【完全解剖】AIエージェント時代のセキュリティ
本連載は、生成AIコミュニティ「IKIGAI lab.」で活動するメンバーが、それぞれの専門領域で培ってきた知見を持ち寄りながら、生成AIを取り巻く動向を技術・ビジネス・ガバナンスの観点から整理しお届けしています。
1月22日 6:30
はじめに
生成AIを巡る議論は、2023年から2024年にかけては「モデル性能の進化」や「業務に使えるかどうか」という可能性探索が中心でした。企業でもPoC(概念実証)や限定的な試験導入が相次ぎ、生成AIは主に「補助的なツール」として位置付けられていました。
2025年以降、生成AIは「試してみる技術」から「業務プロセスや情報システムに組み込まれる前提の技術」へと位置付けが変化しつつあります。社内規定を検索して回答する、顧客からの問い合わせにFAQ+CRMを参照して返答する、見積書や申請書を生成してワークフローに流す、ERPやチケットシステムと連携して処理を完了させるなど、生成AIが業務フローの一部を担う場面が増えています。
この変化を象徴する概念が「AIエージェント」です。AIエージェントは、単に質問に答えるチャットボットではなく、外部データや業務システムと連携しながら、情報の取得、判断、実行までを(半)自律的に行う構成を含みます。しかし生成AIが「助言する存在」から「行動する存在」へ役割を広げるほど、これまでのITガバナンスやセキュリティモデルでは扱いづらいリスクが増えていきます。
本記事では、その代表的なリスクとして、組織が把握していない生成AI利用(シャドーAI)と、自然言語入力を悪用・誤用したプロンプト・インジェクション(Prompt Injection)を中心に、現場の実装・運用に落とし込むための視点を整理します。
AIエージェント活用が進む中で何が起きているのか
ー生成AIは「試行」から「業務基盤」へ移行
AIエージェントは立場や思想により定義が異なります。まずは、代表的な企業の定義を紹介します。
- ユーザーの代わりに独立してタスクを遂行するシステムとして捉えています。(OpenAI)
- LLMが自らのプロセスやツールの使用を動的に指示し、タスクの達成方法を制御するシステムです。(Anthropic)
- AI を使用してユーザーの代わりに目標を追求し、タスクを完了させるソフトウェア システムです。(Google)
このほか、独立行政法人 情報処理推進機構が示すように各企業や団体によって様々な定義があります。また、AIエージェントという言葉は文脈によって幅がありますが、共通しているのは「状況を把握し、判断し、行動して目標達成を支援する」という点です。
| 基本要素 | 内容 |
|---|---|
| 自律性 | 事前のルールに依存せず、環境に応じて判断・行動できる |
| 目標指向 | 設定されたゴールに向けて最適なプロセスを構築する |
| 高度な推論 | 複数のデータを活用し、状況に適した意思決定を行う |
| 外部連携 | APIや他のAIエージェントと協調し、データを活用する |
表1 AIエージェントの基本要素【出典】「AIエージェントとは?次世代技術の活用と未来展望をわかりやすく解説」(WOR(L)D ワード 大和総研の用語解説サイト)
このように、従来のチャット型生成AIが「入力に対して文章を生成する」ことを中心としていたのに対し、AIエージェントでは次のようなことが可能となっています。
- 外部データソース(データベース、文書、Web)へのアクセス
- APIや業務システムとの連携
- 状況に応じた判断と処理の自動実行(または実行支援)
これにより、生成AIは単独で完結するツールではなく、業務フローの一部として振る舞うことができるようになります。
AIエージェント導入が進む背景には、技術的進化に加えて、企業側の期待と業務ニーズの変化があります。人手不足や業務量増加への対応、定型業務の自動化ニーズの高まり、生成AIの精度向上による実用性の向上などが、導入を後押ししています。
