる」をミッションとし、個人の表現活動を支え活躍できるための場を提供している。「ホスティング」「EC支援」「コミュニティ」「ハンドメイド」の4つの事業領域があり、16サービスを提供している。2001年に提供を開始した個人向けレンタルサーバー「ロリポップ!」は個人から法人まで幅広く使える国内最大級のレンタルサーバーだ。
また、ハンドメイド事業で提供している国内最大のハンドメイドマーケット「minne」は、個人が作った作品をPCやスマホから簡単に販売できるCtoCのプラットフォームのサービスだ。いずれも自社開発のシステムで、バックエンドを含めた運用を自社で行っている。
ウェブサービスの領域で人工知能を活用する場合、顧客体験を改善するマーケティングの事例がよく聞かれる。顧客ごとに最適なサービスを提供するいわゆる「おもてなし」だが、今回は直接ユーザーに触れる部分ではなく、バックエンドのシステム運用に人工知能を活用を活用する事例を紹介する。自社開発のウェブサービスでは運用に人手が取られ、新しい取り組みに手が回らないこともあるため、運用の効率化はユーザー体験にとっても重要だ。
特に共用ホスティングでは、ひとつのサーバーを複数のユーザーが利用し、かつサーバー上で実行されるプログラムやデータをサービス提供側が管理できないという性質上、ユーザーごとのきめ細かい対応が難しいため、画一的なサービスになりがちという課題もある。そこでGMOペパボでは、人手に頼らざるを得なかった運用に人工知能を活用し自動化することで、運用負荷の軽減やユーザー体験の向上を実現する取り組みを行っている。
単純に数値を見るだけでは分からない領域
ユーザーがホスティングサービスに感じる不満は、「ウェブサイトにつながらない」「表示が遅い」「ダウンロードが遅い」といったことだ。このような体験をすると「このサービスは使えない」と判断されてしまい、近年はそういった情報がSNSであっという間に拡散する。そのような事態に陥らないためには、24時間365日の監視が必須だ。ウェブサーバの運用ではリソース使用量などの閾値を設定してアラートを出すようにすると昼夜を問わずアラートが飛んでくることもあり、その都度人の手で対応しなければならない。
そのような運用負荷を減らすためにはできるだけ監視を自動化したいが、どうしても人の目でしか判断ができないパターンがあった。例えば、リソース使用量が急激に上がったとしても、すぐに元に戻るのであれば異常ではなく、そのような一時的な変化、いわゆる外れ値であれば無視したい(図1)。一方で、リソース使用量がそれまでよりも高い状態が継続する場合であれば、閾値に達していなくても早く検知し原因を調査したい(図2)。
