はじめに
残念なことに、ITシステムには障害がつきものです。システムは継続してしっかりと面倒を見なければ、いつか必ず壊れてしまいます。しかし、壊れるままにしておくわけにもいきません。障害の予兆をキャッチして事前に対策を打ったり、万が一にも障害が起きてしまったら迅速に復旧対応を行うのがインフラエンジニアの業務です。
そのために欠かせないのが、システムに対する「監視(モニタリング)」です。今回は監視とはなにか、そして、どのように監視を行うべきかについて解説します。
監視とは
システムは構築を完了し、リリースしたらおしまい、というわけではありません。むしろリリースはスタートラインに過ぎず、その後の運用こそが本番と言っても良いでしょう。そしてシステムを安定して稼動させ続けるためには、継続的な「監視」が必要不可欠です。
ITシステムにおける監視とは「システムの挙動や状態をチェックし続ける」行為を指します。システム障害はいつか絶対に起こるものです。障害が発生したら、ただちに復旧させなければなりません。そのためにはまず、障害が発生したことにいち早く気づける必要があります。サービスが停止しているのに誰も気づかず、ユーザーからのクレームで初めて障害を知るというのは最悪のパターンでしょう。
また、発生した障害に対応しているだけではなく、将来起こり得る障害を予測し、未然に防ぐことも重要です。例えば「Webサーバーのパフォーマンスは安定しているか」「データベースサーバーのストレージの空き容量は十分か」「ネットワークトラフィックはバーストしていないか」など、リソース量の変化も常に意識し、障害に繋がりそうな予兆を見つけたら、速やかに手を打つ必要があります。
システムを健全な状態に保つためには、こうした様々な部分に対して、常に気を配らなくてはなりません。そのために必要不可欠なのが監視なのです。
ただし、ひと口に「システムを監視する」と言っても、実際にチェックしなければならない項目は膨大な数に上ります。また監視はその性質上、24時間365日にわたって停止が許されません。これを人力で行うのは現実的ではないでしょう。そこでシ、ステム監視には専用の「監視ツール」が利用されます。
ここからは、具体的な監視の手法や、監視ツールについて見ていきましょう。
メトリクス監視
システムの情報を定期的に取得し、グループごとにまとめたデータを「メトリクス」と呼びます。メトリクス自体は単なる数値に過ぎず、そのままでは扱いづらいため、これを時系列に並べてグラフなどにプロットして可視化するのが一般的です。例えばサーバーのCPU使用率やストレージ容量、ネットワークトラフィック量を表したグラフなどは、メトリクスの典型的な例と言えるでしょう。
システムのパフォーマンスを計測する上で、メトリクスは非常に有用です。メトリクスを活用すれば、負荷の急激な上昇を検出したり、メモリやストレージ容量が枯渇する前にアラートを上げるといったこともできます。そのため、メトリクスは様々な監視ツールで普遍的に利用されています。

