はじめに
みなさん、こんにちは。前回はサービスに直接関わるWeb、AP、DBを中心としたミドルウェアについて解説しました。今回もミドルウェアが対象ですが、普段注目されることが少ない「運用」を支えるミドルウェアについて解説していきます。
システムは「設計」→「構築」→「テスト」を経てサービスが開始されます。ところが、サービス開始後の運用が適切になされていないとシステムは停止し、利用者が使用できないという事態が発生します。また、設計段階でシステムの運用が考慮されていないと、運用開始後に右往左往することになります。そこで今回は、「システムの運用ってどのようなことをやっているの?」「運用のミドルウェアって何?」といったギモンにお答えします。
システム運用とは何か
システムのサービス開始。それまで「どのようなシステムを作るか」といった要件に沿って設計・構築をして、テストではさまざまな問題をつぶして、ようやく世の中にリリースされます。しかし、これで終わりではありません。サービス開始は文字通りシステムの始まりであり、そこからは日々システムを動かし続けていく必要があります。では、サービスが開始された後、どのようなことが起きるでしょうか。また、どのようなことをしていかなければならないのでしょうか。
まず、システムに障害はつきものです。「システムを適切に設計し、設計した通りに構築されていることをテストした」と言っても、それでもなお障害は発生します。サーバやストレージ、ネットワーク機器やケーブルなど、扱う対象がハードウェア、つまりモノであるからです。モノには寿命があり、また故障も発生します。ソフトウェアのレベルでも思いもよらない(テストを潜り抜けた)バグが発生します。さらに人為的なミスも発生します。したがって、運用においては「システムの障害は起きるもの」として準備しておくことが重要なのです。なお、準備といってもさまざまな観点のものがありますが、「単一障害ポイントをなくし、バックアップを定期的に取得し、障害検知のために監視をすること」が基本となります(図1)。

図1:障害対策の目的と手段
障害対策以外にも、ユーザ企業に対するシステムの稼働報告、セキュリティ対策のための情報取得といった作業もあります。また、サービスの起動/停止を日次で実施しなければならないシステムもあり、そのような作業も運用に含まれます。
さらに、広義では障害発生時にシステムがサービス提供できるように回復する障害対応や、OSパッチの適用・ミドルウェアのバージョンアップといったシステムに変更を加える保守対応も運用に含まれます(図2)。

図2:運用の種類
運用ミドルウェア
第5回では、ミドルウェアを「ある機能に特化してOSとアプリケーションを補助するソフトウェア」と説明しました。ただし、運用ミドルウェアはOS上で動作しますが、その上にアプリケーションを搭載して動作させる類のものではありません。運用ミドルウェアは機能が特化されており、それ自体が運用アプリケーションとして動作します(図3)。

図3:運用ミドルウェアの立ち位置
それでは、システムでよく使用されている運用ミドルウェアについて具体的に見ていきましょう(図4)。

図4:運用ミドルウェアの分類と製品
1. バックアップ
システムにおいて、「データは命のようなもの」であることを肝に銘じておく必要があります。例えば、「ECサイトのシステムで顧客リストが消失」「銀行システムで残高情報が消失」といった障害が発生すれば、ユーザ企業の業務自体が成立しなくなります。業務データ以外にもOSのイメージやアクセスログなど、障害時でもシステムを迅速にリカバリできるようにするためのバックアップが重要となります(図5)。
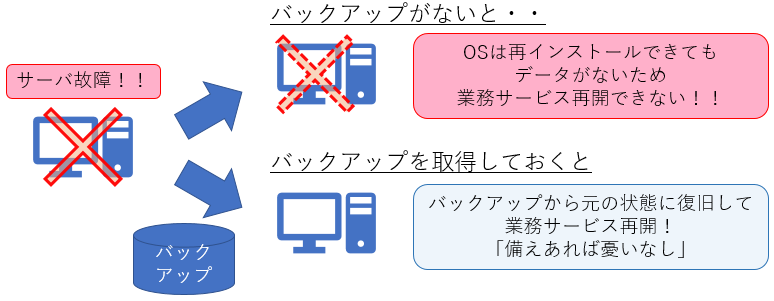
図5:バックアップとリストア
バックアップを行うには、まずバックアップ対象を確定します。システムにはアプリケーションに関連するデータも存在するため、関係各所にヒアリングをしながら決定していきます。また、対象データの更新頻度に合わせてバックアップタイミング(頻度)も決定していきます(図6)。
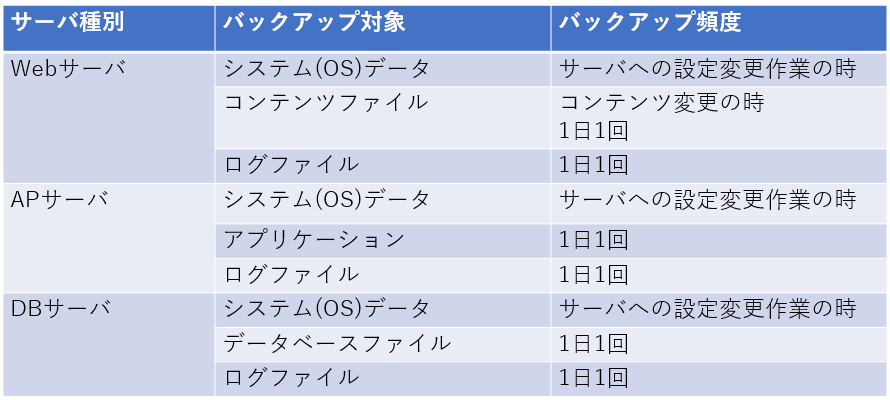
図6:バックアップ対象と頻度
バックアップに特化したミドルウェアを使用すると、操作性の向上によりバックアップ対象を集中管理できたり、バックアップやリストアの操作をGUIで実施できたり運用効率を上げることが可能となります。また、各社それぞれのオプションを使用することで、さらに運用を効率化できます。
バックアップデータの保存には別領域のディスク(DtoD)やLTO媒体(DtoT)がよく使用されています。それぞれにメリット・デメリットがあるので、要件に合わせて導入していくことになります。
バックアップにおける「バックアップ対象の状態確認」→「バックアップ先の確認」→「バックアップ」→「バックアップの成否確認」といった一連の処理はバックアップ専用ミドルウェアを介して運用者が扱いやすいひとまとまりの形となっており、これを「バックアップジョブ」と呼んでいます。実際の現場では、バックアップジョブをスケジュール実行したり、ジョブ運用ミドルウェアと連携させて実行したりすることが多くなります。
2. ジョブ運用
システムの運用中には定期的に定型作業が発生します。先述したバックアップも該当しますが、それ以外にもログの取得やサーバの再起動なども行われています。このような作業を手動で1つ1つ実行するのは大変ですし、ミスが発生する可能性も高くなるためジョブ運用が行われます。ジョブ運用ではバックアップなどの処理を実行するジョブ(実態は処理を行うスクリプトやコマンドなど)を設定し、それぞれのジョブの順序性やスケジュールを設定します(図7)。