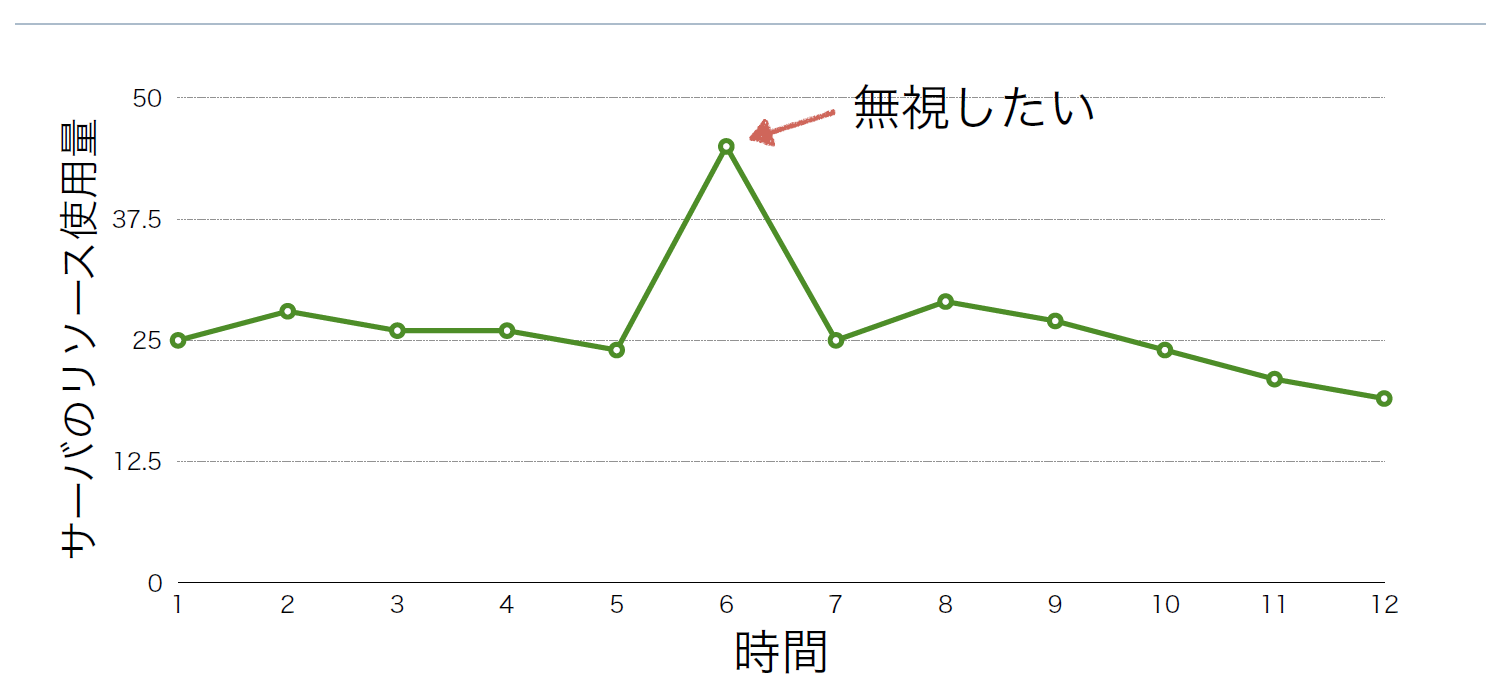
図1:一時的な高負荷は無視したい
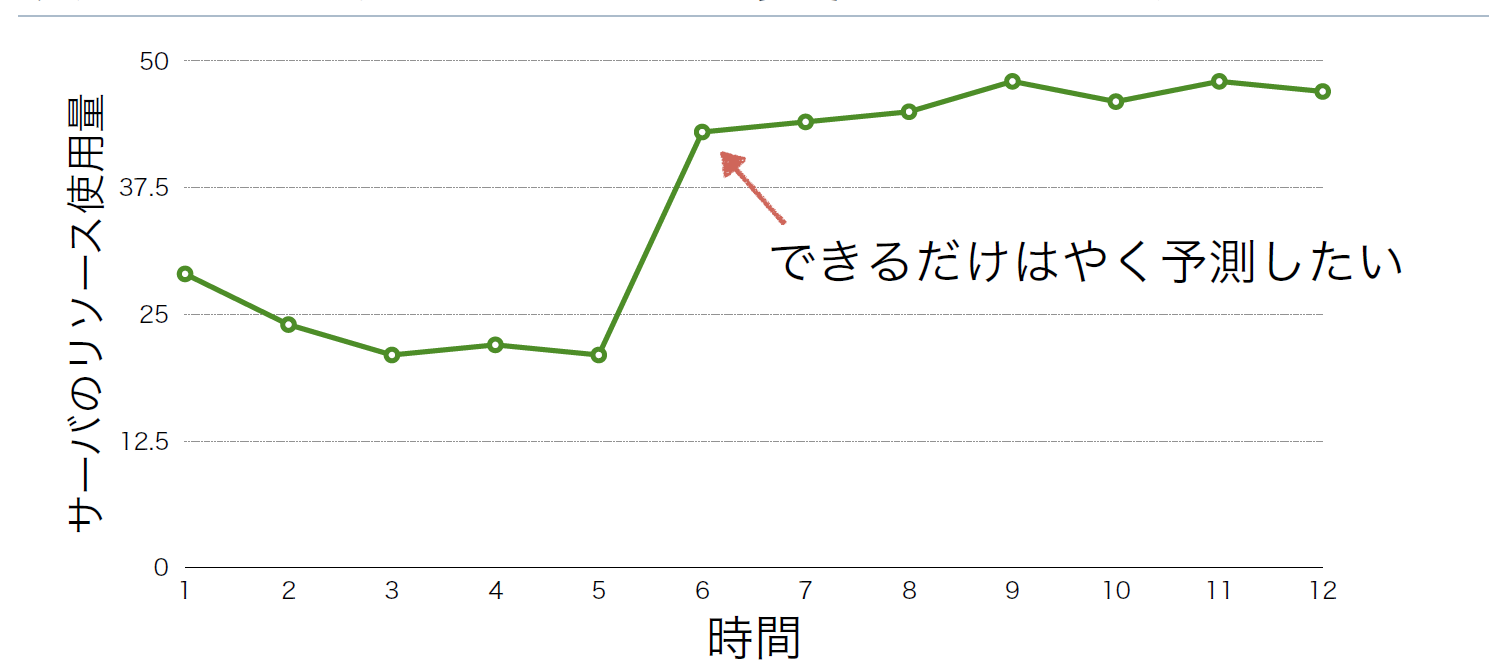
図2:傾向が変化する高負荷は予測したい
さらに、段階的に傾向が変化していくようなパターンでは、変化を捉えることで事前にさまざまな対応が可能であるが、その変化の中でも一瞬の外れ値的な値を無視しつつも、変化点を閾値処理で適切に検知することは難しかった(図3)。
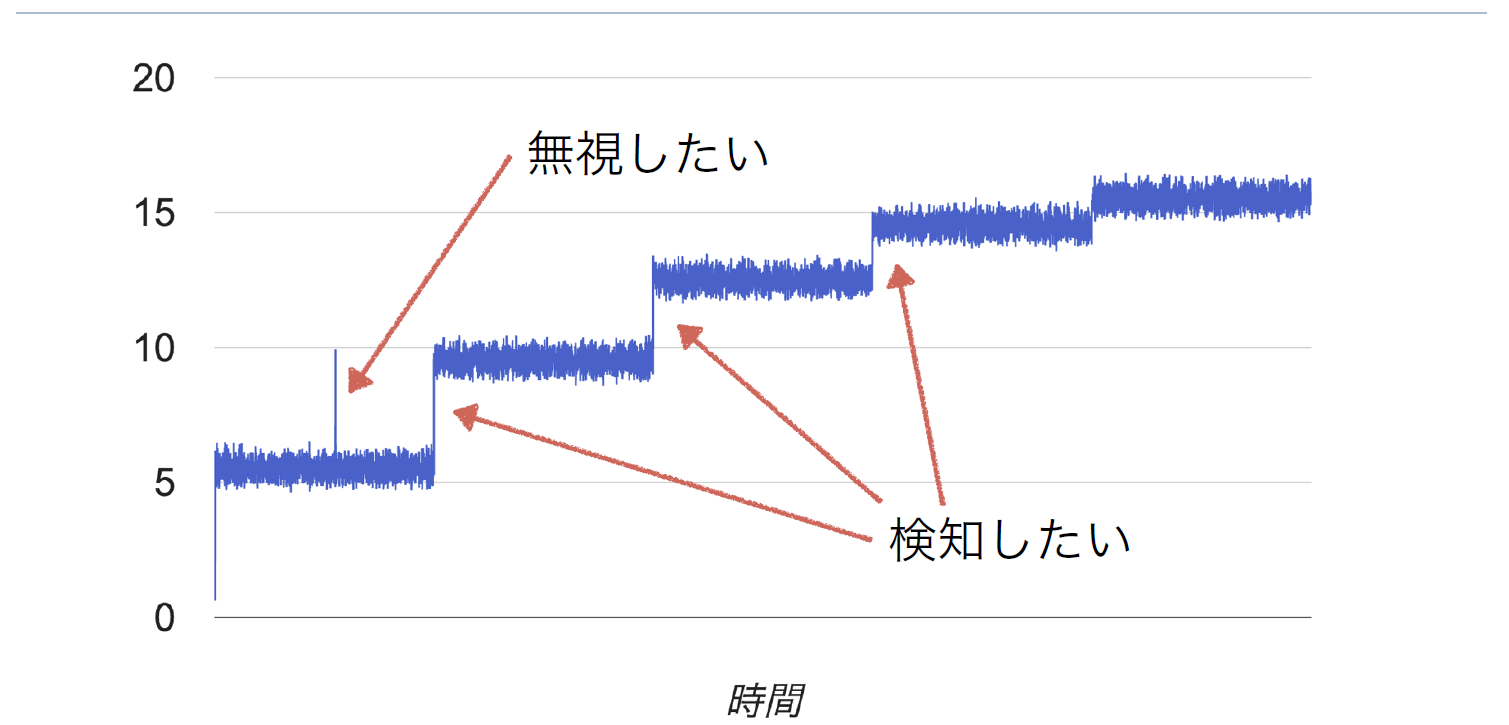
図3:段階的な傾向の変化も検知したい
このように運用経験者が目視で微妙な異常を判断し対応する場合、これまでは自動化が難しかった。リソースの負荷状況は監視ツールでグラフ化されて見ることができるため、パターンの違いは一目瞭然だ。しかし、閾値を越えたらアラートを出すようにすると、一時的な変化でもアラートを出してしまう。アラートが出れば担当者はまずそれを確認しなければならず、運用負荷は下がらないのが従来の課題だった。
このような課題への対処について、GMOペパボの技術基盤チームでインターネットおよびWebシステムの運用技術を研究・開発する松本 亮介氏は、「閾値を設定して、越えたら対応するといういわば手続き型のアプローチを、人工知能などの技術を使って確率や統計的に処理したいというのが、人工知能のデータマイニングの観点から変化点検出を行う研究が盛んになった問題意識のひとつでもあります。弊社においても、システム管理において同様の問題意識を持っていたため、まずはシステム管理における人の目でなければ分からないと思われていた部分の運用負荷を、人工知能のアプローチで改善できないかということを研究して、取り組みとして始めています」と語る。

閾値を越えた時のアラートが正しいかどうかだけでなく、アラートが出ていないケースの問題もある。例えば、閾値は越えていないが一定の変化があり、継続的に変化していく場合だ。ゆっくり変化して最終的に閾値を越えた時にはさまざまな部分に問題が発生しており、どこに問題があるかを調べるだけでも丸一日かかってしまうということがある。これは、変化が始まってすぐに気付けば対応は簡単になるはずだが、閾値を越えるまではアラートが出ないため、人の目でも気づきにくい。
GMOペパボでは、閾値を越えたかどうかでは検知できない領域も含めて、データマイニングや変化点検出、外れ値検出といった人工知能の要素技術を使って解決しようとしている。考え方は、以下のとおりだ。
- サーバやシステムの特徴を抽出し通常状態を学習しておく
- 通常状態から外れた状態を解析する
- 連続的に外れた状態を異常のはじまりとする