AWSのCloudWatchの例。様々なリソースから取得されたメトリクスを、ダッシュボードに自由にレイアウトして監視できる
ログ監視
稼働中のOSやアプリケーション内では、様々なイベントやエラーが発生します。このイベントを記録として残したものを「ログ」と呼びます。ログには「どのアプリケーションにいつ何が起きたのか」といった情報が記録されているため、問題の早期発見や障害時の調査において、非常に重要な手がかりとなります。またアクセスログや監査(audit)ログは、セキュリティ面からもしっかりと記録し、一定の期間、保全することが求められています。
ログには色々な形式がありますが、イベントの内容や付随データにタイムスタンプを付け、テキストで出力するのが一般的です。従来では1行に1イベントを列挙したテキスト形式のログが一般的でした。しかしこれは人間にとっては比較的読みやすいものの、機械がパースしづらいという問題があります。そこで、最近ではJSONなどのフォーマットを利用して構造化されたログもよく利用されています。またテキストではなく、独自のバイナリ形式でログを記録するシステムも存在します。例えば、近年のLinuxシステムで広く利用されているjournaldは、内部的にはバイナリでログを記録しています。
多くの監視ツールはログを監視する機能を備えています。例えばアプリケーションのログに対して正規表現でマッチングをかけ、特定のエラーメッセージが発生したらアラートを上げるといったことができます。
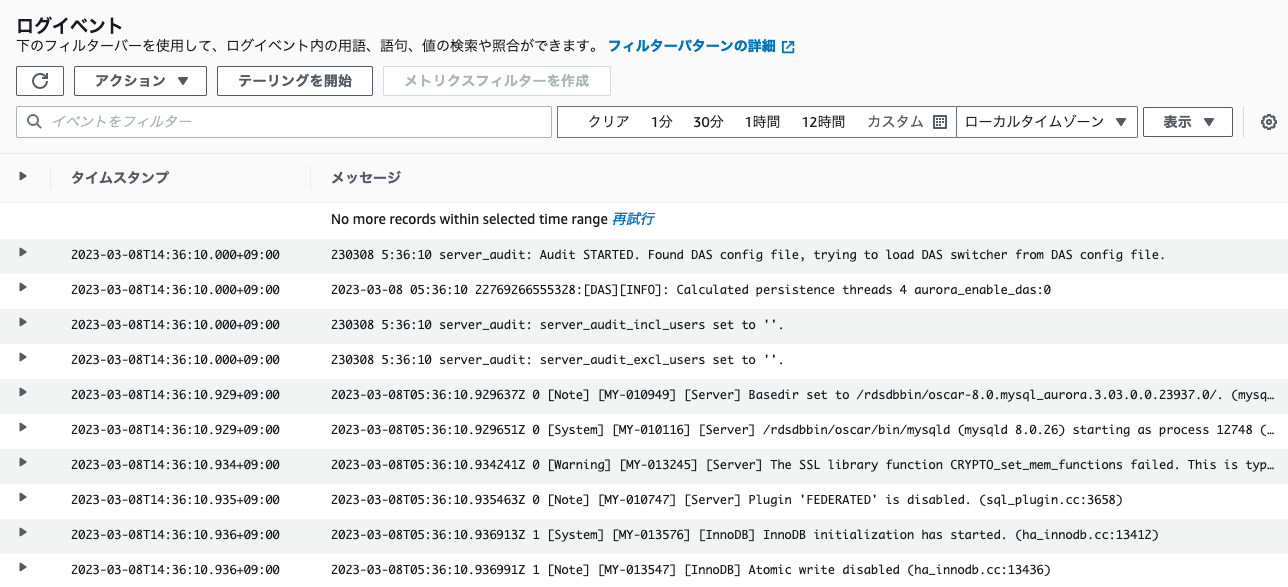
AWSのCloudWatch Logsの例。集約されたログに対しメトリクスフィルターを定義することで、ログの監視が行える
外形監視
前述のメトリクス監視やログ監視は、言わばシステムの内部情報をチェックするものです。こうしたシステム視点での監視を「内部監視」と呼びますが、内部監視だけでは監視としては不十分です。例えばインターネットへの経路上でネットワーク障害が発生すると、当然ユーザーはサービスにアクセスできなくなってしまいます。しかしこうした障害は、内部からサーバーのプロセスや負荷を監視していても検出できないのです。
そこでユーザーと同じ立場から、システムが正常に応答しているかを監視することが重要になってきます。具体的には「サーバーにPingを送ってネットワークの疎通を確認する」「サーバーのポートに接続可能か確認する」「実際にAPIをコールして応答を確認する」などです。これらは「システムの外部」から行う監視であるため、「外形監視」とも呼ばれます。
システムが動作していることと、実際にユーザーがサービスを利用できることはイコールではありません。そのため、外形監視をシステムとは物理的に異なるロケーションから行うことは非常に重要です。
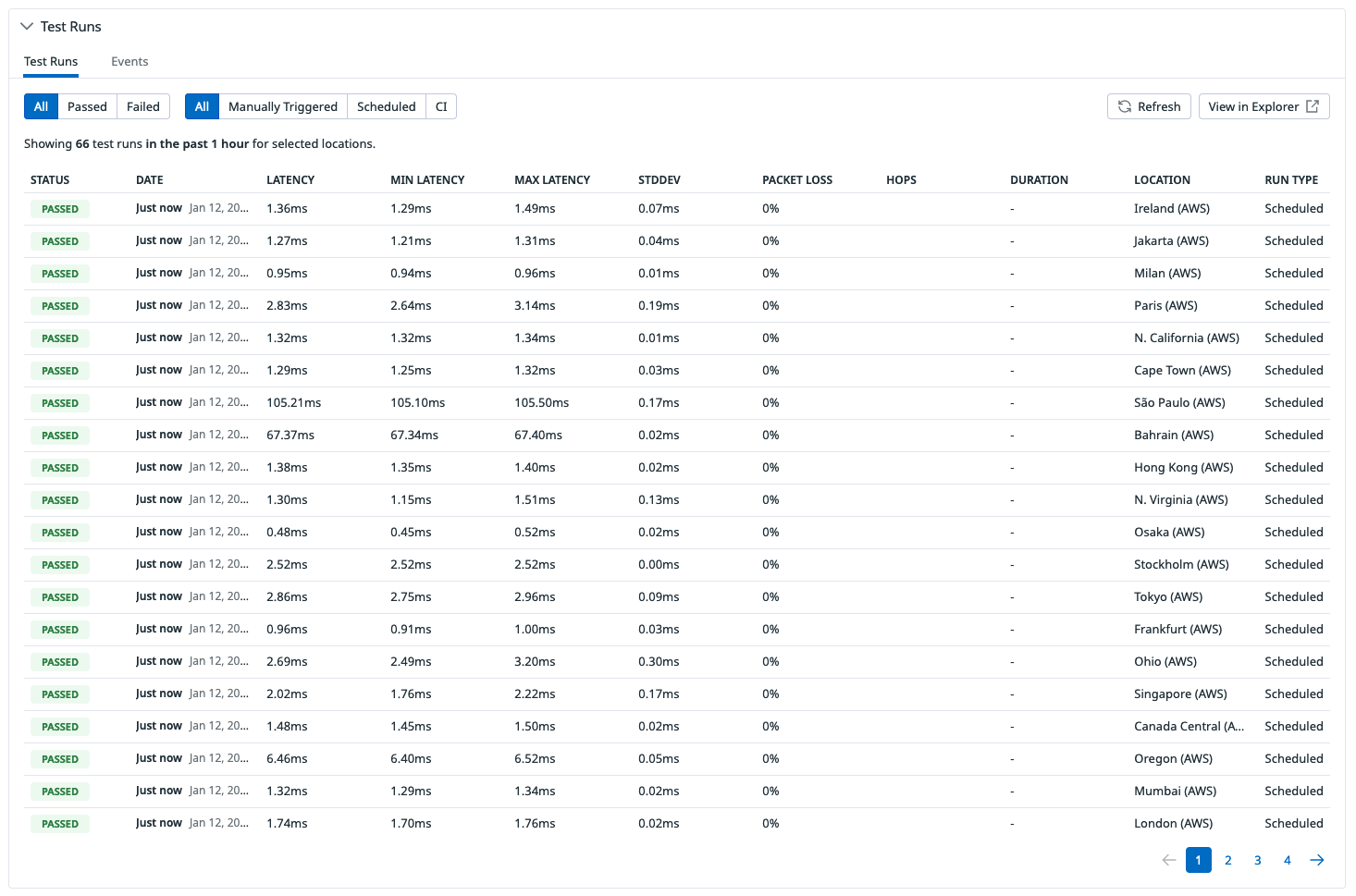
「Datadog」による外形監視の例。指定したURLに対して世界中のAWSリージョンからPingを送信し、ネットワークの疎通とレイテンシをチェックしている
