「AWS CloudWatch」でEKSクラスターを監視してみよう
第19回の今回は、「AWS CloudWatch」を使用してEKSクラスターを監視する方法について解説します。
1月27日 6:30
はじめに
第15回から第18回までの4回にわたり、Terraformを使ったAWSインフラの構築とチーム開発のベストプラクティスを学びました。VPC、EKS、ECRといったリソースをコードで管理し、環境分離、リモートバックエンド、CI/CD統合を実現しました。
しかし、インフラを構築したらそれで終わりではありません。運用フェーズでは、インフラの健全性を継続的に監視し、問題を早期に検知する仕組みが不可欠です。
監視の課題
構築したEKSクラスターやその他のAWSリソースは、パフォーマンスの問題や障害が発生する可能性があります。例えば、以下のような問題が考えられます。
- EKSノードのCPU使用率が高くなり、アプリケーションのレスポンスが遅くなる
- メモリ不足でPodが強制終了される
- ディスク使用率が100%に達してログが記録できなくなる
- ネットワークトラフィックが急増してコストが増加する
これらの問題に気づくためには、まずインフラの状態を可視化し、何が起きているかを把握できる仕組みが必要です。
本記事では「AWS CloudWatch」を使ったEKSクラスターの監視方法を解説します。CloudWatchでメトリクスを収集し、ダッシュボードで可視化することで、インフラの健全性を一目で確認できるようになります。
AWS CloudWatchとは
AWS CloudWatchは、AWSリソースとアプリケーションをモニタリングするためのサービスです。メトリクスの収集、ログの保存、アラームの設定など、包括的な監視機能を提供します。
CloudWatchの主な機能は以下の通りです。
- メトリクス: EC2、EKS、RDSなどのAWSリソースのパフォーマンスデータを自動収集
- ダッシュボード: 複数のメトリクスをグラフで可視化
- ログ: アプリケーションログやシステムログを一元管理
- アラーム: しきい値を超えたときに通知を送信
本記事では「メトリクス」と「ダッシュボード」に焦点を当てて解説します。「アラーム」については次回(第20回)で詳しく解説します。
