はじめに
第1回では、NoSQLにおけるHBaseの位置付けとそのアーキテクチャについて解説しました。HBaseはスケールアウトが容易なアーキテクチャを持ち、高い処理性能を実現できます。しかしHBaseとRDBにはデータモデルや機能に多くの違いがあるため、RDBをそのままHBaseに置き換えることはできません。
今回は、HBaseの導入を検討する際の参考情報として、HBaseの長所と短所およびHBaseに適したユースケースを紹介します。また、HBaseを導入する際の推奨マシン/ソフトウェア構成、およびシステム設計のノウハウも紹介します。
HBase導入時の検討項目
HBaseとRDBの比較
RDBに対するHBaseの最大の利点は処理性能の高さです。しかし以下のような理由から、RDBをそのままHBaseに置き換えることはできません。
- HBaseはKVS(キーバリューストア)であり、RDBのデータモデルとは異なる
- 問い合わせ言語がSQLではない
- RDBと比べてインデクスやトランザクション等の機能が限定されている
HBaseを導入する際は長所・短所を考慮し、かつ処理内容がHBaseに適しているかを検討する必要があります。
HBaseの長所と短所
HBaseの長所を表1に、短所を表2に示します。
表1:HBaseの長所
| # | 長所 | 理由 |
|---|---|---|
| 1 | 大量のデータを管理できる | スケールアウト(スレーブノードの追加)によりディスク容量と処理性能が向上するため、大量のデータを管理できる |
| 2 | 書き込みのスループットが高い | データの書き込みをRegion間で分散処理できる。また、メモリ上のMemStoreでデータをバッファリングしてから、まとめてディスクに書き込む。これにより大量のランダム書き込みに対応できる |
| 3 | 読み出しのレイテンシが低い | データの読み出しをRegion間で分散処理できる。また、メモリ上のBlock CacheとMemStoreでデータをキャッシュでき、データ検索もブルームフィルタとインデクスにより効率的に行える |
| 4 | 可用性が高い | HBaseのマスタノードはHA構成が可能であり、スレーブノードも自動フェイルオーバが可能であるため、ノード障害が発生してもサービスがダウンしない(数秒から数十秒のダウンタイムは発生する) |
| 5 | データの永続化を保障する | データは必ずHDFS上のWrite Ahead Log(WAL)に同期書き込みするため、ノード障害が発生してもデータを復旧できる |
| 6 | データを自動的に複製する | HBaseはデータをHDFS上に保存する。HDFSはノード間でデータを複製するため、ノード障害が発生してもデータが失われる可能性は低い |
表2:HBaseの短所
| # | 長所 | 理由 |
|---|---|---|
| 1 | インデクス機能が限定されている | インデクスはRowKeyとColumnのみに限定され、セカンダリインデクスの機能はない |
| 2 | トランザクション機能が限定されている | トランザクション機能は単一のRowの内部でのみ可能であり、複数のRowやTableにまたがるトランザクションはできない。Apache OmidやApache Tephra(後述)と連携すれば複数のRowやTableにまたがるトランザクションも可能だが、性能面でのオーバヘッドがある |
| 3 | JOINなどの複雑な条件での検索はサポートしていない | HBaseはKVSであるため、複雑な条件(JOINなど)で検索する場合は複数回のアクセスが発生し、性能面でのオーバヘッドがある。また複数のRowやTableにまたがるトランザクションをサポートしていないため、データの整合性を保証できない(更新前と更新後のデータをJOINしてしまう可能性がある) |
