スマートメータのデータを用いたHBaseの性能検証(前編)
2017年6月22日 0:15
はじめに
前回はHBase導入時の検討項目とシステムの推奨構成、および設計ノウハウを紹介しました。HBaseはRDBとデータモデルが異なり、時系列に並んだデータや連続した番号が付加されたデータの管理に適しています。また、Tableの設計により性能や使える機能の範囲が変化するため、Tableの設計が重要となります。
今回からはHBaseの性能検証結果を紹介します。HBaseはセンサ機器が生成するような時系列データの管理に適していると考えられます。そこで、1,000万個のスマートメータ(次世代電力計)のデータを管理するシステムを想定した性能検証を行いました。今回はその検証のシナリオと、データの格納性能の検証結果を紹介します。
検証シナリオ
シナリオ:スマートメータのデータを使用した性能検証
検証のシナリオとして、スマートメータから収集したデータの管理システムを想定します。スマーメータとは、電力事業者によって住宅や店舗などに設置され、電力消費量などのデータを自動収集する機器です。各メータは収集したデータを30分ごとにメータデータ管理システムに送信します。メータデータ管理システムに蓄積されたデータは料金計算や電力需要の予測分析などに利用されます。本検証では、1,000万個のスマートメータがあると想定します(図1)。
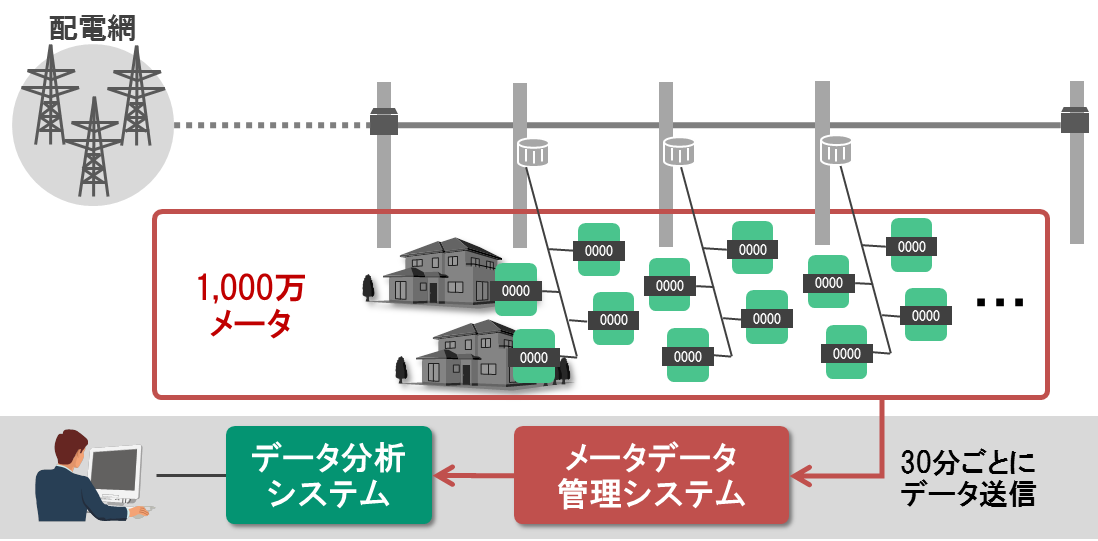
図1:HBase性能検証のシナリオ
本検証で想定するシステム構成を図2に示します。このシステムでは、1,000万個のスマートメータが30分ごとに送信してくるデータを一旦ゲートウェイサーバでキューイングします。そして、そのデータをある程度まとめてからHBaseに格納します。HBaseに格納されたデータは、不定期に分析システムから参照されます。
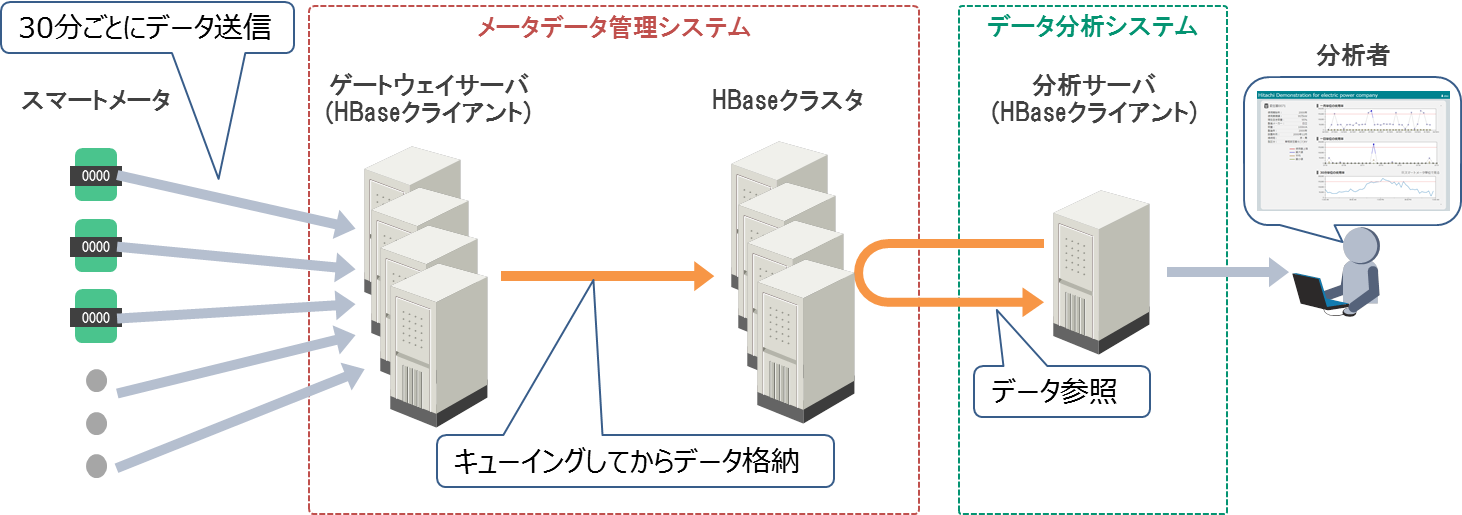
図2:想定するシステム構成
本来、メータデータには電力消費量以外にも様々なデータを含みますが、本検証では扱うデータを簡略化し、メータID、日付と時刻、電力消費量の3種類のみとします。具体的なデータ構造は、後述の「Table設計」の項で解説します。
検証項目
本検証の検証項目は、HBaseの格納性能、データ圧縮性能、参照性能の3点です。各検証項目の概要を以下に示します。
- (1)格納性能
1,000万件のレコードの格納時間(レスポンスタイム)と格納スループット(1秒あたりの格納レコード数)を計測しました。ゲートウェイサーバで1,000万件のレコードを生成し、HBaseクラスタに格納リクエストを行いました。なお、この測定ではデータの圧縮をしていません。 - (2)圧縮性能
1,000万件のレコードのデータの圧縮率と格納時間(圧縮時間を含む)、参照時間(解凍時間を含む)を測定しました。 - (3)参照性能
