| ||||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||||
| 日本語データの取り扱い | ||||||||||||||||||
今回は日本語データの取り扱いについて取り上げます。日本語データの取り扱いについては、連載「徹底比較!! PostgreSQL vs MySQL」でも少し説明しましたが、今回はさらに仕組みや性能面について取り上げていきます。 | ||||||||||||||||||
| 日本語キャラクターセットのサポート | ||||||||||||||||||
まずは、PostgreSQLとMySQLがデータベース内に収めることができる日本語データのキャラクターセットを示します(表1)。
表1:格納できる日本語のキャラクターセット 表1の通りPostgreSQLとMySQLでは、サポートする日本語データのキャラクターセットの種類に違いがあります。その中でも注意する必要があるのは、PostgreSQLでは代表的な日本語キャラクターセットの1つShift-JISをデータベース内に収めることができない点です。 とはいうものの、Shift-JISのデータを扱えないわけではありません。あくまでもデータベース内に収めることができないだけで、アプリケーションでShift-JISを使用できないわけではありません。 | ||||||||||||||||||
| サーバとクライアント間でのキャラクターセットの変換 | ||||||||||||||||||
データベース内に収めているのとは異なるキャラクターセットをアプリケーション側で使うために、PostgreSQLとMySQLともにデータベースエンジンとアプリケーションとの間で自動的にキャラクターセットを変換する機能を持っています(図1)。 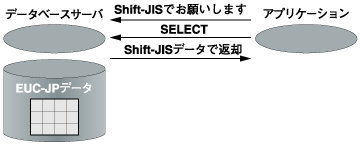 図1:キャラクターセットの変換 例えばShift-JISを使用したい場合、アプリケーションがあらかじめShift-JISを使用することを宣言しておくことにより、データベースが自動的にキャラクターセットを変換してアプリケーションにデータを渡します。この機能を使うことによって、アプリケーションはデータベース内に格納されているキャラクターセットを意識することなく、開発することができます。 このサーバとクライアント間でのキャラクターセットの変換機能ですが、PostgreSQLとMySQLでは、具体的な実現方法に違いがあります。 PostgreSQLは、異なったキャラクターセット間で1対1の変換を行います。具体的な例で説明すると、EUC-JPで格納されているデータに対し、クライアントからShift-JISを要求すると、サーバはEUC-JPのデータ形式を直接Shift-JISのデータ形式に変換してクライアントに渡します。 もう一方のMySQLは、どのようなキャラクターセットもまずはUCS-2に変換し、そこからさらに対象のキャラクターセットへ変換を行います。上記の例にあてはめると、EUC-JPのデータ形式をUCS-2のデータ形式に変換し、変換されたUSC-2のデータ形式をShift-JISのデータ形式に変換します。 もちろん、この変換方法の違いはアプリケーションの開発にはまったく影響しません。 | ||||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30