| ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| PostgresForest Core | ||||||||||||||||
PostgresForest CoreはJavaアプリケーションに対して、PostgreSQLの高可用性や性能拡張を実現するソリューションです。これまではPostgresForestという名称で公開してきましたが、PostgresForest Suiteの公開に伴い、中核をなすパッケージとして、PostgresForest Coreと名称を変更しました。 企業の重要なデータを預かるデータベースは、いかなる理由であれ計画外に停止することは許されず、堅固で高い可用性を求められます。データベースにおける高可用性を実現するためには、一般的にHAクラスタ構成を用いますが、以下の課題がありました。
表3:HAクラスタ構成への問題 SCSIによる共有ディスクに対応しているベンダーもありますが、あまり実績がありません。以前、Webサイト上ではSCSI共有ディスク構成を記載しているものの、営業に問い合せると推奨しないというベンダーもありました。そのため、一般的に共有ディスクというとファイバチャネルを用いた高価なストレージサブシステムの導入が必要となります。しかしコスト面の問題から、共有ディスクの導入(高可用性の実現)を諦めているシステムもあると思います。 HAクラスタソフトは商用製品の実績が多いですが、これも高価なライセンス料が必要です。オープンソースで、ということであればHeartbeat2が存在します。しかし商用製品と異なり、共有ディスクの切り替えスクリプトなどは、利用者が対応する必要があり、容易に使えるというレベルには達していません。 その点PostgresForest Coreは、共有ディスクもHAクラスタソフトも用いずに、高可用性を実現します。 | ||||||||||||||||
| 高可用性 | ||||||||||||||||
PostgresForest Coreは、データベースを複数のサーバ上に冗長化して配置することが可能です。データの更新時に、PostgresForest Core Driverが各データベースノードのPostgreSQLに同一のSQL文を実行し、データの同値性を保証します。障害発生時は、該当サーバを自動的に切り離し、サービスを停止することなく継続させます。このようにして、高価な共有ディスクを使用せずに、高い可用性を実現します。 また、障害発生後の縮退運転状態から、サービスを停止せずに通常状態に復旧させることができます(オンラインリカバリ機能)。 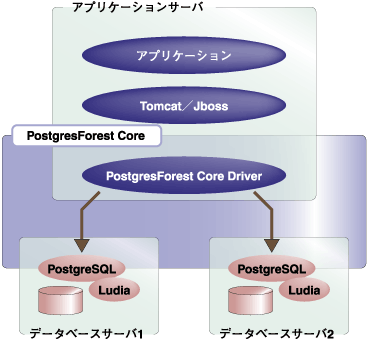 図1:PostgresForestのアーキテクチャ | ||||||||||||||||
| 冗長構成による負荷分散 | ||||||||||||||||
PostgresForest Coreでは、データベースを複数のサーバ上に冗長化して配置することが可能ですが、データを参照する際、アクセスするデータベースを順次変更することにより、大量のトランザクションを分散して処理することができます。これにより、参照アクセスの多いシステムにおいて、スループットを拡大させることが可能です。 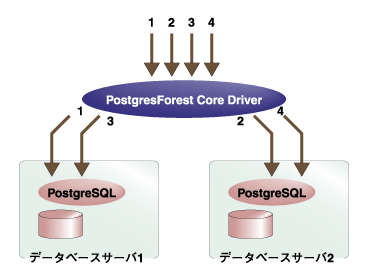 図2:データの冗長構成による負荷分散 | ||||||||||||||||
| 分割配置による負荷分散 | ||||||||||||||||
PostgresForest Coreでは、複数のサーバにデータを分割して配置し、これらのデータに対して検索や集計処理などを並列に同時実行することができます。BIにおけるデータ分析などでは、増大する一方のデータに処理が追いつかずに処理が長時間化する傾向がありますが、PostgresForest Coreでは、データベースサーバの追加により、すぐれたパフォーマンスを得ることが可能です。 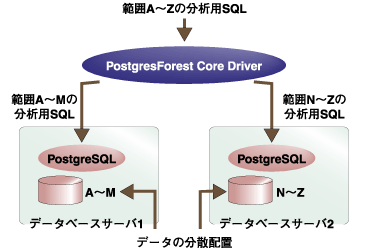 図3:データの分散配置による負荷分散 | ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30