ひとつのデータの変化では検知できない異常
変化点検出は通常ひとつの時系列データの変化を検出するものだが、それだけではシステム全体の異常かどうかは判断できない。例えば、あるデータは異常を示しているがシステム全体には影響がないという場合や、個々のデータは異常ではないがシステム全体では異常という場合もある。これを解決するには、複数のデータの関係性を見ると分かることがある。
ある物・事を表すために注目すべき特徴とその程度のことを「特徴量」という(図4、図5)。ウェブシステムの特徴量はCPUの使用率やメモリの空き容量、ネットワークの通信量などさまざまなデータで表すことができる。これらの個々の特徴量の変化は異常ではないが、複数の特徴量のデータを見ると異常だと分かることがある(図6)。
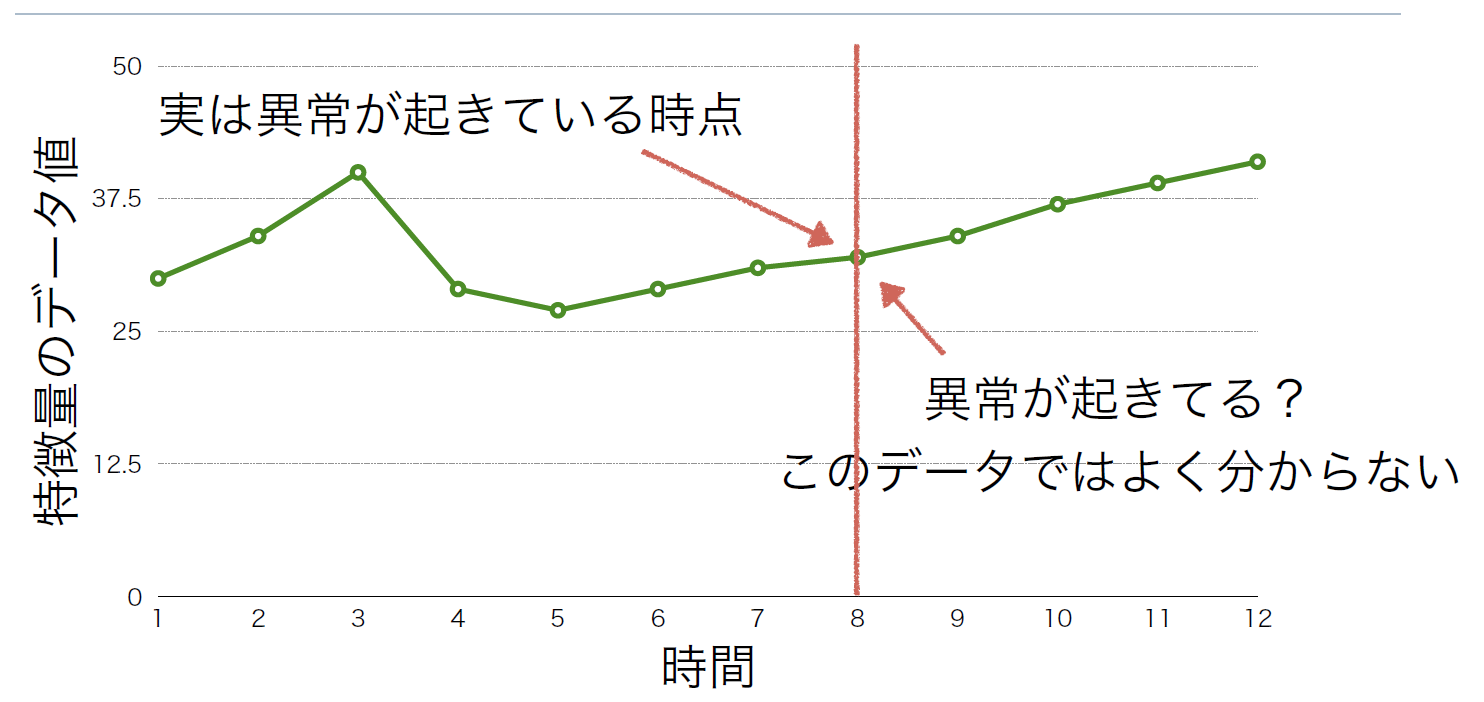
図4:特徴量Aの時系列データ
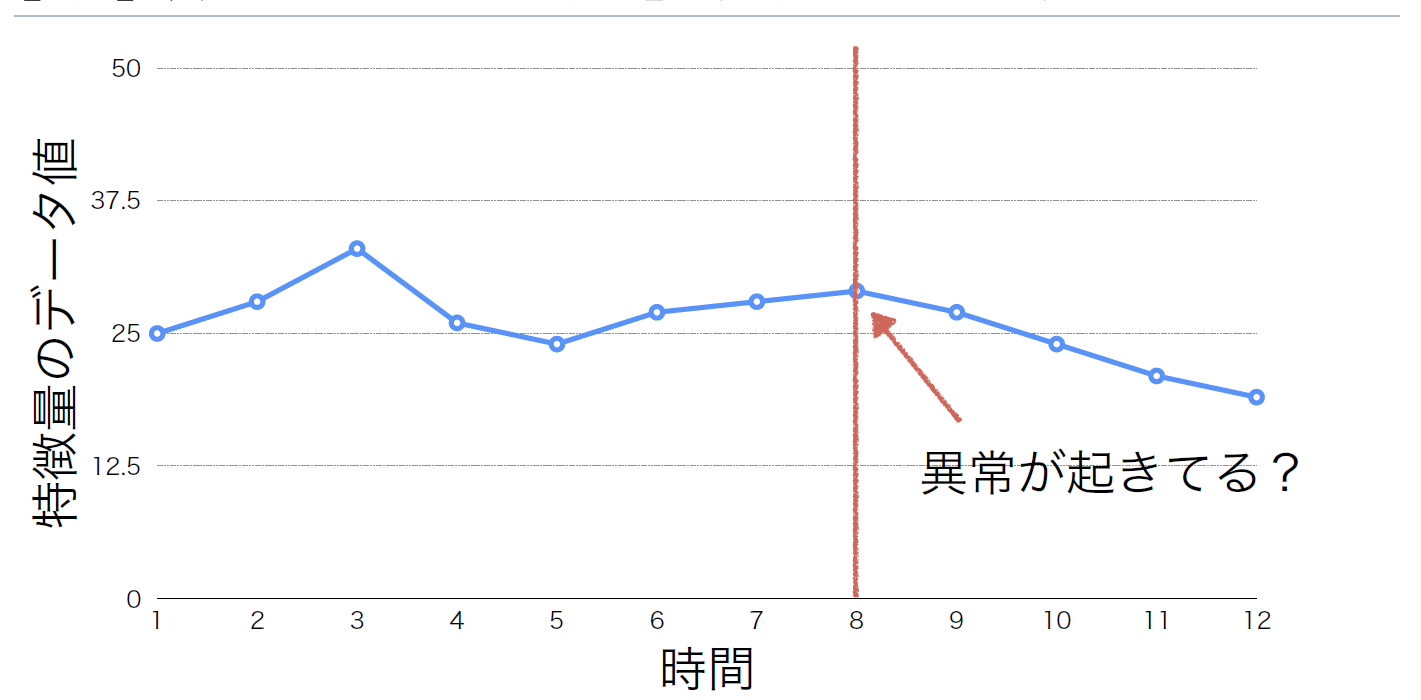
図5:特徴量Bの時系列データ
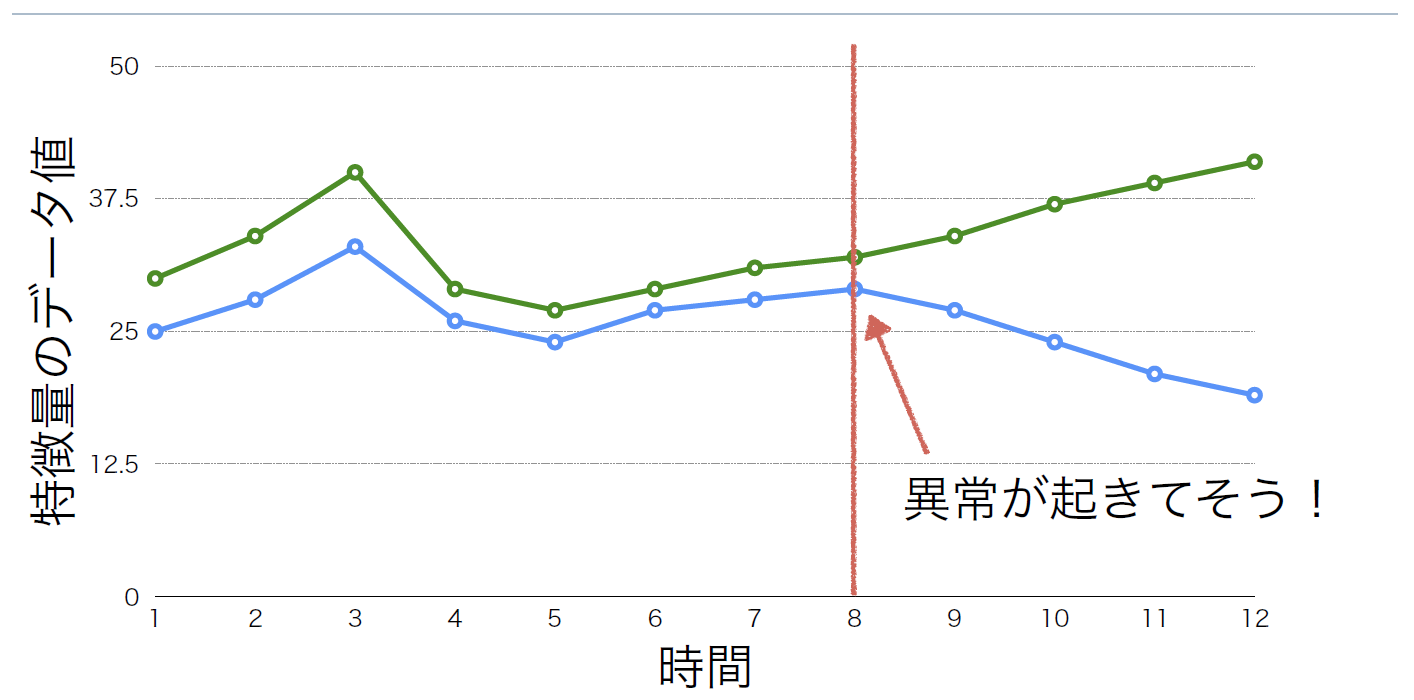
図6:AとBの相関関係を見る
この時、2つの特徴量の関係性という新たな特徴量を定義し、その時系列データを見れば、明らかに異常が起きていると検知することができる(図7)。
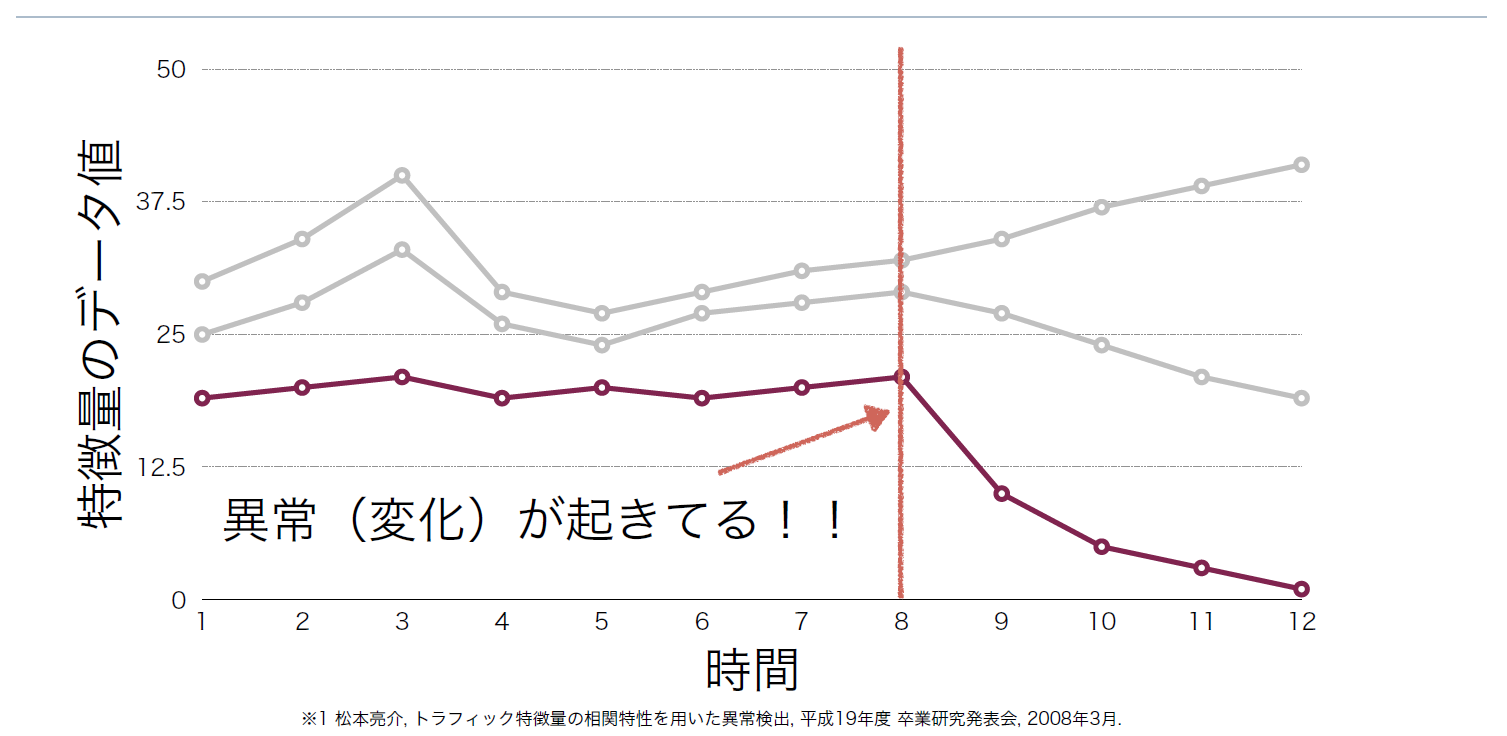
図7:AとBの相関関係の時系列データ
また、個々の特徴量の変化は全体から見れば小さいため、異常とは検知できないこともある。例えば、インターネット通信ではSYNパケットとそれに対する応答であるACKパケットの量は同じような変化を見せるはずで、SYNパケットだけが増えていればDoS攻撃の可能性がある。しかしホスティングの場合は、あるサーバに対するSYNパケットが増えたといっても全体から見ればそれほど大きな変化ではないため、単純な変化点検出では発見できない。この場合でも、SYNが増えているのにACKは増えていないなど、関係性を見れば異常を検知できる。インターネットのトラフィックにはさまざまな時系列データが組み合わさっているので、関係性の変化点検出が重要となる。
このような異常検知の自動化に目的とメリットについて、GMOペパボの執行役員CTOで技術部長の栗林 健太郎氏は次のように指摘する。