CloudWatchはAWSリソースのメトリクスを自動的に収集するため、追加の設定なしで基本的な監視を開始できます。ただし、詳細な監視や独自のメトリクスを収集するには、CloudWatch Agentのインストールやカスタムメトリクスの設定が必要になる場合があります。
EKSクラスターのメトリクス監視
利用可能なメトリクス
EKSクラスターを構築すると、CloudWatchは自動的に以下のメトリクスを収集します。
【EC2インスタンス(EKSノード)のメトリクス(AWS/EC2ネームスペース)】
- CPUUtilization: CPU使用率(%)
- NetworkIn: 受信ネットワークトラフィック(バイト)
- NetworkOut: 送信ネットワークトラフィック(バイト)
- DiskReadBytes: ディスク読み取りバイト数
- DiskWriteBytes: ディスク書き込みバイト数
これらのメトリクスは、EKSノードとして動作しているEC2インスタンスのパフォーマンスを監視するために使用します。
【EKSクラスターのメトリクス(Container Insights有効時)】
Container Insightsを有効にすると、Kubernetesレベルの詳細なメトリクスも収集できます。
- node_cpu_utilization: ノードごとのCPU使用率
- node_memory_utilization: ノードごとのメモリ使用率
- pod_cpu_utilization: PodごとのCPU使用率
- pod_memory_utilization: Podごとのメモリ使用率
以降では、まず基本的なEC2メトリクスの監視から始めます。「Container Insights」については、追加の設定が必要なため、今回は扱いません。
AWS公式の推奨監視項目
AWSは「Observability Best Practices」でEKSクラスターの監視すべきメトリクスを公開しています。主な推奨項目は以下の通りです。
【コントロールプレーンメトリクス】- apiserver_request_duration_seconds: APIサーバーのリクエストレイテンシ
- etcd_request_duration_seconds: etcdデータベースの応答時間
- scheduler_pending_pods: スケジュール待ちのPod数