| 4 | SQLを使用できない | HBaseはKVSであるため、キーを指定したアクセス(Getリクエスト)か、キーの範囲指定によるアクセス(Scanリクエスト)しかできない。Apache Phoenix(後述)と連携すればSQLを使用できるが、JOINなどの複雑な条件での検索には性能面でのオーバヘッドがある |
| 5 | 学習コストが高く、障害発生時の切り分けも難しい | HBaseはHDFSやZooKeeperなど依存するコンポーネントが多いため、Cassandraなど単体のOSSで完結するNoSQLと比較して学習コストが高く、障害発生時の切り分けも難しい |
| 6 | 必要なノード台数が多く、初期コストが高い | HBaseはマスタノードとスレーブノードが分かれているため、本番環境向けの冗長化構成では合計7~8台のノードが必要となる(詳細は後述の「マシン構成」を参照)。マスタノードが不要なP2P型のNoSQLと比べてノード台数が多くなるため、スレーブノード台数が少ないクラスタではコストパフォーマンスが悪い |
HBaseに適したユースケース
HBaseはキーでソートされたKVSであり、キーによるランダムアクセス(Getリクエスト)の他にキーの範囲指定によるシーケンシャルアクセス(Scanリクエスト)が可能です。そのため、キーの範囲指定がしやすい時系列に並んだデータや、連続した番号が付加されたデータの管理に適しています。また、HBaseは強い一貫性があるとされており、連続したデータの順序を保証できます。HBaseに適したユースケースと事例を以下に示します。
- メッセージングサービス
メッセージングサービス(チャット)では、ユーザのメッセージが時系列に並びます。事例としてFacebookのメッセージ機能やLINEのメッセージ機能があります。 - 履歴データの管理
システムが生成する履歴データ(データの変更履歴、操作履歴、その他システムログなど)は時刻が付加された時系列データです。事例としてSalesforceのサービスであるSalesforce Shieldがあります。このサービスの機能であるField Audit Trail(データ変更履歴などを記録)やEvent Monitoring(操作履歴などを記録)でHBaseが活用されています。
システムの推奨構成
本番環境向けのマシン/ソフトウェアの推奨構成、およびパラメータ設定を紹介します。
マシン構成
本番環境向けの推奨マシンスペックを表3に示します。
表3:推奨マシンスペック
| # | ノード | 台数 | CPU | メモリ | ディスク構成 |
|---|---|---|---|---|---|
| 1 | 運用管理サーバ | 1台 | 2コア以上 | 16GB以上 | 運2台でRAID1構成を推奨 |
| 2 | マスタノード | 3台 | 8コア以上 | 24GB以上 | OS用、HDFS NameNode用、HDFS JournalNode用、ZooKeeper用それぞれに2台でRAID1構成として、合計8台を推奨する |
| 3 | スレーブノード | 4台以上 | 8コア以上 | 32GB以上 | OS用は2台でRAID1構成、HDFS用はディスクI/Oを並列化するためになるべく多い方が良い(2台以上を推奨) |
HBaseは冗長化構成の場合マスタノードが最低3台必要となります。またHDFSのブロックはデフォルトで3台に複製されるため、スレーブノードが1台ダウンしても問題ないように4台以上のスレーブノードを推奨します。クラスタの運用管理ソフトウェアを使用する場合は、そのためのサーバ1台も必要となり、本番環境の最小構成は合計8台となります。