「閾値はどんどん増えるばかりですし、ひとつひとつの閾値では分からないこともある。システム管理者であるインフラエンジニアはいわば職人で、彼らの長年の勘によって、閾値を見て関係性を頭の中でつなげて異常を発見してきました。機械がそれをある程度肩代わりして、エンジニアが他の仕事ができるようにしたいというのが目的のひとつ。また、SYNパケットとACKパケットの変化のような、職人の勘では分からないような部分で、機械の方が得意なこともあります。人のパターン認識を、データマイニングや統計的手法を用いて置き換えることで、人の負荷を下げると同時に、より良いユーザー体験にも寄与するでしょう」

サーバの自己監視と自動リソース制御
ホスティングサービスは、ひとつの高性能なハードウェアを複数のユーザーに割り当てる共用サーバとして提供される。また、前提として、貸し出したサーバをユーザーがどのような用途で使用しているかは、GMOペパボが見ることはできない。このため、あるユーザーの利用しているサーバが高負荷になったとしても、コンテンツを最適化するなどの方法で解決することはできない。
そこで、リソース使用量で閾値を設定し、それを越えたら担当者がアクセスを制限するといった運用を行うことになる。管理者側にとっては経験と勘による設定変更を行うことになり、手間も大変だ。さらに、ユーザーにとっては「途中からアクセスできなくなる」という快適ではない状況が起こる。もちろん、共用サーバレンタルとはそういうものだとユーザーも理解して利用しているが、人工知能のアプローチを使うことで、もっと柔軟な対応ができると期待しているという。
「弊社のホスティングサービスでは、一台のサーバに万の単位のユーザーが入っています。あるサーバで極端にリソースを使っているユーザーがいてアラートが出ても、それがどのユーザーなのかすぐには分かりません。一人だけがすごくたくさん使っているならすぐに分かりますが、そこそこ高い比率で使っているユーザーが1000人いるとなると、お手上げです。アクセスランキングなども出していますが、頻繁に順位が入れ替わります。原因を適切に追求しようとしても、なかなかうまくいかずに試行錯誤し、結果的に、そういった運用には何時間も費やしてしまいます。その解決方法が、今まではありませんでした。そのため、多くのユーザーを制限しなければならないという状況に陥っていました。それをしてしまうと、サーバに余裕がある時に解除するなど、ますます運用負荷は高まっていきます」(松本氏)
「一人のお客様に一台のサーバで提供する専用サーバなら運用も分かりやすくなりますが、コストが上がってしまいます。それでは、安くて使いやすいものを提供するという、我々のやりたいことができません。だから、コストを抑えることとユーザーの快適さの両立のために、いろいろな工夫をしています」(栗林氏)
ユーザー数が増えて大規模になるほど、その運用は難しくなる。そこで、「ロリポップ!」では、サーバ自身がリソース使用量を計測し、自分でリソース制御するような仕組みを研究開発している。既に実際のサービスにも部分的に導入済みだ。