アラート
監視ツールはシステムの状態をチェックし続けますが、単に「見てるだけ」では意味がありません。「システムが正常ではない」と判断した場合には、速やかにアラートを上げ、担当者に知らせる必要があります。そのため、一般的な監視システムは事前に設定した条件に従ってアラートを発生させる機能と、担当者への通知機能を備えています。
アラートは監視項目に条件を付けることで設定します。具体例を挙げると「サーバーのCPU使用率が90%を越える」「Webサーバーが一定時間Pingに応答しない」「アプリケーションログに致命的なエラーが出力された」といった具合です。ツールは監視により収集したデータを常にこの条件と付き合わせて正常/異常を判断します。そしていざアラート発生となった場合には、メール、SMS、Slackなどのチャット、メッセンジャーツール、電話などを利用して(あるいは併用して)、担当者に通知します。
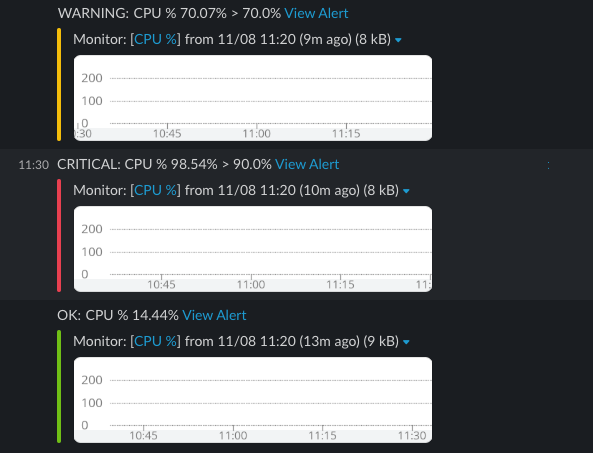
Slackにアラートが通知された例。メールよりも即時性が高く、かつ複数人の目に留まりやすく、電話ほど相手を拘束しないチャットはアラートの一次通知先として便利だ
「こうなったら確実にアラートである」と判断できるものについては、この方法は概ね上手く動作しますが、問題もあります。アラートとする条件(閾値)を事前に、明確に設定しなければならない点です。この例で言えば、アラートとするCPU使用率の閾値は90%で妥当なのでしょうか。もしかすると95%くらいまでは頑張れるのではないでしょうか。あるいは80%でも危険かもしれません。そしてこの閾値を正確に導出する方法は、おそらく存在しないでしょう。最初は過去の知見に基いて「ざっくり」設定するしかないはずです。そのためシステムの運用監視直後は、不適切な条件設定によりアラートの「誤報」が起きることも珍しくありません。
監視システムの運用には、こうした誤報を乗り越えて、少しずつ最適な条件を追い込んでいくチューニング作業も必要となってきます。
どのようなツールを使うべきか
監視ツールには様々なオープンソースの実装や、クラウドサービスが存在します。どれも機能的には概ね似通っていますが、細かい違いもあるため要件やコストに合わせてツールを選定することが大切です。
まずクラウド上にインフラを構築しており、そのクラウド事業者が専用の監視ツールを提供している場合は、その利用を第一に検討すべきです。というのもクラウドはその仕様上、クラウド事業者が提供している監視ツールでしか監視できない項目が少なからず存在するためです。例えば、AWSであれば「CloudWatch」、GCPであれば「オペレーション(旧称: Stackdriver)」などが利用できないかをまず検討してみましょう。
