| ||||||||||||||||
| 前のページ 1 2 3 | ||||||||||||||||
| PostgresForest ETL | ||||||||||||||||
企業内のデータは集中して管理されることが理想ですが、様々な場所に存在しているのが現実です。そのため、データウェアハウスを構築する場合のセントラルデータベースのように、分散したデータを集めて使いやすく整理する場合があります。この場合、システムによって文字コードやデータ構造の差異があるため、それらを統合したり、変換したりする必要があります。そういった場合に必要なのがETL機能です。 PostgresForest ETLはホスト系の文字コードを含む、広範な文字コードに対応し、プログラミングレスで容易にデータを授受できます。そのため、メインフレームを含む企業内の様々なデータを取りまとめた情報系データベースを作成する場合などにも対応することができます。 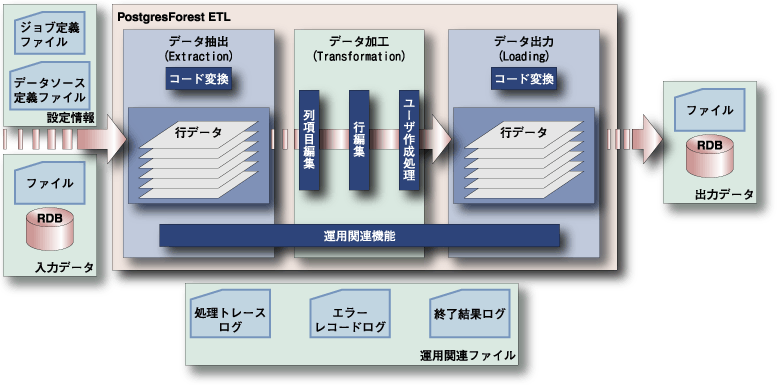 図4:PostgresForest ETLの概要 (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||||||||
| PostgresForest SuiteとLudia | ||||||||||||||||
Ludiaは、単独で使用することも可能ですが、特にPostgresForest Coreと組み合わせることで、可用性を高めたり、単独のデータベースでは扱えない大規模データベースに対応することが可能となります。これにより、さらにLudiaの適用分野を広げることができます。 | ||||||||||||||||
| 高速中間一致検索機能としてのLudia | ||||||||||||||||
筆者らがLudiaを開発した目的の1つが、データベースの中間一致検索(いわゆるLIKE文)を高速に実現する手段として、全文検索エンジンを活用する、というものでした。基幹系システムでは、全文検索を使用することは少ないかもしれませんが、中間一致検索であれば利用する機会も多いと思います。Ludiaを用いることにより、中間一致検索の高速化が図れますが、単独では可用性に不安があります。そのため、PostgresForest Coreとの組合せによる高可用性版Ludiaがソリューションの1つとなります。 | ||||||||||||||||
| 全文検索の今後 〜エンタープライズ全文検索〜 | ||||||||||||||||
最後に、全文検索の今後について私見を述べたいと思います。連載の第3回に、下記の図を示し、Ludiaは企業内の重要なデータを有するデータベースにフォーカスした全文検索機能であることを説明しました。しかし、下記の図が示すように、企業内には他にも様々なデータが存在します。 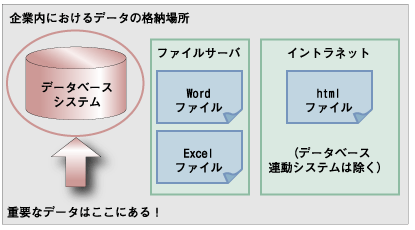 図5:企業内における全文検索対象データ(再掲) ファイルサーバ上のオフィス文書、イントラネット上のHTMLファイル、グループウェア内のデータなど多種多様なデータが存在します。これらの中に、本当に必要なデータが存在する可能性もあるわけです。ですから、本来的に企業に必要な全文検索機能は、これらすべてのデータを対象としたエンタープライズ全文検索であるといえます。 いかに全文検索機能の精度を上げ、抽出漏れを防いでも、その機能が検索対象とできないデータの検索漏れを防ぐことはできません。そのため、将来的に全文検索機能は、すべての企業内データを対象とすることが求められていると考えることができるでしょう。 Ludiaでも、ファイルサーバ内のPDFファイルであれば、パスを登録することにより全文検索対象となります。しかし、通常のファイルサーバは、主に社員がWindows上で操作した結果を直接保存していると思います。そのため、Ludiaへパスを登録する仕組みがなければ、全文検索対象とはなりません。データベースのほかに、ファイルサーバへのアクセスプロトコルやhttpに直接対応したエンタープライズ全文検索機能が、今後の方向性ではないかと思います。 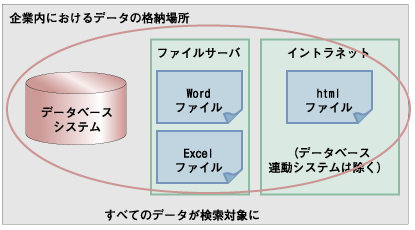 図6:将来の全文検索対象データ とうとう、本連載も終わりを迎えました。3ヶ月ほどの間、ご愛読いただきありがとうございました。今回は、学術的になりがちな全文検索をわかりやすくご紹介し、全文検索を安価に実現するLudiaの導入、使いこなしを説明しました。Ludiaを用いて皆様の企業データの有効活用が進み、皆様の企業のご発展の一助になれれば幸いです。 | ||||||||||||||||
| 前のページ 1 2 3 | ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 7月16日 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 7月16日 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30