スレーブノードはデータの読み書き処理を行うため、データをキャッシュするためのメモリが必要です。また、データ読み書きのディスクI/Oを並列化するために、多数のディスクを搭載する必要があります。ネットワーク構成はHDFSのレプリケーションによるボトルネックを回避するため、スレーブノード間を高速な10Gbps回線で接続することを推奨します。
マスタノードはデータの読み書きにはあまり関わらないため、処理の負荷はスレーブノードほど高くありません。ただし、多数の管理プロセスが同居するためメモリを消費します。また、プロセス同士のディスクアクセスの競合を回避するため、プロセスごとに使用するディスクを分けることを推奨します(設定はマスタノードで稼働する各ソフトウェアで行います)。
安定した性能を得るため、マスタ/スレーブノードには物理マシンまたはCPU性能/ディスク性能/ネットワーク帯域の保障がある仮想マシンを使用すべきです。運用管理サーバはHBaseの処理自体には関わらないため、マスタ/スレーブノードほどの性能保証は求められていません。
以上の推奨マシン構成をまとめた構成図を図1に示します。
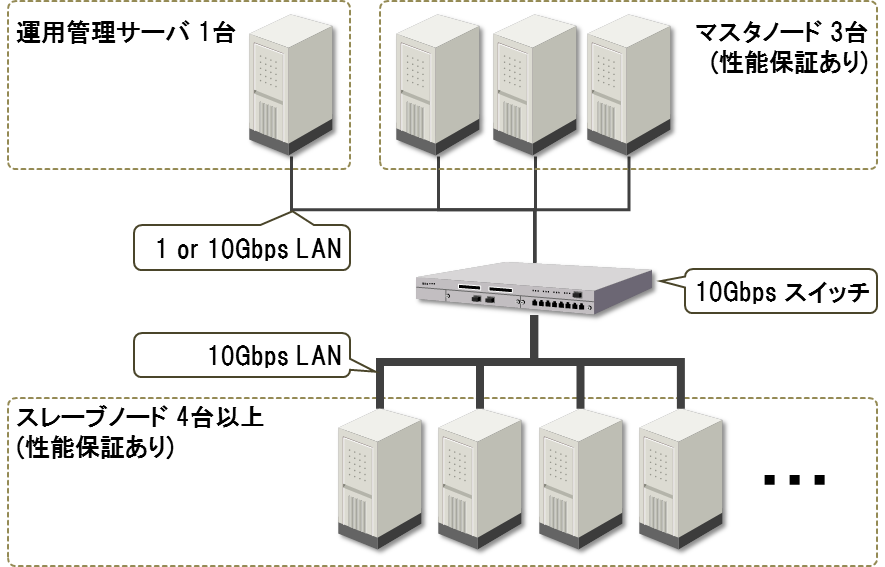
図1:推奨マシン構成
ソフトウェア構成
HBaseクラスタは複数のノードとソフトウェアで構成されるため、コミュニティ版のソフトウェアを個別に導入していくと環境構築と運用管理に手間がかかります。本連載ではCloudera社のHadoopディストリビューションであるCDH(Cloudera's Distribution including Apache Hadoop)と、その運用管理ソフトウェアであるCloudera Managerを使用します(CDHのバージョンは5.9.0、CDHに含まれるHBaseのバージョンは1.2.0)。
Cloudera Managerは手間のかかるシステム構築や、初心者には難しいパラメータチューニングなどを、ほぼ自動的に行ってくれます。また、クラスタの運用管理や性能監視をWebブラウザ上から簡単に行うことができます。なお、CDHに含まれるHBaseはコミュニティ版と比べてほぼ機能的な違いはありません。
HBaseクラスタを構築する際のソフトウェア構成を表4に示します。Cloudera Managerにおいて各ソフトウェアはロールとも呼ばれます。HBaseを使用する上でYARNは必須ではありませんが、HBase上のデータの処理にMapReduceを使用することがあるため、YARNもインストールしておくことを推奨します。
表4:ソフトウェア構成
| # | ソフトウェア名 | 説明 | インストール先 |
|---|---|---|---|
| 1 | ClouderaManager Server | クラスタの運用管理を行う。各ノードへのソフトウェア配布やパラメータ設定、性能監視などを行う | 運用管理サーバ |
| 2 | ClouderaManager Agent | ClouderaManagerはこのAgentをノードに配布してノードの操作を行う | マスタノード スレーブノード |
| 3 | HDFS NameNode | HDFSのファイル情報管理とDataNodeの監視を行う。障害に備えて2台でHA構成が可能である | マスタノード |
| 4 | HDFS DataNode | HDFSのファイルを構成するブロックを管理する。ノード障害によるデータロストを避けるためブロックはデフォルトで3台に複製する。1台がダウンしても3個の複製を保てるように、4台以上の構成を推奨する | スレーブノード |
| 5 | HDFS JournalNode | HDFSのファイルのメタデータを管理する。冗長化するには奇数台構成(3台以上)にする必要がある | マスタノード |
| 6 | YARN ResourceManager | クラスタのリソース割り当てを管理する。障害に備えて2台でHA構成が可能である | マスタノード |