- kube_node_status_condition: ノードの健全性状態
- kube_deployment_status_replicas: デプロイメントのレプリカ状態
- kube_pod_status_ready: Podの準備状態
- container_cpu_usage_seconds_total: コンテナのCPU使用量
- container_memory_usage_bytes: コンテナのメモリ使用量
- kube_pod_container_status_restarts_total: コンテナの再起動回数
AWS Observability Accelerator for Terraform
より本格的な監視環境を構築したい場合は「AWS Observability Accelerator for Terraform」が便利です。このプロジェクトは、EKSクラスターの監視に必要なリソースをTerraformで一括デプロイできます。
提供される機能は以下の通りです。
- メトリクス収集: Amazon Managed Service for PrometheusまたはCloudWatch Container Insights
- ダッシュボード: Amazon Managed Grafanaの事前構成済みダッシュボード
- アラート: 推奨されるアラートルールのセット
- トレース: AWS X-RayとOpenTelemetryによる分散トレーシング
GitHubリポジトリ(aws-observability/terraform-aws-observability-accelerator)からTerraformモジュールをダウンロードして、既存のインフラに統合できます。
ここでは基本的なCloudWatchの使い方を解説しますが、本番環境ではこれらのツールの活用も検討してください。
CloudWatchメトリクスの確認
- AWSマネジメントコンソールでCloudWatchを開き、左側のメニューから「メトリクス」→「すべてのメトリクス」を選択します。
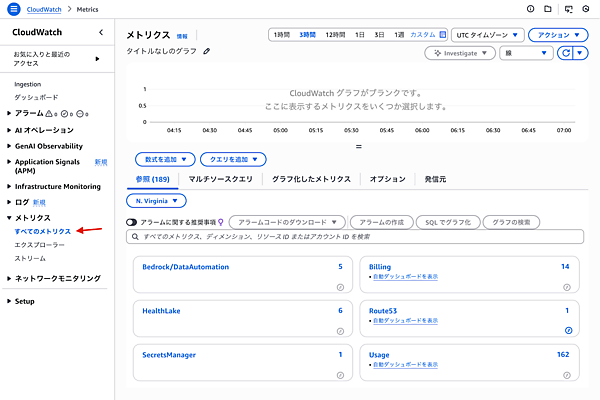
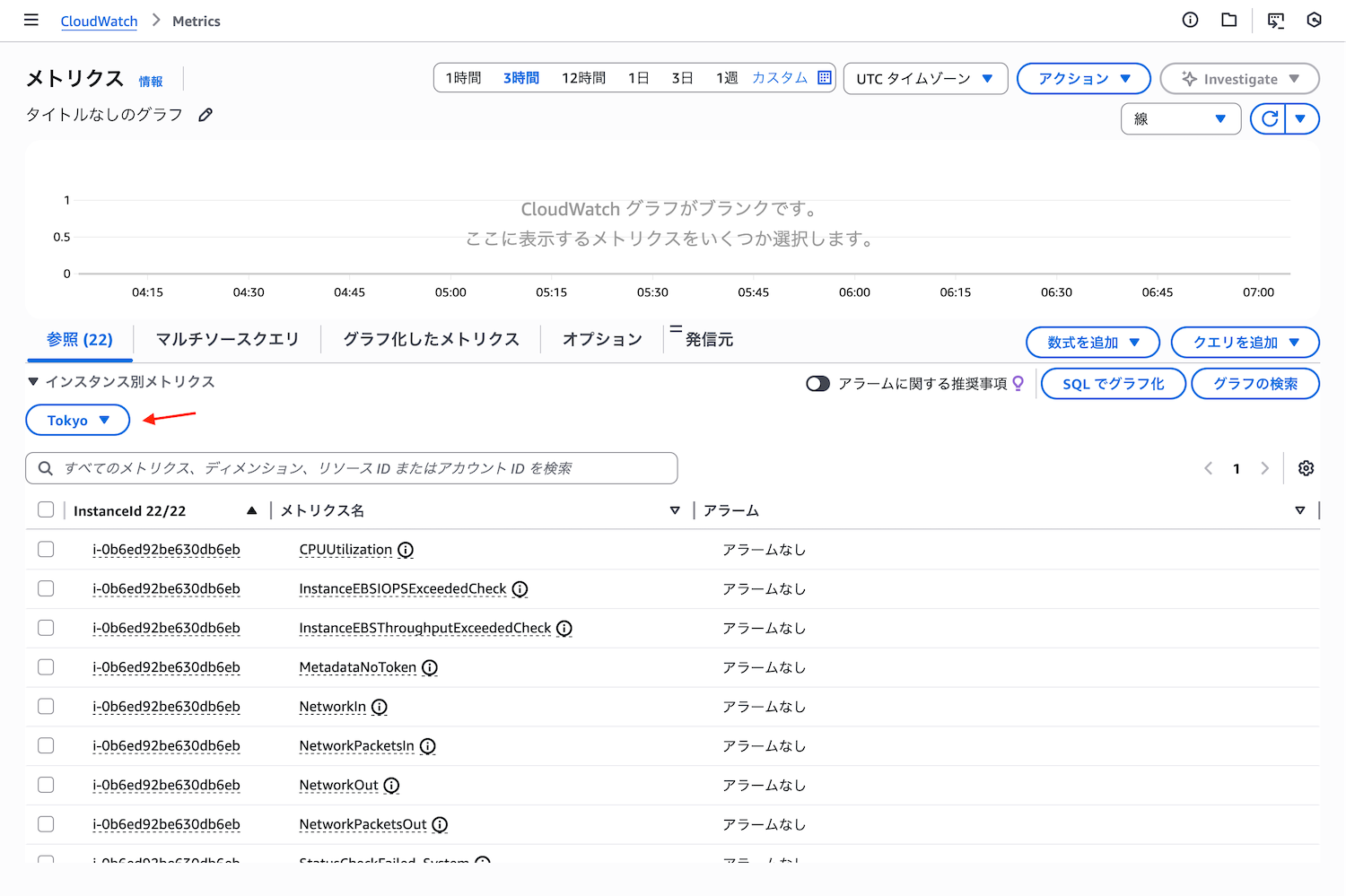