2種類の参照ユースケースにおいて、取得時間(レスポンスタイム)とスループット(1秒あたりの取得レコード数)を測定しました。この測定では事前に1,000万メータの6ヵ月分の時系列データをHBaseクラスタに格納しています。このデータは(2)の検証結果を元に圧縮済みで、分析サーバはこのデータへ参照リクエストを行います。
以上の各検証項目とシステムの対応関係を図3に示します。
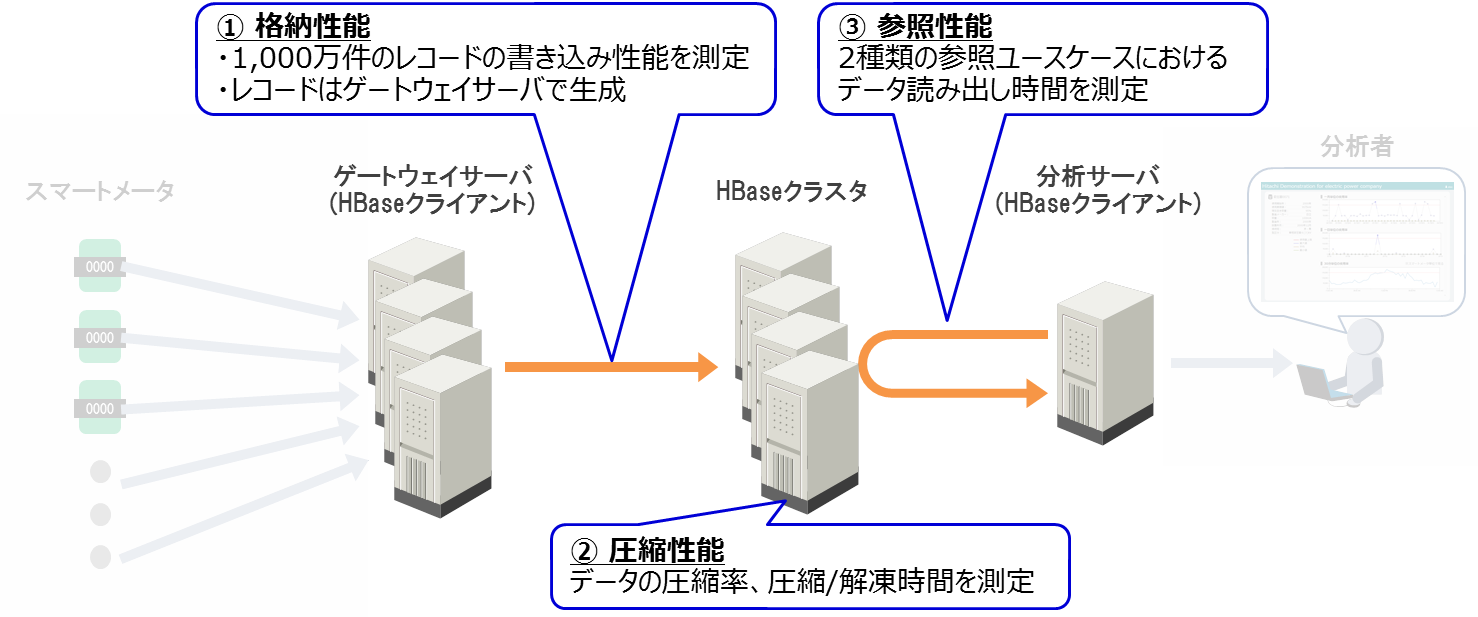
図3:検証項目とシステムの対応関係
検証環境
検証環境のマシンスペックを表1に示します。今回は性能検証であるため、マスタノードの冗長化は実施していません。また、スレーブノード間はHDFSのレプリケーションによるボトルネックを回避するため、高速な10G回線で接続しました。
表1:検証環境のマシンスペック
| # | ノード | 種別 | 台数 | CPU | メモリ | ディスク台数 |
|---|---|---|---|---|---|---|
| 1 | 運用管理サーバ (Cloudera Manager用) | 仮想 | 1台 | 2コア | 16GB | 1台 |
| 2 | クライアントノード | 仮想 | 1台 | 16コア | 12GB | 1台 |
| 3 | マスタノード | 仮想 | 1台 | 2コア | 16GB | 1台 |
| 4 | スレーブノード | 物理 | 4台 | 32コア | 128GB | OS用:2台でRAID1構成 HDFS用:6台(JBOD構成) |
パラメータ設定
パラメータ設定は、Cloudera Managerが自動設定した値をベースとして、検証項目に合わせてチューニングを行いました。デフォルト設定から手動で変更したOSのパラメータを表2に示します。表内の[デフォルト値]とはOSのデフォルト値を示しています。
表2:手動設定したOSのパラメータ設定
| # | 設定項目 [パラメータ名] | 設定値 [デフォルト値] |
|---|---|---|
| 1 | スワップ頻度 [設定ファイル:/etc/sysctl.conf, パラメータ名vm.swappiness] | 1 [60] |
| 2 | Transparent Hugepage Compaction [パラメータ名:/sys/kernel/mm/redhat_transparent_hugepage/defrag] | Never [always] |
スワップ頻度(表2#1)は0~100の範囲で設定し、数値が高いほど積極的にスワップを利用します。データが物理ディスクに格納されている状態でJVMのFull GCが発生すると、GC対象のオブジェクトを探すためにディスクアクセスが頻発するため、スワップ頻度を抑えました。Transparent Hugepage Compaction(表2#2)は、有効にすると処理中にsystemのCPU使用率が高騰する場合があるため、無効化しました。
これら設定の詳細については、Cloudera社が公開しているドキュメントを参照してください。
HBaseとHDFSの主要なパラメータ設定を表3、表4に示します。表内の[デフォルト値]とはCloudera Managerが設定したデフォルト値を示しています。