TechRadarが報じたSailPointが実施したIT専門職向けの調査では、多くの組織がAIエージェントの業務利用に前向きである一方、同時に強い懸念を抱いていることが示されています。この結果は、AIエージェントが「流行」ではなく業務合理性に基づいて検討されている一方で、リスク管理の難しさも同時に認識されていることを示しています。
業務適用が進むことで見えてきた新たな課題
生成AIは業務で活用されるにつれ、試行錯誤段階では見えにくかった運用上の課題を伴うようになります。重要なのは、これらが一部の先進企業や特定製品に固有の問題ではなく、生成AIを活用する企業で共通して生じやすい点です。
NTT DATAでは、企業の生成AI活用において特に実務上の影響が大きい要素に焦点を当てて、以下5つの代表的なリスクの例を挙げています。
| リスク | 内容 |
|---|---|
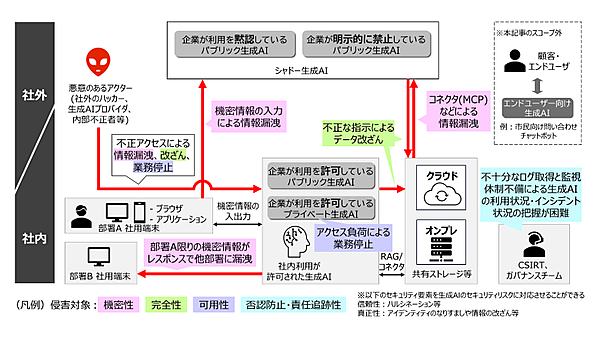
| 機密情報の 外部漏洩 | 生成AIへの機密情報の入力により、会社内部の機密情報がサービス提供者や社内外の他のユーザーに流出するリスクが存在します。また、利用者による入力だけでなく、コネクタ(MCP)などを介したシステム間通信により、意図せず機密情報が生成AIに漏洩する可能性もあります。 |
| 情報の改ざん や喪失 | プロンプト・インジェクションや学習データの汚染(データポイズニング)など、社内外からの攻撃によってシステム内の情報が改ざん・喪失するリスクも存在します。 |
| サービス障害 による業務影響 | 生成AIへの業務依存が進むことで、外部サービスの障害や停止、仕様変更に加え、生成AIの停止を狙った攻撃や、過剰なアクセスによるリソースひっ迫といった要因により業務の遅延や停止を引き起こす可能性があります。 |
| 操作履歴の 不透明性 | 生成AIサービスでは、ユーザーの操作履歴や入出力内容の記録が不十分な場合があり、インシデント発生時に誰が何を行ったかを特定することが困難になる可能性があります。 |
| ガバナンスの 曖昧化 | 生成AIの利用が部門ごとに独自に進められ、組織全体での統制が取れていない場合、利用実態の把握が難しくなり、インシデント発生時の責任の所在が不明確になるリスクがあります。特に、社内での承認を得ずに利用されるシャドーAIの存在は、ガバナンスの曖昧化を一層深刻にします。 |
表2 リスクとその内容
【出典】「情報漏洩?企業における生成AI活用の落とし穴」(DATA INSIGHT 2025/07/03)
このようなリスクに対しては、単純な利用禁止や一律制限は現実的な解決策になりにくく、利活用を前提にした設計・統制が必要になります。ここでは、多くの企業や組織で実際に起こりやすく、しかも問題に気づかないまま被害や統制の乱れにつながりやすいという共通点を持つリスクとして、シャドーAIとプロンプト・インジェクションを取り上げます。
シャドーAIは、現場での利便性や業務効率を優先する中で、管理部門が把握しないままAIの利用が広がることで生じる、組織としてのリスクです。業務改善や生産性向上を目的とした“善意の利用”から始まることが多く、結果として情報管理や統制の抜け落ちが生じやすい点に特徴があります。
一方のプロンプト・インジェクションは、AIの詳しい仕組みを知らなくても、入力される文章の内容や書き方次第で、外部から意図せず引き起こされてしまう技術的なリスクです。そのため、従来のセキュリティ対策だけでは十分に防ぐことが難しい側面があります。
この2つは性質こそ異なりますが、「AIの利用を始めた組織ほど直面しやすい」「問題が表面化しにくいまま影響が広がっていく」という点で共通しています。そのため、AIの利活用を進めるうえで、早い段階で理解しておくべき代表的なリスクと言えるでしょう。
シャドーAIとは?