利用しているプラットフォーム向けの監視ツールが存在しない場合は、別途ツールを調達しなくてはなりません。その場合にお勧めしたいのが監視SaaSの利用です。監視はどれだけ頑張ってもサービスの価値そのものに直接寄与しないためです(もちろんシステムの安定性が上がることで、間接的にユーザーの満足度が上がるということはあります)。必要な要件を満たせるのであれば、監視ツール自体の運用にかかる負荷は可能な限り下げるのが望ましいと言えます。監視SaaSを利用すれば、監視データを集約する監視サーバーや、データを閲覧するフロントエンド部分の運用をSaaS事業者に任せられます。つまり監視ツールをセルフホストする場合に比べて、インフラエンジニアの負担を大きく軽減できるのです。有名な監視SaaSとしては「Datadog」や国産の「Mackerel」などがあります。
前述の条件に当てはまらない場合は、監視ツールのセルフホストを検討することになるでしょう。オープンソースの監視ツールとしては「Nagios」「Zabbix」「Prometheus」などが有名ですが、監視ツールのセルフホストは可能な限り避け、あくまで最後の手段にすべきだと筆者は考えています。理由は、前述の通り監視ツールそのものに注力するビジネス的なインセンティブが低いこと、そして監視ツールの運用自体が無視できない負担となる点です。例えば、監視ツールそのものの障害にはどのように備えれば良いのでしょうか。監視ツールを監視する別の監視ツールを用意すべきでしょうか。これではキリがありません。
なお、監視ツールは、どれか1つに絞らなければならないという決まりはありません。ツールにはそれぞれ得手不得手や使い勝手、かかるコストなどに違いがあるため、ツールの弱点を補う目的で複数のツールを併用するのは良い考えです。例えば基本的な監視はSaaSを利用しつつ、それでカバーできない項目はクラウドサービス独自の監視ツールで補う、といった使い方は珍しくありません。ツールごとの特性をよく理解した上で、効率良く組み合わせるようにしましょう。
おわりに
システムを継続して安定稼動させるには、システムを構成する様々な要素の状態を正しく把握し、万が一の障害時には迅速に対応できる体勢を整えなくてはなりません。そのためにも監視ツールの導入は必要不可欠です。そして、その内容もシステムの内部状態を監視する内部監視と、外部から見たサービスの状態を監視する外形監視の両方が必要となるでしょう。
とは言え、監視は手段に過ぎず、あくまで目的はシステムを健全な状態に保つことです。大抵の監視ツールは導入するだけで主要なメトリクスが取得されるようになっています。多くのグラフが整然と並び、リアルタイムに更新されていくダッシュボードを眺めるのは気持ちが良いものです。しかし、そのメトリクスは本当に監視する意味があるのでしょうか。意味のある監視を実現するためには、本当に監視しなければならない要素を選別し、放置できない異常を確実にキャッチできるよう、適切なアラートを設定しなくてはなりません。
次回は、こうしたありがちな監視のアンチパターンと、インシデント管理について解説します。
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