今回の検証ではHBaseクラスタにマルチクライアント/マルチスレッドでアクセスするため、RegionServerハンドラカウント(表4#7)をデフォルト設定から増やしています。また一度に大量のデータを送信できるように、Clientの送信バッファサイズ(表4#11)も増やしています。
また、参照性能を正しく測定するため必ずディスクからデータを読み出すようにキャッシュを無効化(表3#4、表4#4)し、MemStoreも全てフラッシュしました。測定前には毎回全ノードのOSページキャッシュをクリアしました。他にも、バックグラウンドで実行されると性能への影響が大きいメジャーコンパクション(表4#9)を無効化しています。
表3:HDFSの主要なパラメータ設定
| # | 設定項目 [パラメータ名] | 設定値 [デフォルト値] |
|---|---|---|
| 1 | ブロックサイズ [dfs.blocksize] | 128MB [128MB] |
| 2 | ブロックのレプリカ数 [dfs.replication] | 3個 [3個] |
| 3 | Short-Circuit Local Reads [dfs.client.read.shortcircuit] | True [True] |
| 4 | キャッシュに使用する最大メモリ [dfs.datanode.max.locked.memory] | 0(無効化) [4GB] |
表4:HBaseの主要なパラメータ設定
| # | 設定項目 [パラメータ名] | 設定値 [デフォルト値] |
|---|---|---|
| 1 | RegionServerのJavaヒープサイズ [RegionServerのJVMオプション(-Xmx)に指定] | 31GB [31GB] |
| 2 | MemStoreへのメモリ割当率 [hbase.regionserver.global.memstore.size] | 0.4 [0.4] |
| 3 | MemStoreのフラッシュサイズ [hbase.hregion.memstore.flush.size] | 128MB [128 MB] |
| 4 | Block Cacheへのメモリ割当率 [hfile.block.cache.size] | 0(無効化) [0.4] |
| 5 | Bucket Cacheの動作モード [hbase.bucketcache.ioengine] | なし [なし] |
| 6 | Bucket Cacheのサイズ [hbase.bucketcache.size] | 0 [0] |
| 7 | RegionServerハンドラカウント [hbase.regionserver.handler.count] | 130 [30] |
| 8 | Storeの最大サイズ [hbase.hregion.max.filesize] | 10GB [10GB] |
| 9 | メジャーコンパクションの実行間隔 [hbase.hregion.majorcompaction] | 0日(無効化) [7日] |