| 7 | YARN NodeManager |
ResourceManagerに割り当てられたリソースでジョブを実行する。データローカリティを保つためHDFS DataNodeと同居させることを推奨する | スレーブノード |
| 8 | YARN JobHistoryServer |
YARNのジョブ実行ログを管理する。冗長化はできないため1台構成となる | マスタノード |
| 9 | HBase Master | HBaseのRegion割り当てなどを管理する。障害に備えて2台以上で冗長化可能である | マスタノード |
| 10 | HBase RegionServer | HBaseのRegionを管理する。データローカリティを保つためHDFS DataNodeとの同居を推奨する | スレーブノード |
| 11 | ZooKeeper | HBaseのメタデータなどを管理する。冗長化するには奇数台構成(3台以上)にする必要がある | マスタノード |
| 12 | ZooKeeper Failover Controller | HDFS NameNodeの自動フェイルオーバをサポートする。HDFS NameNodeと同居させる | マスタノード |
表4のソフトウェアの詳細な配置を図2に示します。この構成では最低8台のノードが必要となります。
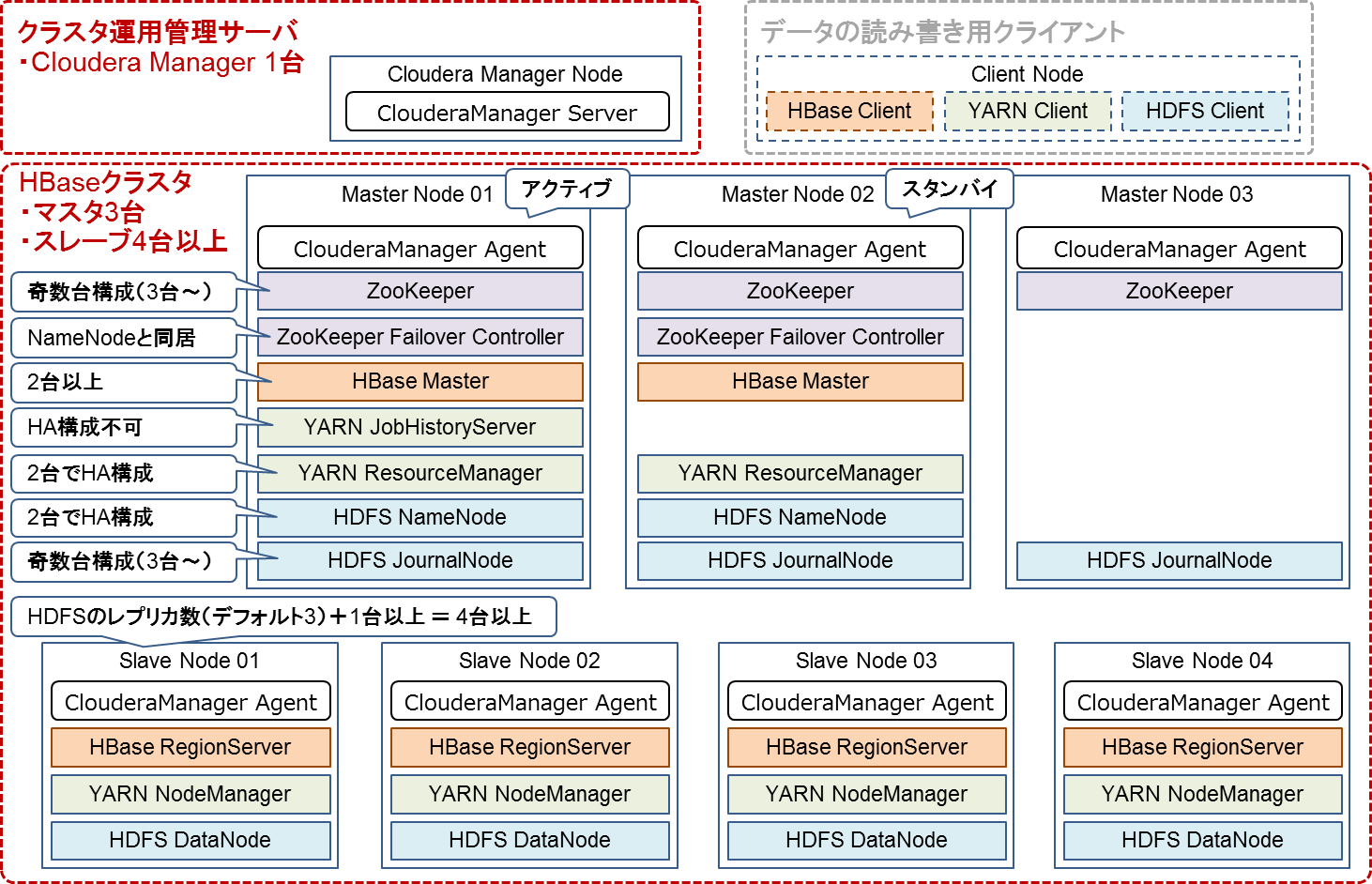
図2:本番環境の推奨ソフトウェア構成
HBaseの周辺ソフトウェア
HBaseにはSQLやトランザクション機能を提供する周辺ソフトウェアがいくつか存在します。ただし、これらのソフトウェアは開発が停止されているものも多くあります。これらのソフトウェアのうち、本連載の検証で採用したHBase 1.2.0をサポートしているものを表5に示します。
表5:HBase 1.2.0をサポートしている周辺ソフトウェア
| # | 機能 | ソフトウェア名 | 説明 |
|---|---|---|---|
| 1 | SQL | Apache Phoenix | HBaseにSQLでアクセスする機能を提供する。ただしHBaseはKVSであるため、JOINなどの複雑な条件で検索する場合は複数回のアクセスが発生し、性能面でのオーバヘッドがある。 #3のApache Tephraを取り込んでおりトランザクション機能も提供する(2017/5/11現在、トランザクション機能はベータ版である) |
| 2 | トランザクション | Apache Omid | HBaseで複数のRowやTableにまたがるトランザクションを可能にする。ただしトランザクションを管理するサーバとの通信が発生するため性能面でのオーバヘッドがある。 Tephraが未対応のRead only transactionに対応しているほか、デフォルト設定ではTephraより若干性能が良いという情報もある |
| 3 | Apache Tephra | 機能はOmidとほぼ同様。Apache Phoenixにも組み込まれている。Omidが対応していないexist / batchクエリに対応している |
推奨パラメータ設定
Cloudera Managerを使用してシステムを構築する場合、基本的なパラメータチューニングはCloudera Managerが自動的に実施してくれます。手動で設定が必要な性能チューニングについては、Cloudera社が公開しているドキュメントを参照してください。
システム設計のノウハウ
Table設計の事前準備
HBaseではTableの設計により格納/参照性能が大きく変化します。また、Tableの形式によりトランザクションの適用範囲が変化するなど機能的な違いもあるため、HBaseの性能を引き出して最大限に活用するにはTableの設計が重要となります。
