スマートメータのデータを用いたHBaseの性能検証(後編)
2017年7月6日 0:15
はじめに
前回はスマートメータのデータを用いた性能検証のシナリオと、HBaseの格納性能の検証結果を紹介しました。格納性能の検証では、送信クライアント数を増やすことで格納スループットが約7倍向上することを確認できました。つまりHBaseはマルチクライアント環境で性能を発揮すると言えます。
今回は、データの圧縮性能と参照性能の検証結果を紹介します。データ圧縮性能の検証では、データの圧縮率と圧縮/解凍にかかる時間を測定しました。参照性能の検証では、データ参照のユースケースとして電力消費量の可視化を行うと仮定し、これに必要なクエリの処理性能を測定しました。また、最後にまとめとして検証を通して得られたノウハウを紹介します。
圧縮性能の検証
HBaseの圧縮設定
HBaseはキーバリューストアであり値ごとにキーが付くため、レコード数が増えやすい傾向があります。またキーがRowKeyやColumn、Timestampなどの要素で構成されるため1つのキーが長くなり、データ量が大きくなりやすいと言えます。
そこで、HBaseではデータ圧縮の設定が重要となります。HBaseには表1に示す2種類の圧縮設定があり、これらの設定を組み合わせてデータを圧縮します。
表1:HBaseの圧縮設定
| # | 圧縮の設定 | 説明 |
|---|---|---|
| 1 | エンコーディング | HFileのデータブロック(キーバリューが格納されるブロック)部分をエンコードする。キーは似たような値が連続するため、共通部分をうまく省略することでキーを短縮できる |
| 2 | 圧縮アルゴリズム | HFile全体をブロック単位で圧縮する |
エンコーディングの設定を表2、圧縮アルゴリズムの設定を表3に示します。
表2:エンコーディング
| # | エンコーディング | 説明 |
|---|---|---|
| 1 | PREFIX | RowKeyとColumnを圧縮する |
| 2 | PREFIX_TREE | PREFIXと同じくRowKeyとColumnを圧縮するが、よりBlock Cacheのヒット率が高いアプリケーションに適している |
| 3 | DIFF | RowKeyとColumnに加えTimestampなども圧縮する |
| 4 | FAST_DIFF | DIFFと同じくRowKeyとColumnに加えTimestampなどを圧縮するが、より長い値に対して圧縮率が高い |
表3:圧縮アルゴリズム
| # | 圧縮アルゴリズム | 説明 |
|---|---|---|