図7:ジョブ運用イメージ
ジョブ運用により、システム運用者はジョブが正常に完了することを見届けるだけで良く、煩わしい定型作業から解放されることになります。ジョブを作成するにはシステム運用の流れを理解している必要がありますが、設定はGUIでできることも多く、運用フローを可視化していく作業となるため個人的には楽しい作業の1つです。
3. 監視
障害をいち早く検知するためには、常時システムを監視しておく必要があります。監視用ミドルウェアはさまざまな観点でシステム監視が可能ですが、多くのシステムでは下記の項目を監視しています。
-
ノード監視
サーバやネットワーク機器、ストレージやLTO装置等の機器が稼働しているかを監視します。具体的にはSNMPやICMPといったプロトコル対象機器がネットワークの中で正常に動作しているかを確認します。ノードとは、もともと「結節点」といった意味合いの言葉で、ネットワークの分野ではサーバやスイッチなどの機器を指します。 -
リソース監視
それぞれの機器のリソース使用状況を監視します。サーバであればCPU、メモリ、ディスクなどのリソースの使用状況を監視し、設定した閾値を超えた場合を異常として検知します。ディスクがいっぱいになるとそれ以上は書き込みができなかったり、メモリが枯渇しているとアプリケーションが起動できなかったり、動作が遅くなるといったことが発生します。そのような状況になる前に対処するための監視です。 -
プロセス監視
プロセスの起動状態を監視します。それぞれのアプリケーションはOS上でプロセスとして起動しています。プロセスが何らかの原因で停止した場合に異常として検知します。「サーバは起動しているが、サービスが止まっている」といった状況にならないための監視です。 -
ログ監視
OSのシステムログやミドルウェアのログを監視し、異常が出力された場合に検知します。異常がログに出力されていても気づかなければ対応が遅れます。
実際には監視ソフトウェアをインストールし、それぞれ監視対象を登録する作業が必要になります。監視ソフトには「Zabbix」「Nagios」「JP1」などの製品や製品群があります(ノード監視の製品、リソース監視の製品といった具合に分かれていることもあるため製品群と記載しています)。なお、現在ではどの製品も基本的な監視機能を備えています。CUIで設定できる(自動化に適する)、逆にGUIでの設定項目が充実している、監視コンソールの画面をカスタマイズできるなど、痒いところに手が届くような機能が追加されていますが、すべての利用者の痒いところをカバーできる製品はありません。その時々の要件に従って製品を導入することになります。
ただし、監視ソフトウェアをインストールし、設定しただけでは不十分です。システム側で異常を検出する仕組みがあっても、システム管理者が異常に気付ける仕組みがなければ、そのまま放置されてしまうからです。システム管理者にメールで通知したり、パトランプ等で別室にいる運用者に通知したりする方法や、定期的に運用者がコンソールを確認する方法などがあります。それぞれのシステム状況によって選択できる方法は変わってきます。例えばインターネット接続が許可されていないシステムでは、メール通知を実施できません(図8)。
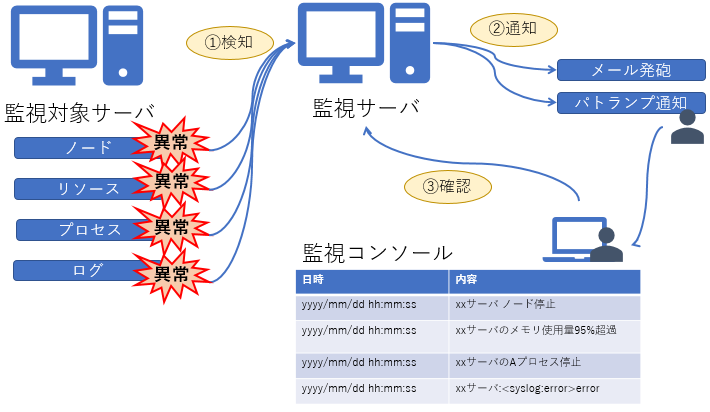
図8:監視運用のイメージ
4. 高可用性クラスタ