HBaseでは実施したい処理(クエリ)の内容に合わせて、複数あるTable設計テクニックから適するものを選択する必要があります。そのため、設計前にどのような処理(クエリ)を実行したいのかを明確にしておく必要があります(例えばユーザ単位でメッセージを一括取得したい、カラムAとBを同時に取得したい、など)。この点がデータ中心の設計であるRDBの設計方式と大きく異なります。
Tableの設計方針
Tableの設計方針にはTall TableとWide Tableの2種類があります。Tall TableではRowを増やす方向にデータを格納していきます。一方、Wide Tableでは1個のRowの中でColumnを増やす方向にデータを格納していきます(図3)。
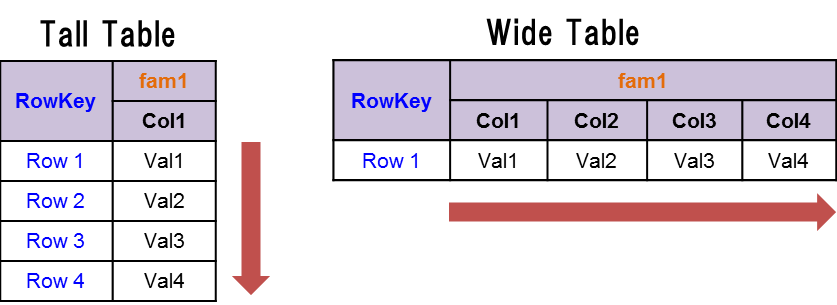
図3:Tall TableとWide Table
Tall TableとWide Tableの比較を表6に示します。Tableの設計は基本的にTall Tableで良いと言えます。ただし、Row内でのトランザクションが必要な場合はWide Tableにすべきです。
表6:Tall TableとWide Tableの比較
| # | 比較観点 | Tall Table | Wide Table | 理由 |
|---|---|---|---|---|
| 1 | Scanリクエストの実行 | ○ | × | ScanリクエストはRowKeyの範囲を指定してRowを取得するため(Columnの範囲は指定できない) |
| 2 | トランザクション | × | ○ | トランザクションは単一のRow内でのみ可能なため |
| 3 | トランザクション | ○ | × | RegionはRowKeyの範囲で分割されるため、Row内にデータを詰め込みすぎると分割単位が大きくなってしまう |
Tableの非正規化
HBaseには、RDBが持つJOINやセカンダリインデクスなどの機能がありません。そのため、これらと同等の機能を使用したい場合は、あらかじめTableの非正規化を行う必要があります。例えば、JOINしたい場合は結合済みのTableを作成しておく、セカンダリインデクスが欲しい場合は各条件でソートしたTableをそれぞれ作成しておく、といった方法でこれらの機能を実現できます。
ただし、非正規化を行う場合はデータ量が増加するだけでなく、複数のキーバリューを同時に更新する必要があるため、データの整合性をどのように管理するか考える必要があります。
Tableのインデクス
HBaseのデータはRowKeyとColumn(ColumnFamily:qualifier)にインデクスが付加されます(図4)。そのため、検索条件として使いたい値をここにマッピングすることで効率的に値を取得できます。なお、TimestampやValueでも検索は可能ですが、インデクスがないためScanの範囲が広くなってしまいます。
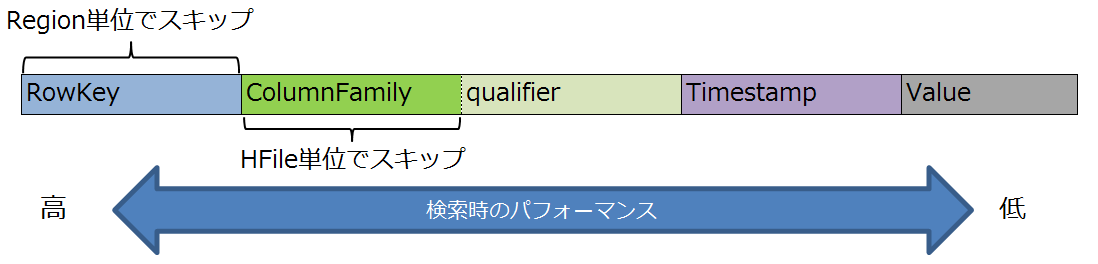
図4:Tableのインデクス
RowKeyの設計
HBaseではキーバリューがRowKeyでソートされた状態で格納されているため、ScanリクエストでRowKeyの範囲を指定することで複数のキーバリューをまとめて取得できます。HBaseではキーバリューをScanリクエストでまとめて取得できるようにRowKeyを設計する(シーケンシャルキー)ことが重要です。
ただし、シーケンシャルキーの場合は更新時に特定のRegionにアクセスが集中する現象(ホットスポット)が発生しやすいため、更新処理の内容によってはRowKeyが分散するように設計(ランダムキー)すべき場合もあります。RowKeyの主な設計手法を以下に示します。