| 1 | SNAPPY | 圧縮/解凍速度を重視 |
| 2 | GZ(GZIP) | 圧縮率を重視 |
| 3 | LZ4 | 圧縮/解凍速度を重視 |
| 4 | LZO | 圧縮/解凍速度を重視。追加のライブラリのインストールが必要 |
データを圧縮するとディスク使用量とディスク/ネットワークのI/O量は減少しますが、圧縮/解凍処理によりCPU負荷が増加します。そのため、CPUコストとディスク/ネットワークコストのバランスを考える必要があります。従来はCPUの性能向上ペースが大きい一方、ディスクやネットワークのI/O性能はあまり進歩していなかったため、圧縮によるデータ量の削減が有効でした。しかし、現在はI/O速度の速いSSDの価格低下によりコストのバランスが変化してきており、物理構成や価格も考慮する必要があると思われます。
また、どのエンコーディングと圧縮アルゴリズムが高い効果を発揮するのかは、データ形式やデータサイズ、リクエスト内容など様々な要因に左右されます。そのため、事前に各圧縮設定の組み合わせを試し、データの圧縮率とデータの更新/参照にかかる時間の増減を確認しておくことを推奨します。
検証内容
1,000万レコードを圧縮/解凍し、圧縮アルゴリズムとエンコーディングの性能を検証しました。検証項目を表4、測定時のパラメータ設定を表5に示します。格納リクエストの送信クライアント数(表5#1)と1リクエストあたりの送信レコード数(表5#2)は、前回の「格納性能の検証」で得られた最適値を使用しました。Region数(表 5#4)は前回の「Table設計」で決めた初期値を使用しました。なお、圧縮アルゴリズムLZOは追加のライブラリが必要なため、今回は検証の対象外としました。
表4:圧縮性能の測定内容
| # | 検証内容 | 測定方法 |
|---|---|---|
| 1 | HFileのファイルサイズ(圧縮率) | 1,000万レコード格納後の全HFileの合計サイズを測定。圧縮率は圧縮後サイズ÷圧縮前サイズで算出 |
| 2 | 格納時間(圧縮時間) | 空のTableに1,000万レコードをPutリクエストで格納したときの時間(圧縮時間を含む)を測定 |
| 3 | 参照時間(解凍時間) | 1,000万レコードを格納済みのTableに全レコードを1回のScanリクエストで取得したときの時間(解凍時間を含む)を測定 |
表5:パラメータ設定
| # | チューニング対象 | 測定対象 | チューニングするパラメータ | パラメータ設定 |
|---|---|---|---|---|
| 1 | Client | 格納性能 | 格納リクエストの送信クライアント数 | 64 |