①「リソース使用量が閾値を越えたらアクセスできなくなる」を解決する
あるユーザーのサーバにリクエストがあり、コンテンツが実行される時に、実行中のリソース使用量をサーバ自身が自己計測する。その値が閾値を越えるような高負荷な処理だった場合は、次回のリクエストからはCPU使用量を低く抑えて処理速度を遅くする。
これを実現するには、さまざまなプログラムを実装する必要があるが、ここ数年で松本氏が必要なソフトウェアを開発している。まず、サーバがリソース使用量を自己計測するためにウェブ全体のふるまいを定義するのが「mod_mruby」や「ngx_mruby」。定義した特徴量に対して、「mruby-changefinder」が変化点を検出する。「mruby-correlation」を使えば、複数の時系列データの相関関係を単一の時系列データに変換できる。さらに、その結果からOSに対して「CPU使用量を30%に抑える」などの制御をかけるためのプログラムが、「mruby-cgroup」である。これらは、オープンソースとして公開されている。
「自分で検知して自分で制御する。それも、レスポンスを返さないなどの極端な制御ではなく、遅くするという柔軟な制御です。体の細胞にも、自分で正常かどうか確認して、具合が悪かったら細胞分裂を遅くするような仕組みがあるそうで、そこからアイデアをとっています。ポイントは、サーバの状態を表現する特徴量をいかに定義するかという部分です。最終的には、特徴量定義やパラメータ設定などを、適応的決定というか、処理を動かしつつ状態を学習していくような取り組みをしたいと思っています」(松本氏)
これまでは閾値を越えたらまったく繋げなくなるような、on/off型の制御がほとんどだった。それが、ソフトウェアでリクエスト単位でCPUやI/Oの使用を30%にしぼるような制御が、サーバ全体ではなく、ユーザーのドメインごとにできるようになっている。
「もうひとつは、その計算量をできるだけ少なくしたいという動機がそもそもあります。今話題になっているディープラーニングなどは、学習する階層を増やしてものすごいマシンパワーを使って答えを出すという方向性です。しかし僕がやろうとしているアプローチは、自分で検知して制御してといったことを、ウェブサーバのリクエスト処理の中でやる。そこで計算量が大きいと全体のパフォーマンスが落ちてしまい、それでは意味がありません。人工知能のアプローチ、かつ、オンラインの動作に耐えうるように計算量を削減しつつ、自動で制御したいという目的があり、今のところはある程度リアルタイムで処理できる方法を探っています」(松本氏)