-
タイムスタンプ/リバースタイムスタンプ
時系列でデータをソートしたい場合に、RowKeyの一部にタイムスタンプを設定します。古い順にソートしたい場合はそのまま設定し、新しい順にソートしたい場合はリバースタイムスタンプ(例えばJavaのLong型の最大値からタイムスタンプを減算したもの)を設定します。Columnを時系列にソートしたい場合も同様に可能です。 -
リバースドメイン
反転したドメインをRowKeyとします。共通のドメインを持つRowが並ぶため、Scanリクエストで共通のドメインを持つデータをまとめて取得できます。例)
反転前のドメイン:www.hitachi.co.jp
反転後のドメイン:jp.co.hitachi.www -
ハッシュ付与
RowKeyの先頭にハッシュ値を付加します。Region間でデータを分散させたい場合に有効ですが、ソートして取得することができません。 -
ソルト
RowKeyの先頭にソルトと呼ばれる任意の文字や数字を付加します。ソルトの種類はRegionServer数以上にする必要があり、データをRegionServer単位で均等に分散したい場合に適しています。例えばRegion数が3個の場合、ソルトとしてRowKeyの先頭に1、2、3を付与します。これによりRowKeyの先頭が1の場合はRegion1、2の場合はRegion2、というように分散して保存されます。ソルトはデータを分散させたい場合に有効ですが、ソートして取得することができません。 -
フィールド入れ替え
RowKeyの中に分散させやすいフィールドがある場合、そのフィールドを先頭に持ってきます。Columnに分散させやすいフィールドがある場合も同様に可能です。例)
入れ替え前のRowKey:00001-AAAAA-server1
入れ替え後のRowKey:AAAAA-00001-server1
Columnの設計
ColumnはColumnFamilyとQualifierで構成されますが、特にColumnFamilyの設計がポイントになります。ColumnFamily設計時の注意点を以下に示します。
-
同時にアクセスするColumnは同じColumnFamilyに所属させる
同じRowKeyで異なるColumnFamilyのデータは異なるStoreに格納されるため、出力先のHFileも別々となります。同時にアクセスするQualifierを同じColumnFamilyにすることで、アクセス時は特定のHFileのみを読み込めば良いため、ディスクI/Oやフィルタリング処理を削減できます。逆にアクセスパターンが全く異なるQualifierの場合はColumnFamilyを分けるべきです(メタデータと実データ、日次データと週次データなど)。 -
1個のTableに対してColumnFamilyは最大3個までにする
MemStoreのFlushやCompactionはRegion単位で行われます。そのため、ColumnFamilyが複数存在し、そのうちの1個のColumnFamilyが大量のデータを保持している場合、他のColumnFamilyが保持するデータが少量でも同様にFlushされます。これにより不必要なディスクI/Oが発生する恐れがあるため、ColumnFamilyは多くても2、3個にするべきです(参考[https://hbase.apache.org/1.2/book.html#number.of.cfs])。
Region数の決定方法
HBaseのRegionはデフォルト設定だと一定のサイズに達した場合に自動分割されます。そのため、データ量が徐々に増加する場合、はじめはRegionが分割されず、特定のサーバにデータが偏ってしまいます。これを避けるために、Table作成時にRegionを事前分割しておくことが望ましいです。