| 2 | 1リクエストあたりの送信レコード数 | 10,000 | ||
| 3 | 参照性能 | 参照リクエストの送信クライアント数 | 1 | |
| 4 | RegionServer | 格納/参照性能 | Region数 | 400 |
検証結果
エンコーディングの検証結果
各エンコーディングの検証結果を図1に示します。各グラフの一番上がエンコーディングなしの場合の結果です。一番下に赤いバーで示したDIFFエンコーディングを適用した場合のファイルサイズが最も小さい311MBになりました(圧縮率53%)。このとき、格納時間は31秒から46秒まで48%増加し、参照時間は45秒から43秒まで3%減少しました。

図1:エンコーディングの性能
圧縮アルゴリズムの検証結果
各圧縮アルゴリズムの検証結果を図2に示します。各グラフの一番上が圧縮アルゴリズムなしの場合の結果です。一番下に赤いバーで示したGZアルゴリズムを適用した場合のファイルサイズが最も小さい126MBになりました(圧縮率22%)。ただし、格納時間は31秒から45秒まで44%増加し、参照時間も45秒から52秒まで17%増加しました。
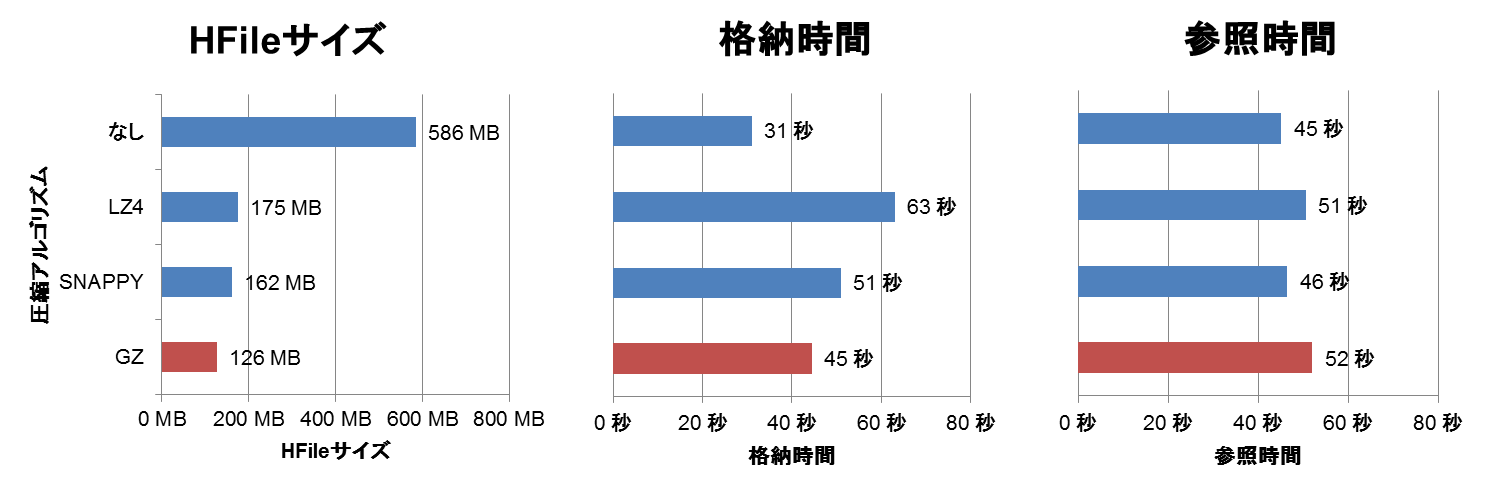
図2:圧縮アルゴリズムの性能
エンコーディング+圧縮アルゴリズムの検証結果
エンコーディングと圧縮アルゴリズムを組み合わせた際の検証結果を図3に示します。各グラフの一番上がエンコーディングと圧縮アルゴリズム共になしの場合の結果です。一番下に赤いバーで示したDIFFエンコーディング+GZアルゴリズムを適用した場合のファイルサイズが最も小さい110MBになりました(圧縮率19%)。ただし、格納時間は31秒から51秒まで63%増加し、参照時間も44秒から52秒まで17%増加しました。
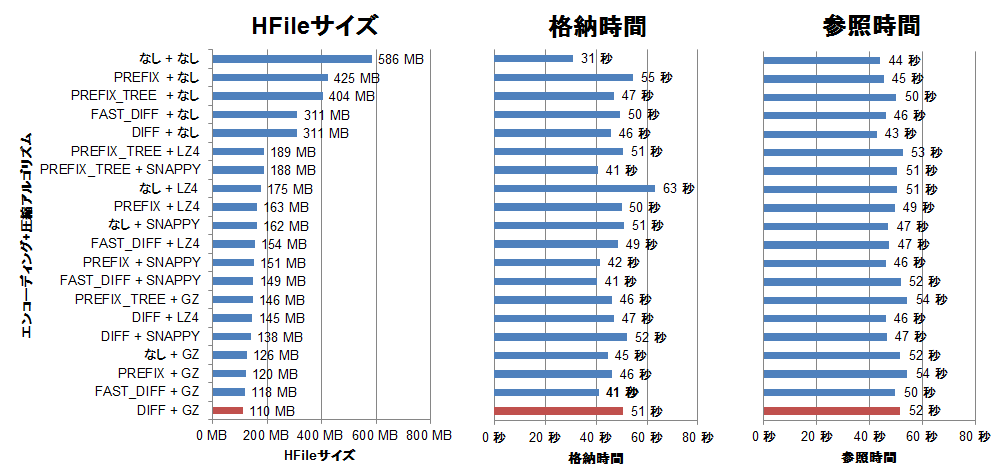
図3:エンコーディングと圧縮アルゴリズムの性能
検証結果の考察
今回の検証では、単体だとDIFFエンコーディングとGZアルゴリズムの圧縮率が最も高く、組み合わせた場合も同様でした。ただし、格納時間と参照時間は増加するため、何を重視するかによって採用するエンコーディングと圧縮アルゴリズムを選択すべきです。今回の検証で圧縮率、格納時間、参照時間の各指標について分かったことを表6に示します。
表6:圧縮設定の検証で分かったこと
| # | 指標 | 分かったこと |
|---|---|---|
| 1 | 圧縮率 | 圧縮率は高い(72%~19%まで圧縮) |