| 10 | Client(HBase Java APIを使用する検証用クライアントアプリ)のJavaヒープサイズ [ClientのJVMオプション(-Xmx)に指定] | 10GB [なし] |
| 11 | Clientの送信バッファサイズ [hbase.client.write.buffer] | 32MB [2MB] |
Table設計
TableのRegion数は、前回の「Region数の決定方法」で説明した「メモリ量からRegion数を決定する方式」で決定し、400個(1RegionServerあたり100個)を初期値としました。
Table設計を図4に示します。本検証ではトランザクションが不要なため、Rowを増やす方向にデータを格納していくTall Table方式を採用しました(Tall TableとWide Tableの違いは前回の「Tableの設計方針」を参照)。また、データをRegion間で分散するため、RowKeyの先頭にはRegion番号(0000-0399)と同じソルトを付加しました(ソルトの説明は前回の「RowKeyの設計」を参照)。RowKeyはソルト、メータID、日付、時刻で構成し、ColumnFamily名はCF、Qualifier名は空白、Valueは電力消費量です。
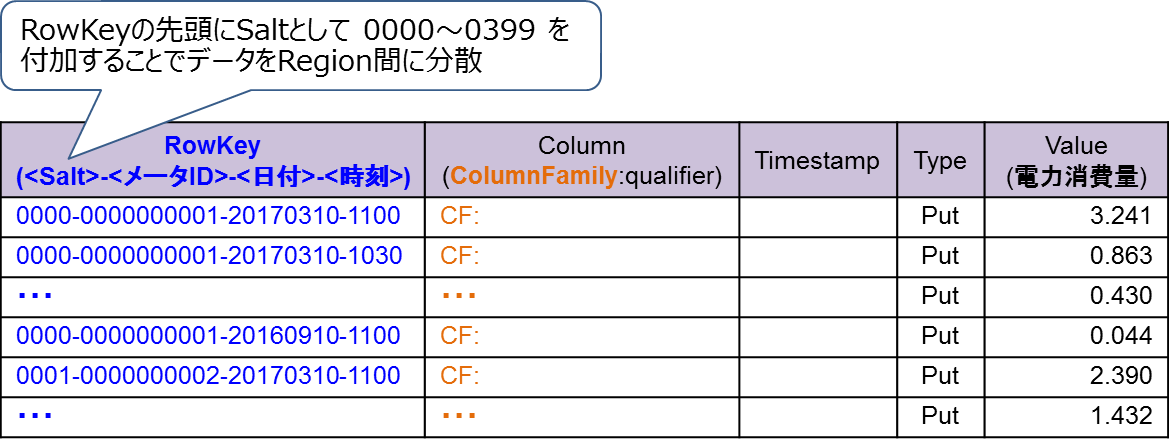
図4:Table設計
格納性能の検証
検証内容
HBase ClientとRegionServerのパラメータチューニングを行い、1,000万件のレコードの格納時間と格納スループット(1秒あたりの格納レコード数)を測定しました。この測定では複数のリクエストをまとめて実行するBatchリクエストを使用し、複数のPutリクエストをまとめて送信しました。これにより1リクエストで複数のレコードを送信できます。また、本検証ではマルチクライアント環境を想定して、複数のクライアントから並列にBatchリクエストを送信しました。格納性能の検証の概要を図5、格納性能の検証でチューニングしたパラメータを表5に示します。

図5:格納性能の検証の概要
表5:格納性能のチューニングパラメータ
| # | チューニング対象 | チューニングするパラメータ | パラメータ設定 |
|---|---|---|---|
| 1 | Client | 送信クライアント数 | 1、4、8、16、32、64、128 |
| 2 | 1リクエストあたりの送信レコード | 1、10、100、1,000、10,000、100,000 | |
| 3 | RegionServer | Region数 | 20、100、200、400、800、1,600 |
検証結果と考察
(1)Clientのパラメータチューニング結果
Region数を400に固定し、送信クライアント数と1リクエストあたりの送信レコードを変動させたときの格納時間と格納スループットを図6に示します。この検証では格納レコード数が一定のため、格納時間と格納スループットは反比例します。
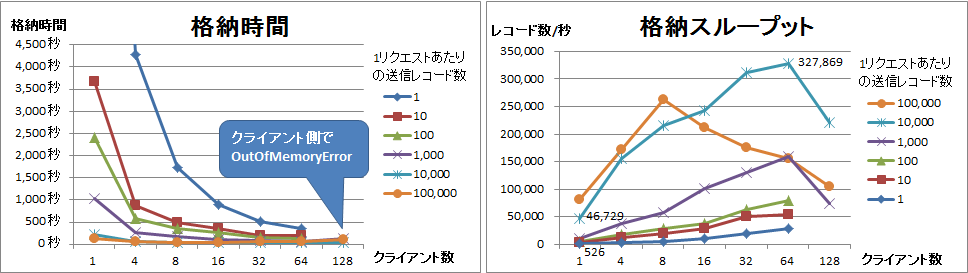