②ハードウェアに余裕があるならリソースを自由に使わせる
通常の共用サーバでは、契約したリソース容量をあらかじめ切り出して貸し出す。つまり、ユーザーごとに使えるリソースは決まっているため、ハードウェア全体では余裕がある状態でも、それを超えたら制限がかかるということだ。しかし、ハードウェアに余裕があるなら、ユーザーにそれを使ってもらった方が、ユーザーにとっては快適な状態になる。
そこで、「ロリポップ!」では、ハードウェアに余裕がある限りは必要以上に制限をかけずに、自由にリソースの使用を許している。そのため、共用サーバで使うハードウェアは専用サーバ型のサービスで使うものよりもマシンスペックが高いので、リソースに余裕が有る場合は専用サーバよりも高性能なサーバを利用できることになる。さらに、今ではサーバ自身がリソースの状況を計測して、リソースが足りなくなってきたら平等にリソースを分配するなど、状況に応じて割り当てるリソースを動的に制御することで、ハードウェアのリソースを最大限使えるように制御しつつも、高負荷時にも安定性を維持するといったような柔軟性を実現している。
「今まで、すべてのユーザーに画一的なサービスしか提供できていなかった。それは、そのユーザーがどういう人か、あるいはこちらのシステムが今どういう状態かといったことを細かく把握できなかったからです。松本が開発した技術でサーバのリソース使用率を自動制御できるようになり、まだ個別のおもてなしといえるほどではありませんが、どんどんサービスを使ってもらうといったことができるようになりました」(栗林氏)
なめらかなシステム
現状で実現できていることの先に、この要素技術が目指す世界がある。それを松本氏は「なめらかなシステム」と呼ぶ。これも、生物の仕組みからアイデアを得たという。生物の細胞は時間経過とともに劣化するが、これをエントロピーの増大と捉える。エントロピーが増大するとやがて崩壊するため、細胞はどんどん新しい細胞と置き換わっている。これと同様に、サーバも放っておくと劣化していくので、サーバが壊れる前に新しいVMに置き換えていくというアイデアだ。自己監視によってサーバが自らを壊し、再構築する。壊れる前に新しいサーバに乗り換えていくことで、システム全体としては安定性が保たれる(図8)。

図8:なめらかなシステムの概念図(1)
サーバ領域の利用方法をユーザーに委ねるホスティングサービスでは、ありとあらゆるプログラムが実行される。中には、意図と外れる部分でCPUやメモリを非常にたくさん使ってしまうソフトウェアもある。そのようなソフトウェアを動かし続けていると、場合によってはカーネルパニックを起こすこともあり、最終的にサーバが動かなくなる。対応するためには、サーバをリブートしなければならない。そこで、時間が経てばCPUやメモリが足りなくなったり、その他に未知の異常が発生するのであれば、正常な状態であっても短期間であえてそのVMを壊して新しいVMと入れ換え、VMを循環させるというアプローチだ。