| 2 | 格納時間 | 圧縮すると格納時間は大きく増加する(+31%~+103%) |
| 3 | 参照時間 | 圧縮しても参照時間はそれほど増加しない。 設定によっては減少することもある(-3%~+23%) |
では、総合的に考えてどの圧縮設定が一番良いのでしょうか。HFileサイズの増減率(圧縮率-1.00で算出)と格納時間/参照時間の増減率を合計したとき、減少率の大きい順にソートした結果を図4に示します。総合的なバランスを考えて参照性能重視ならPREFIX+SNAPPY(図4#1)、圧縮率重視ならFAST_DIFF+GZ(図4#2)が良いことが分かりました。
また、圧縮率のみを重視する場合はDIFF+GZ(図4#13)、格納性能のみを重視する場合は圧縮設定なし(図4#14)、参照性能のみを重視する場合はDIFFのみ(図4#11)が良いと言えます。
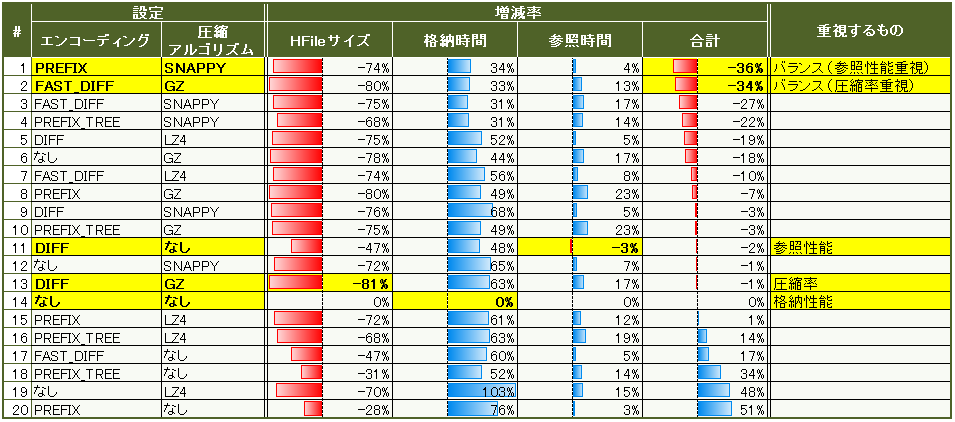
図4:HFileサイズ、格納時間、参照時間の増減率
なお、今回の検証内容ではこれらの設定の組み合わせが高い効果を発揮しましたが、どのエンコーディングと圧縮アルゴリズムが高い効果を発揮するのかは、データ形式やデータサイズ、リクエスト内容など様々な要因に左右されます。
参照性能の検証
検証内容
参照性能の検証では、電力消費量の可視化に必要なデータを取得するクエリを実行して性能を測定しました。参照性能の検証の概要を図5に示します。

図5:参照性能の検証
測定時にチューニングしたパラメータを表7に示します。この検証では、参照クエリはマルチスレッドで実行しました。
表7:参照性能のチューニングパラメータ
| # | パラメータ | パラメータ設定 |
|---|---|---|
| 1 | 送信スレッド数 | 1、5、10、25、50、100 |
参照クエリとデータセット
参照クエリの内容と想定する電力消費量の可視化ユースケースを表8に示します。このクエリを実行して参照時間(レスポンスタイム)と参照スループット(1秒当たりの取得レコード数)を測定しました。
表8:参照クエリの内容と想定するユースケース
| # | 参照クエリの内容 | 取得メータ数 | 取得期間 | 想定するユースケース |
|---|---|---|---|---|
| 1 | クエリ1: 少数のメータの時系列の電力消費量を取得 (Scanリクエストを使用) | 1 10 100 | 1日(48レコード) 30日(1,440レコード) 180日(8,640レコード) | 各メータの電力消費量の推移をチャートに表示 |