ーシャドーAIはなぜ生まれるのか?「非公式利用」が拡大する現場の構造

これまで整理した通り、生成AIやAIエージェントは、すでに多くの企業で業務プロセスの一部として使われ始めています。その一方で、組織としての整備や統制が追いつかないまま、利用だけが先行する状況も広く観測されています。
このギャップが表面化した現象が、いわゆるシャドーAIです。シャドーAIは、生成AI時代に突然現れた新概念というより、従来から問題視されてきたシャドーITが、生成AIの特性によってより顕在化・拡大したものとして考えることができ、組織のIT部門やセキュリティ部門の明確な承認・把握がないまま、生成AIツールやサービスが業務に利用されている状態を指します。
| シャドーIT | シャドーAI | |
|---|---|---|
| 基本定義 | IT部門の管理外でSaaS・クラウド・アプリ・機器が使われる状態 | 組織の管理外で生成AI・AIエージェントに業務データが入力・利用される状態 |
| 典型例 | 個人Dropbox、私用Slack、無断SaaS、私用PC | 個人ChatGPT、未承認Copilot、勝手に作られたRAGや業務エージェント |
| 使われる場面 | ファイル共有・コミュニケーション・簡易業務 | 文書作成、契約レビュー、顧客対応、システム操作の自動化 |
| 扱うもの | データ(ファイル・情報) | データ+知識+判断ロジック+業務フロー |
| リスクの本質 | データの外部保存・共有 | データが学習され、判断や行動に変換される |
| リスクの性質 | 静的(保存・流出が問題) | 動的(生成・推論・実行が問題) |
表3 シャドーITとシャドーAIの比較
大きな違いは、シャドーITが「IT部門の管理外でクラウドサービスやアプリが使われる状態」であったのに対し、シャドーAIは「管理外の生成AIに業務データが入力される状態」である点です。
一見すると、どちらもデータが社外のシステムに転送されているだけのように見えます。しかし、シャドーAIの場合、次の点で影響がより大きくなります。
- 入力された情報が、そのまま外部AIサービスに送信される
- データの保存・再利用範囲が利用者から見えにくい
- 利用履歴やログが組織側に残らない場合がある
生成AIサービスの中には、入力データの保存や学習利用の扱いが利用形態(個人向け/法人向け/API利用)によって異なるものがあります。設定や契約条件によっては、入力内容がサービス側に保持される可能性もあるため、シャドーAIへの業務データ投入は、社外送信・保存範囲が統制できないリスクを伴います。
このような状況では、従業員が業務効率化のために機密データ(ソースコード、顧客リスト、議事録など)を入力した瞬間、そのデータは社外に送信されるだけでなく、保存範囲や利用範囲を組織が管理できない形で取り扱われるリスクを生じます。
このため、同じ「非公式利用」であっても、シャドーAIが従来のシャドーIT以上に、情報漏えいやコンプライアンス上の影響が深刻化しやすいと指摘されています。
調査データに見るシャドーAIの実態

【参照】「Cloud and Threat Report: 2026」(Netskope)
Netskopeが発表した調査では、企業における生成AI関連のポリシー違反件数が急増していることが報告されています。
このレポートでは、
- 企業あたり月平均200件超の生成AI関連ポリシー違反が確認されている
- 違反の多くが、個人向けAIアプリや非承認ツール経由で発生している
さらに、Gartnerは「2030年までに企業の40%以上が、許可されていない「シャドーAI」に起因するセキュリティまたはコンプライアンス上のインシデントを経験する」と予測し、警告しています。
この予測は、シャドーAIが一時的な過渡現象ではなく、生成AI活用が進むほど顕在化しやすい構造的問題であることを示唆しています。
では、なぜ多くの企業でシャドーAIが生まれてしまうのでしょうか。複数の調査や報道を整理すると、主に次の2つの要因に集約できます。
①社内のAI環境整備が現場ニーズに追いついていない
多くの企業では、生成AIの利用方針やルール整備が進められています。しかし、