サーバを停止しないようにするための手段としてサーバ冗長化があります。冗長化とは一般的に「余分、余剰、冗長」といった意味ですが、システムにおいては「多重化、二重化」といった意味となります。つまり、サーバの冗長化とは「同じ機能を持つサーバを複数台用意する」ことになります。サーバ冗長化に使用されるミドルウェアが高可用性クラスタです。
冗長化すると、「サーバが不慮の障害で停止した場合」や「サーバのOS上で動作しているミドルウェア/アプリケーションが停止した場合」などに、自動で他のサーバへ切り替えて機能を提供します。平時から現用系と待機系の両系が稼働している場合を”active/active”のクラスタ構成、平時は現用系のみ機能し障害時に待機系へ切り替わる場合を”active/standby”のクラスタ構成と言います(図9)。
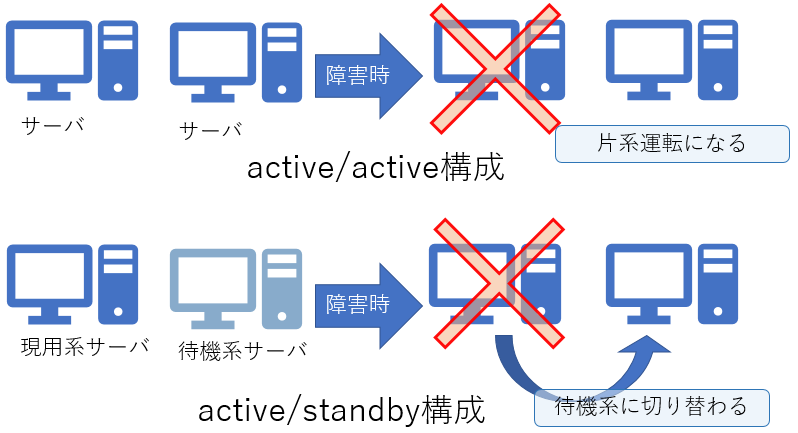
図9:高可用性クラスタ
連載を通して、インフラエンジニアが関わる「プロジェクト」に注目し、さまざまな側面から解説していく本コラム。今回は、構築とテストについて解説します。
前回のコラムで紹介した詳細設計で「何を作るか」が固まりました。次は、実際に「作る」フェーズとなります。OSやミドルウェアをインストールし、設計通りに設定していく作業が構築で、設計通りに構築されているかを確認するのがテストです。
構築では、設計書通りにサーバやストレージ、ネットワーク機器を作り上げていきます。大規模システムでは数十台~数百台、場合によっては数千台のサーバを構築することになります。それを効率的にミスなく構築することが肝となりますが、最近ではシステムの大規模化に伴い1つ1つの設定値を手入力していくのではなく、スクリプトやツールを使用した自動構築も増えてきています。
テストでは、設定値が正しいかの確認から、設計書通りの動作になっているかも確認します。システムが想定通りに動作するかを確認する”正常系テスト”と併せて”異常系テスト”も行います。例えば、障害を想定してサーバやネットワーク機器からケーブルを抜去したり、プロジェクトによってはサーバの電源モジュールを抜いたりもします。テストでは基本的に設計通りになっているかを確認するため、設計時点で間違っていたり、考慮が漏れていたりする点は拾えません。なお、最近はテストでもツールを使用した自動化が進んでいます。
(第7回へ続く)
おわりに
今回は、運用で使用するミドルウェアについて解説しました。システム利用者は「システムは利用できて当たり前」と考えています。その「当たり前」を実現するために日々システムが運用されていること、その運用のためにミドルウェアが存在し、それもインフラの領域であることを多少なりとも理解できたのではないでしょうか。
設計と運用は表裏一体です。運用を理解していないと、システムを設計できません。今後の業務や学習でさらにシステム運用に関する理解も深めていただければと思います。
次回は、「構築とテスト」をテーマに解説します。皆さんがプロジェクトに参画したとき、まず携わることが多いのが構築やテストです。構築やテストにはインフラエンジニアであれば必ず苦い思い出があるものです。そのような実体験やノウハウを紹介する予定なので、次回も楽しみにしていてください!
- この記事のキーワード
バックナンバー
この記事の筆者


Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