| 2 | クエリ2: 多数のメータの最新時刻の電力消費量を取得 (Getリクエストを使用) | 1万 10万 100万 1,000万 | 30分(1レコード) | 直近の電力消費量の合計値や平均値を計算 |
クエリ1ではScanリクエストを使用しました。TableのデータをScanリクエストで取得する様子を図6に示します。Tableのデータはソルト、メータID、日付、時刻の順でソートされています。そのため各メータの時系列データはHFile上の連続した位置に格納されており、同一メータの時系列データはScanリクエストでまとめて取得できます。
また、このクエリでは1メータあたり1回のScanリクエストが必要です。例えば、100メータの時系列データを取得する場合は100回のScanリクエストを発行する必要があります。
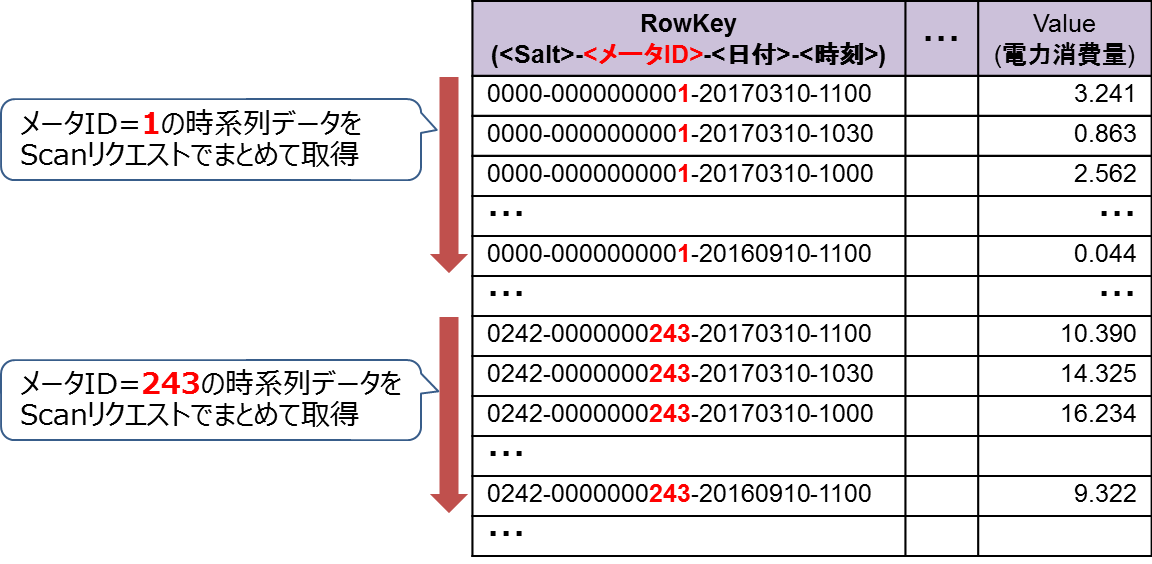
図6:クエリ1はScanリクエストでシーケンシャルアクセス
クエリ2ではGetリクエストを使用しました。これはキーの並び上、各メータの最新の電力消費量はScanリクエストでまとめて取得できないためです。TableのデータをGetリクエストで取得する様子を図7に示します。各メータの最新時刻のデータはHFile上で離れた位置に格納されているため、データの取得はランダムアクセスとなります。このクエリも1メータあたり1回のGetリクエストが必要です。

図7:クエリ2はGetリクエストでランダムアクセス
あらかじめHBaseに格納した参照用データセットの設定を表9に示します。データの圧縮には図4#2で示したバランス重視の設定を採用しました。
表9:参照用データセットの設定
| # | データ設定 | 設定値 |
|---|---|---|
| 1 | レコード数 | 合計864億レコード(1,000万メータ×6ヵ月分)。 なお、データは30分単位 |
| 2 | レコードサイズ | 994GB |
| 3 | Region数 | 400個 |
| 4 | エンコーディング | FAST_DIFF |
| 5 | 圧縮アルゴリズム | GZ(GZIP) |
クエリ1の検証結果
(1)シングルスレッドの結果
クエリ1では1~100個のメータについて1~180日の時系列データを取得しました。最初にクエリ1をシングルスレッドで発行して測定を行いました。取得メータ数と取得期間を変動させたときのクエリの参照時間と参照スループットを図8に示します。

図8:クエリ1の参照時間と参照スループット(シングルスレッド)