- 導入までに時間がかかる
- 利用できる機能が限定的
- 業務スピードに合わない
AIツールの利用に関する調査結果レポートでは、従業員が非公式AIを利用する背景として、
- 業務を効率化したい
- 時間を短縮したい
- 公式なAIツールや正式なソリューションが十分に提供されていない
②利便性と即時性が利用を後押しする
生成AIは、
- 即座に回答が得られる
- 情報整理や文章作成を短時間で行える
参考として、Microsoftの調査では、英国の従業員の71%が会社で承認されていない消費者向けAIツールを職場で使った経験があり、51%は毎週利用していると報告されています。
注目すべきは、その背景です。同調査では、利用理由として「私生活で使い慣れている」(41%)、「会社が業務用の承認ツールを提供していない」(28%)が挙げられており、現場では“便利で今すぐ使える”ことが利用を押し上げていることが分かります。
さらに、未承認ツール利用に伴うリスクについて「会社・顧客データのプライバシー」を懸念する人は32%、「自社ITの安全性」を懸念する人は29%にとどまっており、危険性の理解や警戒よりも、実務上の即効性が先に立ちやすい状況が示唆されます。
このように、シャドーAIは「ルール違反」というより、企業による公式な環境提供と現場ニーズのギャップから生まれる構造的現象といえます。
これまでシャドーAIは、現場のリテラシー不足やルール違反として処理されがちでした。しかし、複数の専門家やセキュリティ企業は、この見方に警鐘を鳴らし、シャドーAIは組織の設計・統制・提供体制の問題が表面化した結果として考えられるようになってきました。この視点は、シャドーAIを個人の問題ではなく、組織構造やガバナンス設計の課題として捉える必要性を示しているといえます。
プロンプト・インジェクションとは?
ー「攻撃手法」ではなく「実装前提のズレ」として再整理する

生成AIの業務利用が拡大する中で、近年、セキュリティ分野や専門メディアで繰り返し取り上げられているもう1つのリスクが「プロンプト・インジェクション(Prompt Injection)」です。当初は研究者コミュニティや一部の技術者の間で議論されていましたが、AIエージェントやRAG(Retrieval Augmented Generation)といった構成が一般化するにつれ、実務上のリスクとして扱われる場面が増えています。
プロンプト・インジェクションとは、生成AIが処理する入力や参照情報の中に含まれた指示文・命令文を、本来のシステム指示と区別できずに解釈・反映してしまう現象を指します。
この問題の本質は、LLMが入力テキストの中で、
- どこまでが「命令」なのか
- どこからが単なる「情報」なのか
研究論文では、プロンプト・インジェクションの問題について、大規模言語モデル(LLM)が入力されたテキストの中で、命令と単なるデータを厳密に区別しないという性質に起因する構造的課題とされています。同論文では、LLMが外部入力や参照データを含むコンテキストを処理する際、信頼できない入力の中に含まれた指示文が、本来のシステム指示と同列に解釈され得ることが示されています。
その結果、意図しない命令や悪意ある指示が、モデルの振る舞いに影響を与える可能性があると論じられています。このような性質は、特定の製品や実装ミスに起因するものではなく、自然言語をインターフェースとするLLM全般に共通する前提条件です。
チャットAIからAIエージェントへ
ーリスクが拡大した理由
初期のチャット型生成AIにおいても、プロンプト・インジェクションの問題が存在していました。しかし、多くの専門家は、AIエージェントの登場によってリスクの性質が変化したと指摘しています。その背景として、次の要因が挙げられています。
- AIが単なる応答生成にとどまらず、外部システムやAPIと連携する
- 入力がユーザーの直接入力だけでなく、メール、Webページ、文書、ログなどに広がる
- 判断結果が、そのまま自動処理や実行につながる構成が増える
プロンプト・インジェクションが業務リスクとして注目されている理由の1つは、必ずしも悪意ある第三者による攻撃を必要としない点にあります。次のようなケースが例として挙げられています。