HBaseはTableをRegionに分割してスレーブノードに割り当てることでTableへのアクセスを分散処理します。TableのRegion数が少なすぎるとスレーブノードのマシンリソースを使い切れず、十分な性能を発揮できません。しかし、Region数が多すぎると処理が細かく分割されるため、オーバヘッドが大きくなってしまいます。
適切なRegion数はマシンリソース(スレーブノード台数、CPUコア数、ディスク台数)だけでなく、1RegionのサイズやMemStoreのフラッシュサイズにも影響されます。HBaseの公式ドキュメントに記載されている適切なRegion数に関する情報を表7に示します。
表7:適切なRegion数/Regionサイズ/MemStoreのフラッシュサイズ
| # | 項目 | 適切な数/サイズ |
|---|---|---|
| 1 | Region数 | 1RegionServerあたり20~200個 |
| 2 | 1Regionのサイズ | 適切:5-10GB、最大:10-20GB (hbase.hregion.max.filesizeで設定。デフォルト10GB) |
| 3 | MemStoreのフラッシュサイズ | 128~256MB (hbase.hregion.memstore.flush.sizeで設定。デフォルト128MB) |
以下に、これらの情報をもとにしたRegion数の決定方法を2種類示します。
(1)メモリ量からRegion数を決定する方式
HBaseはRegionServerが使えるメモリ量のうち、一定の割合をMemStoreに割り当てます。また、各RegionはColumnFamily数と同数のMemStoreを持っており、各MemStoreのフラッシュサイズは固定です。そのため、MemStoreに割り当てたメモリを使い切るためには、それに応じた数のMemStore(を持つRegion)を作成する必要があります。この考え方によるRegion数の計算方法を図5に示します。

図5:メモリ量からRegion数を決定する計算方法
例えば、1RegionServerのメモリ量(Javaヒープサイズ)が31GB、MemStoreへのメモリ割当率が40%(デフォルト値)の場合、MemStoreへのメモリ割当量は12.4GBとなります。RegionServerが4台、MemStoreのフラッシュサイズが128MB(デフォルト値)、ColumnFamily数が1個の場合、Region数は4×12.4GB÷(128MB×1)≒400個となります。
(2)データサイズからRegion数を決定する方式
表7に示した通り、1Regionの適切なサイズは5~10GBとされています。そのため、適切なサイズのRegionを全データが収まる個数だけ作成することでRegion数を決定できます。この考え方によるRegion数の計算方法を図6に示します。

図6:データサイズからRegion数を決定する計算方法
例えば、Tableの総データサイズが4,000GB、1Regionのサイズを10GBとすると、Region数は4,000GB÷10GB=400個となります。
おわりに
今回はHBase導入時の検討項目とシステムの推奨構成、および設計ノウハウを紹介しました。HBaseはRDBとデータモデルが異なり、時系列に並んだデータや連続した番号が付加されたデータの管理に適しています。また、Tableの設計により性能や使える機能の範囲が変化するため、Tableの設計が重要となります。
次回からは、センサ機器が生成するような1,000万個にもおよぶ時系列のスマートメータ(次世代電力計)のデータを管理するシステムを想定した、HBaseの性能検証結果を紹介します。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