もちろん、入れ換えてもいいシステムとそうでないものはしっかりと区別する必要がある。例えば、データを複数のVMで共有するような設計やそれに対応したステートレスなアプリケーションの実装も必要になるだろう。しかしそれさえクリアすれば、生命で細胞が入れ替わるように、構成要素としてのサーバが循環するシステムが作れそうだ。
現在、GMOペパボではそのための研究とシミュレーションを進めている(シミュレータは「なめらかなシステム」で公開されている(図9))。サーバをグリッド状に並べておき、「両隣のサーバを見て、死んでいたら起こす」というルールを適用する(図10)ことで、時間が経てば循環するシステムを実現する。
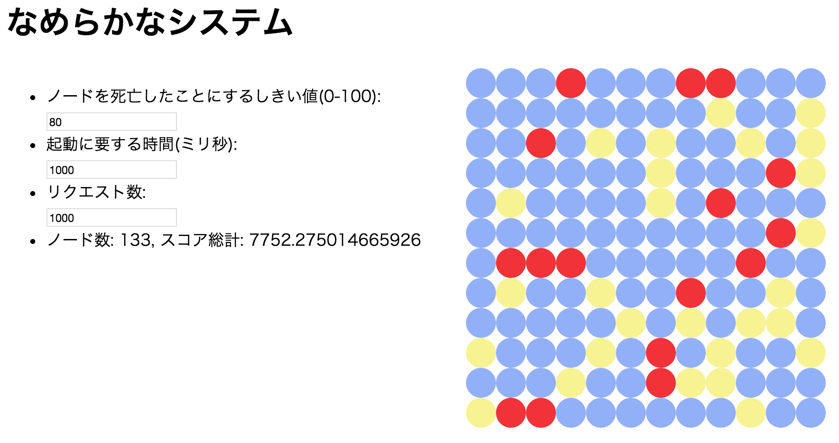
図9:「なめらかなシステム」のシミュレータ
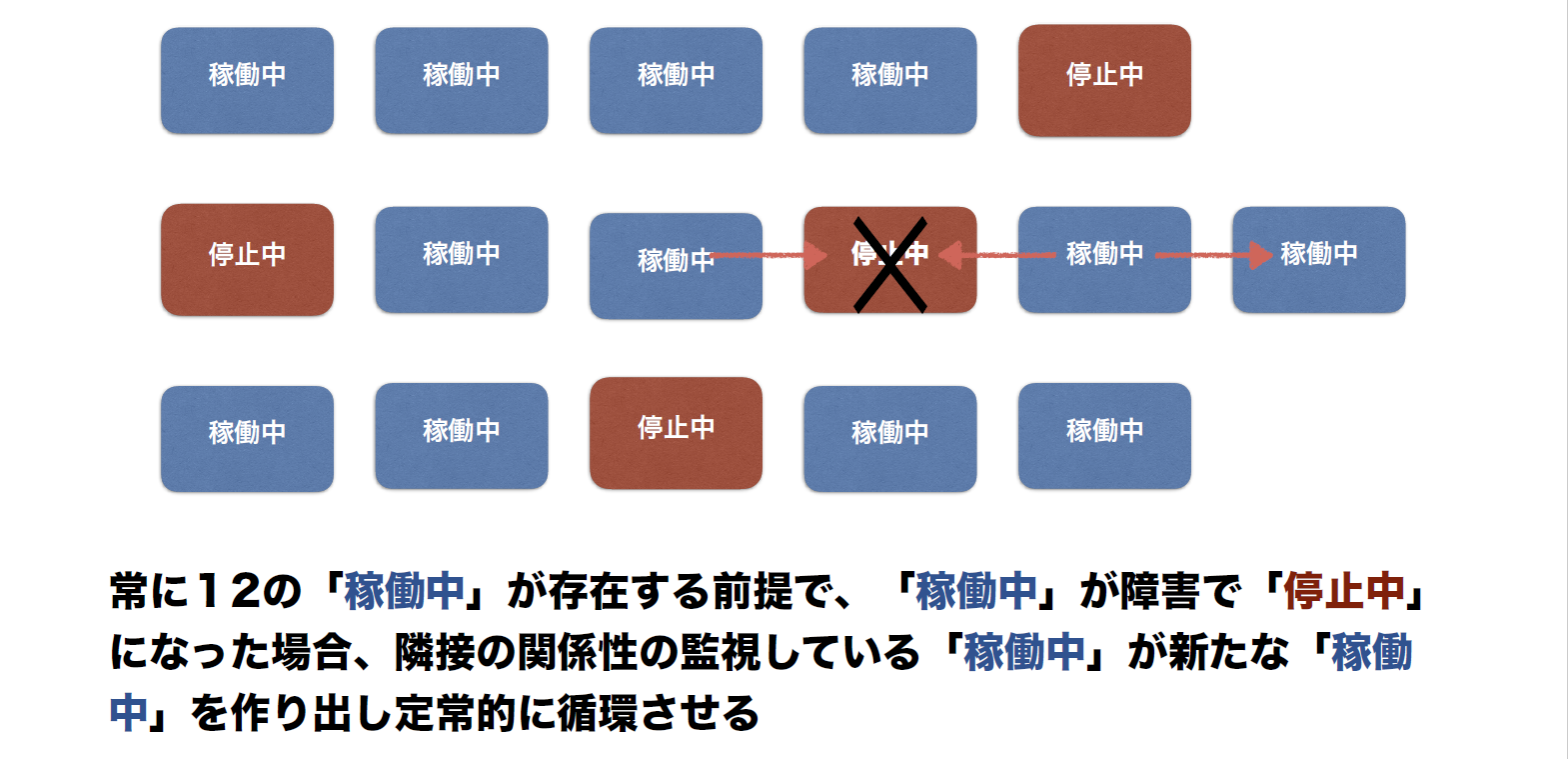
図10:なめらかなシステムの概念図
このシミュレータにおいては、現在のところ以下の3つのパラメータを考慮している。
- システム全体へのリクエスト数
- VMの起動に要する時間
- VMが死んだとみなす負荷のしきい値
その結果として、なめらかなシステムの実現のためにはVMの起動に要する時間の改善が大きなポイントであることが分かった。
「システム全体として要求に応えられればいいわけで、サーバが何台動いているかはユーザーには無関係の管理者側の課題です。要求に応えられるのであれば、それ以外の各要素は新しい状態の方が、基本的には安定します」(栗林氏)
例えば、OSのバージョンアップやセキュリティパッチの適用などをせずに、ずっと同じサーバで稼働していたシステムを、ある時点で新しいバージョンにアップデートしようとすると、いろいろな設定が変わってしまっているなど大変な作業になる。しかし、常に最新の状態のサーバに乗り換えていけば、システムは安定する。
「セキュリティも常にアップデートされるし、ライブラリも古くならないので、ある時期に過去の物ばかりになるという状況も避けられます。もっと言うと、VMを循環させてユーザーが使って問題がなければ、監視や制御は不要かもしれません。例えば、2日しか動かない微妙なソフトウェアでも、2日に一度VMが入れ替わるなら、問題なく稼働します。