この測定では、取得メータ数と取得期間が増加するほど参照スループットは向上しました。特に取得期間の影響が大きいと言えます。100メータのデータを参照する場合、取得期間が1日から180日に伸びると参照スループットは247レコード/秒から51,128レコード/秒まで約207倍向上しました。これは、取得期間が延びても1回のScanリクエストでまとめて取得できたためと考えられます。
(2)マルチスレッドの結果
次に、クエリ1をマルチスレッドで発行した場合の結果を図9に示します。最大スレッド数はScanリクエスト数と同数にしています。例えば100メータの時系列データを取得する場合は、最大100スレッドで並列にScanリクエストを発行しました。この測定ではScanリクエストの特性を生かすため、取得期間は最長の180日で固定しました。
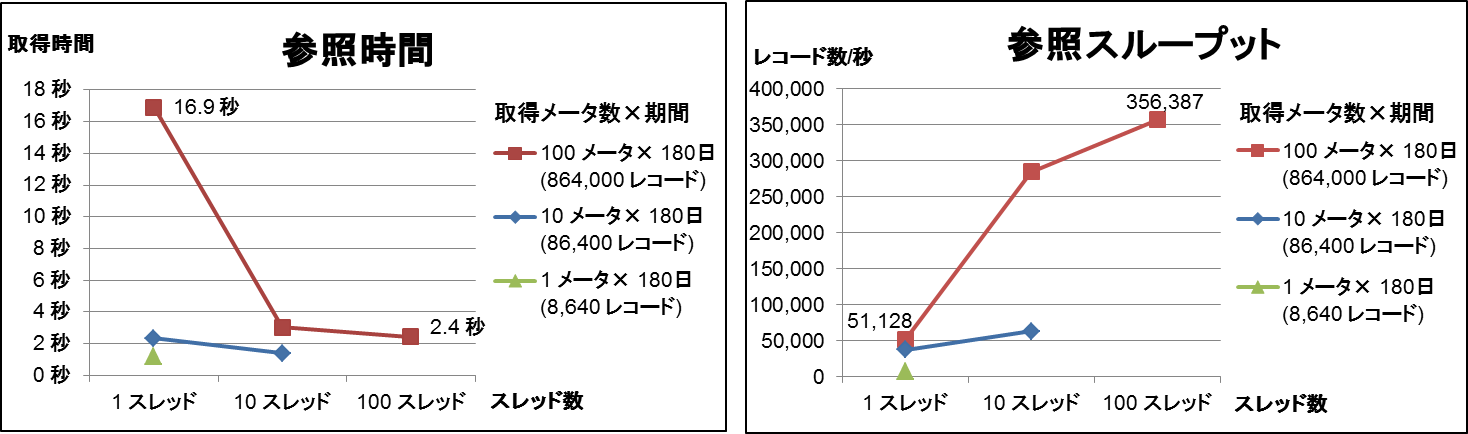
図9:クエリ1の参照時間と参照スループット(マルチスレッド)
この測定では、スレッド数を増やすほど参照スループットは向上しました。100メータのデータを取得する場合、スレッド数が1から100に増加すると参照スループットは51,128レコード/秒から356,387レコード/秒まで約7倍向上しました。これは、複数メータの時系列データを並列に取得できたためと考えられます。
クエリ2の検証結果
クエリ2では1万~1,000万個のメータについて最新時刻のデータを取得しました。クエリ2のリクエストをマルチスレッドで発行した場合の結果を図10に示します。今回は複数のリクエストをまとめて実行するBatchリクエストを使用して、Getリクエストをまとめて送信しました。加えて、このBatchリクエストをマルチスレッドで実行しました。
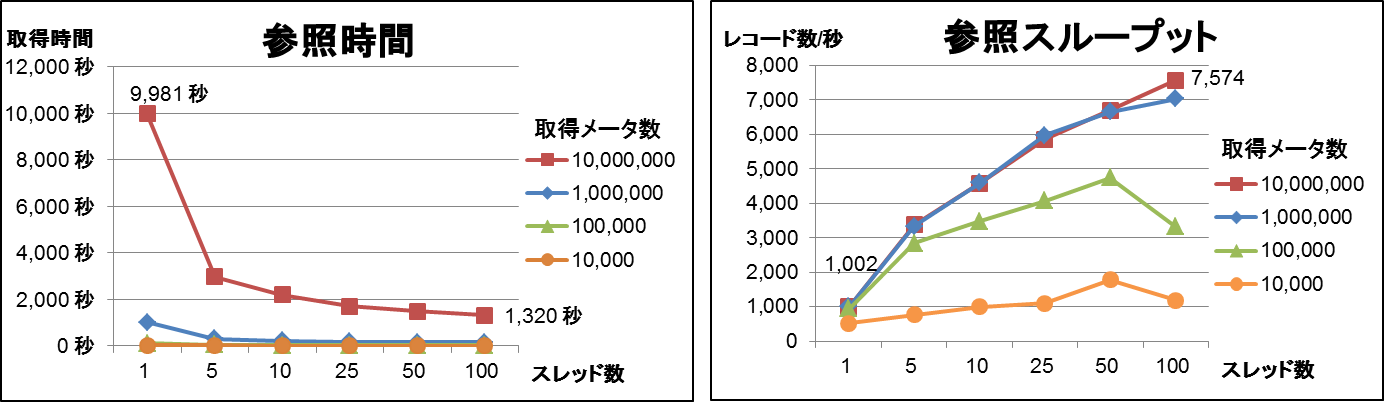
図10:クエリ2の参照時間と参照スループット(マルチスレッド)
この測定では、取得メータ数とスレッド数が増加するほど参照スループットは向上しました。ただし100万メータと1,000万メータのデータを取得する場合を比較すると、あまり参照スループットは変わりませんでした。1,000万メータを取得する場合、スレッド数が1から100に増加すると参照スループットは1,002レコード/秒から7,574レコード/秒まで約7.5倍向上しました。これは、複数メータのデータを並列に取得できたためと考えられます。
ScanリクエストとGetリクエストの比較
今回の検証では、Getリクエストに比べてScanリクエストでのスループットは47倍以上高くなりました(Scanは356,387レコード/秒、Getは7,574レコード/秒)。Getリクエストでのデータ取得はランダムアクセスとなり、Scanリクエストと比べてかなり時間がかかることが分かりました。なお、スループットにどれくらいの差が出るのかはデータ形式やデータサイズ、Scanでまとめて取得するレコード数など、様々な要因に左右されると考えられます。