図6:Clientチューニング時の格納時間と格納スループット
送信クライアント数と1リクエストあたりの送信レコードが多いほど格納時間は短くなり、格納スループットは高くなる傾向がありました。ただし、今回は128クライアント以上だと一部のケースではクライアントマシンのメモリ不足により測定できませんでした。そのため、クライアントマシンの性能によっては、さらに格納性能が向上する可能性があります。
1リクエストあたりの送信レコードを1から10,000まで増やすと、格納スループットは526レコード/秒から46,729レコード/秒まで約89倍向上しました。これはリクエスト数が減るため、当然の結果といえます。1リクエストあたりの送信レコードを10,000で固定して送信クライアント数1から64まで増やすと、格納スループットは46,729レコード/秒から327,869レコード/秒まで約7倍向上しました。つまり、HBaseはマルチクライアント環境で性能を発揮するといえます。
結果として、送信クライアント数が64、1リクエストあたりの送信レコードが10,000のときに格納スループットは最も高い327,869レコード/秒となりました。
(2)RegionServerのパラメータチューニング結果
次に、1リクエストあたりの送信レコードを10,000で固定して、送信クライアント数とRegion数を変動させて測定を行いました。この測定における格納時間と格納スループットを図7に示します。この検証では格納レコード数が一定のため、格納時間と格納スループットは反比例します。

図7:RegionServerチューニング時の格納時間と格納スループット
送信クライアント数が少ない場合は、Region数が少ない方が格納時間は短くなり、格納スループットは高くなる傾向がありました。ただし、送信クライアント数が増えてくるとその差は縮まり、逆転することもありました。特に、最も少ない20Regionでは送信クライアント数が8のとき最も格納スループットが高く、それ以上増やすと逆にスループットが下がってしまいました。よって、同時アクセス数が増加するとある程度のRegion数が必要になると考えられます。
結果として、送信クライアント数64のときRegion数を400から200に減らすことで、格納スループットは327,869レコード/秒から384,615レコード/秒まで約17%向上しました。ただし、前回「Region数の決定方法」で説明した通り、Region数は他の要因も考慮して決めるべきであり、必ずしも性能だけで決めるべきではありません。
おわりに
今回はスマートメータのデータを用いた性能検証のシナリオと、HBaseの格納性能の検証結果を紹介しました。格納性能の検証では、送信クライアント数を増やすことで格納スループットが約7倍向上しました。つまり、HBaseはマルチクライアント環境で性能を発揮するといえます。
次回は、HBaseの圧縮性能と参照性能の検証結果を紹介します。また、本検証のまとめとして、検証を通して得られたノウハウを紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
