Webサイトからの応答がない!
Webサイトからの応答がない!
問題が起きたのはユーザサイトの公開後10日程たった頃でした。ユーザからWebサイトへのアクセスができないと報告があり、Webサイトを確認したところ応答しなくなっていました。
すぐに対応を開始し、リカバリーを行いました。まずは、原因の切り分けです。
原因の切り分け
PKのユーザサイトは単一サーバで処理を行っているわけではなく、図2のように複数のサーバで、「Apache → mod_proxy → PHP」という順番で処理を行い、最終的なBlogコンテンツを配信しています。
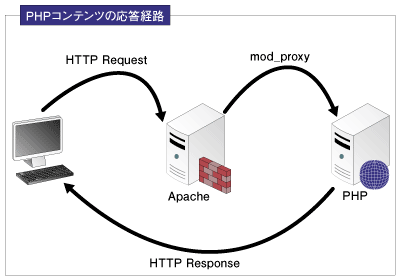
図2:PKユーザサイトの構成
このため、「ユーザサイトがダウンしている」といっても大別して以下の箇所で障害が発生している可能性があります。
- フロントエンドのApacheに障害が発生している
- 転送モジュールのmod_proxyに障害が発生している
- PHPコンテンツを配信するApacheに障害が発生している
まず、表2のどの箇所で障害が発生しているかを特定する必要がありまます。
最初に確認をしたのは、バックエンドのPHPが正常に稼働しているかです。フロントエンドのApacheを経由せずに直接PHPサーバへリクエスト を発行し、正常に画面が表示されることを確認しました。これでPHPサーバは正常に動作していたことがわかりました。
次にフロントエンドのApacheに配置された静的なコンテンツへリクエストを発行しました。しかしレスポンスが返ってきません。静的なコンテンツ はmod_proxyの転送対象としていないため、この時点でフロントエンドのApacheに障害が発生していると特定できました。
次に障害への対応です。
障害への対応
まずフロントエンド側のApacheのログを確認しましたが、この時点ではとりとめてサーバがダウンするようなログを見出すことはできませんでした。
次にApacheのプロセスをpsコマンドで確認したことろ相当数のApacheのプロセスが起動していることが判明しました。この時点で、原因の究明までにある程度の時間がかかることが推測されました。
今回は計3台のサーバでサイトを構成しており、「Apache → PHP」と「Apache → Tomcat」の2つの転送機構を利用しています。これらを切り分けるためには、以下の項目を確認する必要があります。
- フロントのApacheの状況
- 転送機構mod_jkの状況
- 転送機構mond_proxyの状況
- フォワード先のTomcatの状況
- フォワード先のPHP(Apache)の状況
そのため、障害の切り分けにはかなりの人的コストと時間がかかります。今回のケースでは、サービスの復旧が第1優先として考えられるため、すぐさまApacheを再起動することにしました。
フロントエンドのみが停止しておりバックエンドのTomcat、PHPは動作していたので、今回はフロントエンドのApacheを再起動することで復旧しました。停止しているのがわかってから復旧まで1時間程で完了しました。
原因の究明にあたって
次のステップではサービス停止に陥った原因を調べることが重要となります。しかし、これには時間がかかることがわかっていました。また、原因を究明している間に同じような問題が再び発生する可能性もあります。
公開サイトでまず考えなければいけないことは、程度にもよりますが多少の問題があっても「動き続けること」だと考えます。サービスの停止は、利用ユーザの方々に迷惑をかけてしまうからです。
そこで、当初から検討事項の1つだったLifeKeeperの導入によるHA(ハイアベイラビリティ:High Availability)化を前倒しで実現することにしました。また、導入までの期間は定期的な夜間バッチによるサービスの再起動で対応しました。 LifeKeeperについては、以下のURLを参照してください。
今回のケースでは、「HA化の導入基準」という大きな教訓を得られました。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