- 顧客からの問い合わせメールに含まれる操作手順
- Webページに記載された注意書きや説明文
- 業務マニュアルやFAQに含まれる指示表現
これらは人間にとっては単なる情報ですが、AIにとっては「実行すべき命令」として解釈される可能性があります。プロンプト・インジェクションが高度な侵入技術ではなく、自然言語インターフェースの前提条件から生じる問題であることを示しています。
具体的な事例として、TechRadarはIBMのAIエージェント機能に関する検証記事の中で、外部データに含まれる指示によって、想定外の処理が実行され得る点を紹介しています。
チャットボットでも、プロンプト・インジェクションにより誤情報の提示や意図しない情報露出といった影響は起こり得ます。しかし、外部システムへの実行権限を持つAIエージェントの場合、判断が操作に直結する分、その被害は実務プロセスへ波及しやすくなります。
事故は「人」ではなく「設計」で防ぐ
ーAIエージェント時代に求められる実装原則
これまでで見てきた通り、生成AIやAIエージェントによって生じるリスクは、特定の個人の操作ミスや高度なサイバー攻撃によって突発的に引き起こされているわけではありません。むしろ、設計上の前提条件や運用ルールが十分に整理されないまま利用が進んだ結果として、徐々に顕在化しているケースが多いことが、複数の事例や調査から示されています。
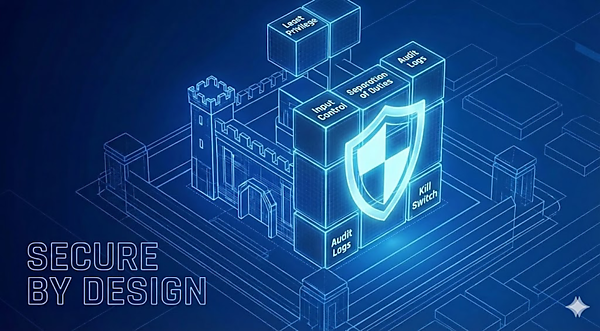
このような背景を踏まえ、近年は「注意喚起」や「教育」だけに依存するのではなく、事故が起きにくい前提を設計段階で組み込むことの重要性が強調されるようになっています。以下では、OWASP が公開している「2025年 LLMおよび生成AIアプリケーションのトップ10リスクと軽減策」やベストプラクティスに共通する観点をもとに、シャドーAIやプロンプト・インジェクションの影響が実運用に波及しやすい点(権限・入力・実行・監査・停止)に焦点を絞って、AIエージェント時代に重要とされる実装原則を6つご紹介します。
①最小権限の原則
AIエージェント設計において、最も頻繁に言及される原則の1つが最小権限原則(Least Privilege)です。これは従来のITセキュリティでも基本とされてきた考え方ですが、生成AI、とりわけ自律的に判断・実行を行うエージェント構成では、改めて重要性が高まっています。
初期段階から広範な権限を付与してしまうと、想定外の入力や誤った判断が、そのまま業務システムや外部サービスへの操作に直結するリスクが高まります。そのため、多くのガイドラインでは、必要最低限の権限から始め、用途に応じて段階的に拡張する設計が推奨されています。
②「読む・考える・実行」を分離する設計
AIエージェントに関する事故分析で繰り返し指摘されているのが、判断と実行が同一プロセスに含まれていた点です。実務上は、次のようなフェーズ分離が重要とされています。
- 情報を収集・整理するフェーズ
- 判断や提案を生成するフェーズ
- 実際に外部システムへ影響を与える実行フェーズ
特に実行フェーズについては、追加の制御や人の関与を設ける設計(Human-in-the-loop)が推奨されています。この分離によって、「AIが何を参照し、どこまで判断し、どこからが実行なのか」を明確にでき、影響範囲を限定しやすくなります。
③入力データの分類と制御
シャドーAIやプロンプト・インジェクションの問題と密接に関係するのが、どのデータをAIに入力してよいのかを事前に定義することです。実務では、次のような分類が採られ始めています。
- 公開情報
- 社内限定情報
- 規制対象・機密情報
これらを区別し、AIエージェントごとに入力可否を明示する運用を行うことで、意図しない情報流通や再利用のリスクを抑制しやすくなります。
④外部入力は「信頼しない」前提で扱う
プロンプト・インジェクションの章でも触れた通り、メール、Webページ、文書ファイルなどの外部入力は、信頼の置けない外のデータとして扱う前提に立つ必要があります。これは「攻撃を疑え」という意味ではなく、自然言語入力には命令と情報の境界が曖昧になりやすい、という特性を前提にする設計思想です。外部入力をそのまま実行判断に結び付けない構成が、重要な軽減策として位置付けられています。