人間が作るものは決して完全ではなく、多くの場合過ちを犯してしまうことを前提としたような、ある意味人間に信頼を寄せないシステムとも考えられますが、人による運用は必ずミスをするものなので、ミスをしても全体のシステムは影響を受けないという状態を目指したいです。そうなった時に、次の監視の未来は、構成要素であるVMにハードウェアやライブラリのバージョンといった属性を持たせ、VMの循環の状態を機械学習することにより、異常な状態に陥っている属性を検知するといった方向に進んでいくと思っています」(松本氏)
この「なめらかなシステム」の道具立てが揃って、実際の事業に適用できるのは3年後という見通しだ。
「これまでのウェブ技術は、コモディティ化していくものをいかに早く作るかの競争でした。しかしこれからは人工知能のような、少し勉強すればすぐできというわけではない、本当に新しいものを作っていかなければやっていけないという危機感があります。そこで松本がやっているような取り組みを組織化して、「ペパボ研究所」という組織を7月4日に作りました」(栗林氏)
中堅クラスの企業で研究所を設立するのは珍しいが、よりよいウェブサービスを作っていくためには、これまで以上に高度で専門性の高い知識が必要になってくるため、なめらかなシステムの研究をより深めていきたいとの考えだ。また、研究所での取り組みはできるだけ論文化し、アカデミックな世界でも十分に通用する新規性のある研究・開発を行う予定である。社内からもメンバーをアサインするが、複数の専門分野の新規採用も考えている。「対象をより細かに自動的に認識して、すべてのお客様にその状況に応じたサービスを提供する」という最終的なコンセプトに向けて、研究開発を進めるという。
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
さくらインターネット 石狩データセンター
2011年12月7日 20:00
NTTコムウェア スマートクラウド データセンター
2012年3月12日 20:00
一流のエンジニアが集まるクックパッドで聞いたエンジニアのライフスタイルと求められるスキル
2015年10月16日 22:00
モバイルアプリのテスト時における5つの課題とHPEが考えるテスト自動化とその先
2016年1月18日 14:00
スタートアップのCTOってどんな仕事をしているの? Retty樽石さんのケース
2015年11月17日 14:00
クックパッドの開発体制、モバイルアプリを取り巻く環境と課題解決―Think IT Mobile Developer Seminar 2015レポート
2016年2月2日 13:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