また、Scan/Getリクエスト共に複数のリクエストを並列実行することでスループットは7倍以上向上しました。つまり、HBaseはデータ取得リクエストの同時実行性が高いと言えます。
検証を通して得られたノウハウ
性能検証のまとめとして、本検証で得られたノウハウを示します。
- RowKeyの設計
HBaseではデータをScanリクエストでまとめて取得できるように、キーを設計することが重要です。今回の検証では、Scanリクエストでデータをまとめて取得する場合とGetリクエストで個別に取得する場合では、参照のスループットに47倍以上の差がありました。 - リクエストの並列数
HBaseはマルチクライアント環境(またはマルチスレッドによるアクセス)で性能を発揮します。今回の検証では格納のPutリクエストと参照のScan/Getリクエストともに、マルチクライアントやマルチスレッドで実行することでスループットが7倍以上向上しました。つまり、HBaseはリクエストの同時実行性が高いと言えます。 - データの圧縮
HBaseはデータの構造上、データ量が大きくなりやすい傾向があります。今回の検証ではエンコーディングと圧縮アルゴリズムをうまく組み合わせることでデータ量を約1/5に圧縮できました。ただし、格納時間と参照時間は増加することが多いため、何を重視するかによって採用するアルゴリズムを決めるべきです。
おわりに
さて、HBaseについての連載は今回で最後となります。本連載ではHBaseのアーキテクチャと設計ノウハウ、および1,000万個のスマートメータのデータを管理するシステムを想定したHBaseの性能検証結果を紹介してきました。この性能検証により、HBaseはセンサデータの格納/参照で高い性能を発揮することが確認できました。
HBaseは特にマルチクライアント環境(またはマルチスレッドによるアクセス)で高い性能を発揮するため、多数のセンサが生成するデータを並列に格納するようなケースに適しています。また、HBaseはキーバリューをソートして格納するデータストアであり、センサが生成する時系列データを高速に参照できます。ただし時系列データの参照性能を引き出すためには、データをまとめて取得できるようにキーを注意深く設計する必要があります。
本連載がHBaseを用いたシステムを構築する際の参考になれば幸いです。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