⑤ログと監査を「事後対応」ではなく「運用」へ
AIエージェントでは、入力・参照・判断・実行が連鎖するため、事後に「何が起点だったか」を説明できないことが重大なリスクになります。入力、参照情報、生成結果、実行内容を追跡できるログ設計を平常運用に組み込み、監査・説明責任を果たせる状態を先に作っておく必要があります。
⑥「止められる」ことを前提にした設計
AIエージェントを業務に組み込む場合、いつでも止められることを前提にした設計も欠かせません。具体的には、
- 即時停止(Kill Switch)
- 権限の一時無効化
- 人が判断するための承認・連絡フロー
これはAIの暴走を前提にするのではなく、不確実性を含むシステムを業務に組み込む以上、停止手段を設計に含めるという考え方です。
おわりに

AIエージェント時代の情報漏えい対策は
「導入時の設計」で決まる
これまで見てきた通り、生成AIやAIエージェントを巡る情報漏えいリスクは、特定の個人の不注意や、例外的な攻撃手法だけで説明できるものではありません。シャドーAIやプロンプト・インジェクションに代表されるリスクは、生成AIを自然言語で業務に組み込み、外部と接続するという前提そのものから生じる構造的なリスクです。
そのため、対策の焦点は「使う人に注意を促すこと」や「問題が起きた後の是正」ではなく、使うことを前提に、どのように設計し、どこで制御するかが重要になってきます。
国内でも進む「生成AIを前提としたセキュリティ整理」
こうした考え方は、海外のガイドラインやセキュリティ団体に限ったものではありません。日本においても、総務省がサイバーセキュリティ分野の検討枠組みの中で「AIセキュリティ分科会」を設置し、生成AIの普及を前提とした新たな脅威と技術的対策の整理を進めています。
同分科会での検討結果を踏まえた「AIのセキュリティ確保のための技術的対策に係るガイドライン(案)」については、意見募集(パブリックコメント)が実施されており、生成AIを使う前提でどう設計・統制するかという観点が、制度面でも整理されつつある状況が確認できます。
生成AIが業務の一部として定着する兆しが見えてきている今、問われているのは「使うか、使わないか」ではありません。
どの前提で、どこまで任せ、どのように制御するのか。その設計と運用の積み重ねこそが、AIエージェント時代のセキュリティリスクを現実的に抑える鍵となります。
「生成AI、どう教える?どう使う?」を2月7日に開催!

生成AIコミュニティ IKIGAI lab.は2026年2月7日、親子と教員向けイベント「生成AI、どう教える?どう使う? 親の『不安』と先生の『多忙』をAIで解決する1日」を開催します。
小中高校生の保護者や教員、教育関係者を対象とし、神田神保町の株式会社インプレス本社のリアル会場かオンラインでの参加を選べます。参加費は無料で、フォームから事前の申込が必要となります。
詳細および申し込みは、こちらから!
IKIGAI lab.、親子と教員向けイベント「生成AI、どう教える?どう使う?」を2月7日に開催 リアル会場とオンラインを同時開催、参加無料で会場は定員100名 - こどもとIT
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
【徹底解説】ChatGPTの進化が止まらない! 新機能完全ガイド
2024年10月24日 8:44
【ジェイルブレイク】GPT-5炎上と脱獄―炎上の裏で進む技術革命と新たな脅威
2025年9月18日 6:30
【最新アップデート】GPT-5.1/Gemini 3/Claude 4.5はそれぞれ何が変わったのか
2025年12月11日 6:30
【完全ガイド】「Deep Research」の全貌&「Dify」でAIエージェント構築入門
2025年3月19日 6:30
【天才プロンプト進呈】あなたに最適な生成AIはこれだ!
2024年7月18日 6:30
【解決力UP】オーケストレーションが可能にする生成AIの活用法、具体例を徹底解説
2024年9月26日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