すべてのメトリクスを選択した画面 - 「EC2」→「インスタンス別メトリクス」を選択すると、EKSノードとして動作しているEC2インスタンスのメトリクスが表示されます。目的のメトリクスが表示されない場合は、リージョンが間違っているかもしれません。画像の赤矢印の部分のリージョンを確認してください。
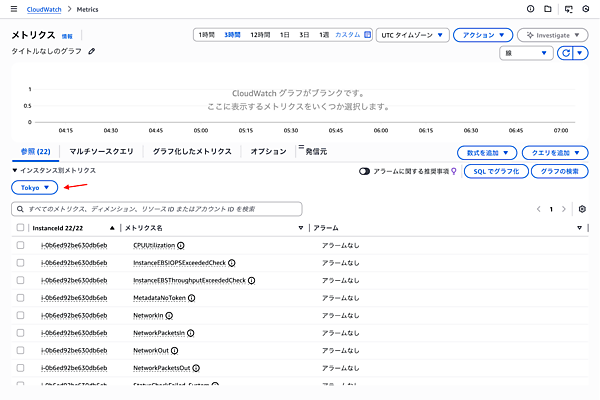
EC2 インスタンス別メトリクスを選択した画面 - 例えば、
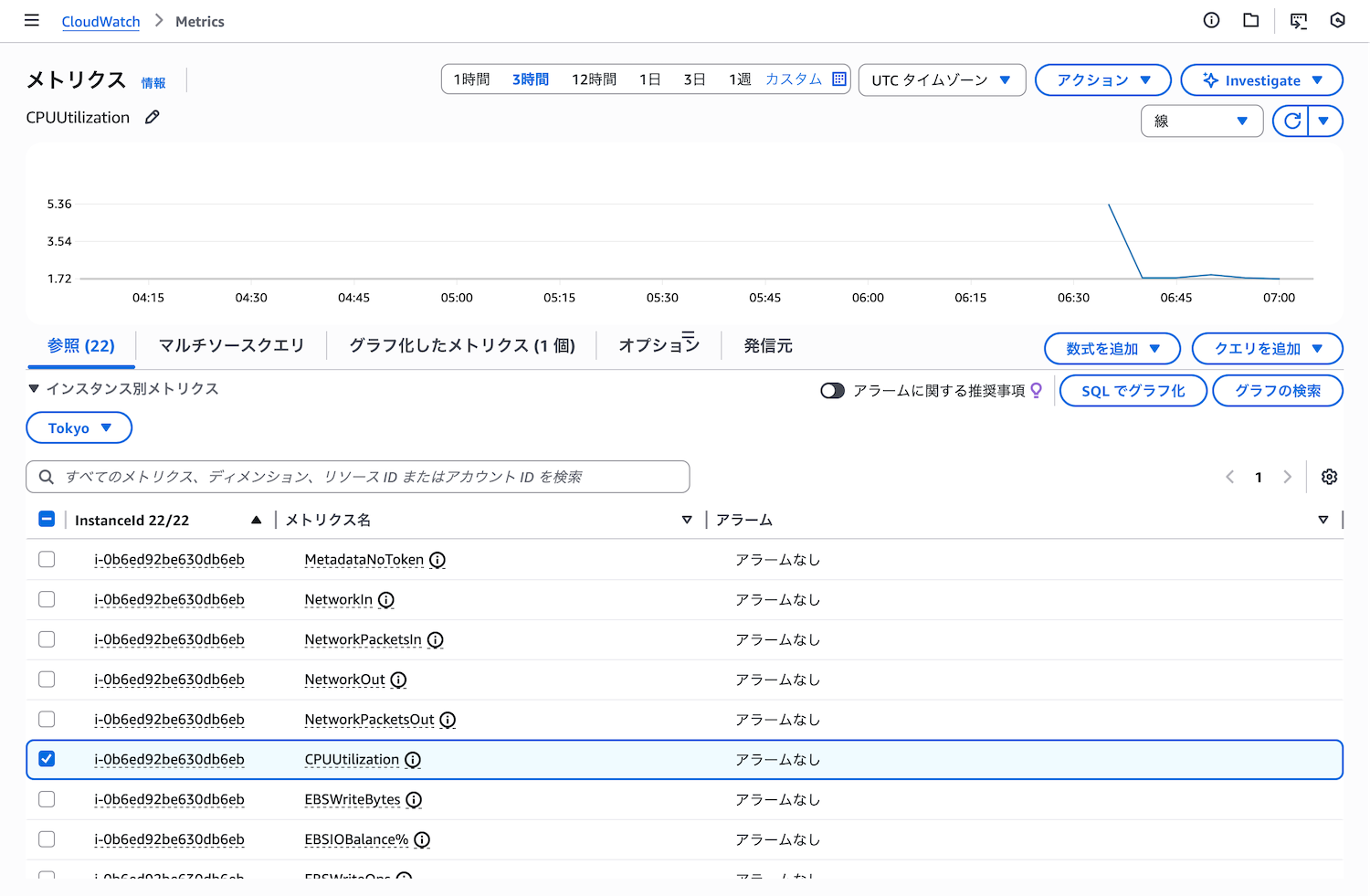
CPUUtilizationメトリクスを選択すると、過去の時間帯のCPU使用率がグラフで表示されます。デフォルトでは過去3時間のデータが表示されますが、期間を変更することで、過去1日、1週間、1か月などのデータも確認できます。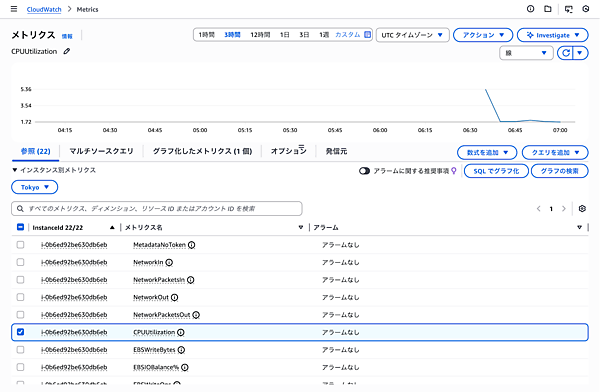
CPUUtilizationメトリクスを選択した画面
メトリクスの統計とグラフ
CloudWatchでは、メトリクスの統計方法を選択できます。
- Average(平均): 期間内のメトリクス値の平均
- Sum(合計): 期間内のメトリクス値の合計
- Maximum(最大): 期間内のメトリクス値の最大値
- Minimum(最小): 期間内のメトリクス値の最小値
- SampleCount(サンプル数): 期間内のデータポイント数
CPU使用率やメモリ使用率には通常「Average」を使用しますが、瞬間的なスパイクを検知したい場合は「Maximum」を使用します。
CloudWatchダッシュボードの作成
ダッシュボードとは
「CloudWatchダッシュボード」は、複数のメトリクスを1つの画面で可視化する機能です。EKSクラスターの健全性を一目で確認できるように、CPU使用率、メモリ使用率、ネットワークトラフィックなどを1つのダッシュボードにまとめます。
3つのダッシュボードまで無料で作成できます(各ダッシュボードは最大50メトリクスまで参照可能)。4つ目から1ダッシュボードあたり$3.00/月の料金がかかることに注意してください。詳しくは公式ドキュメントをご覧ください。
ダッシュボードの作成手順
CloudWatchコンソールの左側メニューから「ダッシュボード」を選択し、「ダッシュボードの作成」をクリックします。
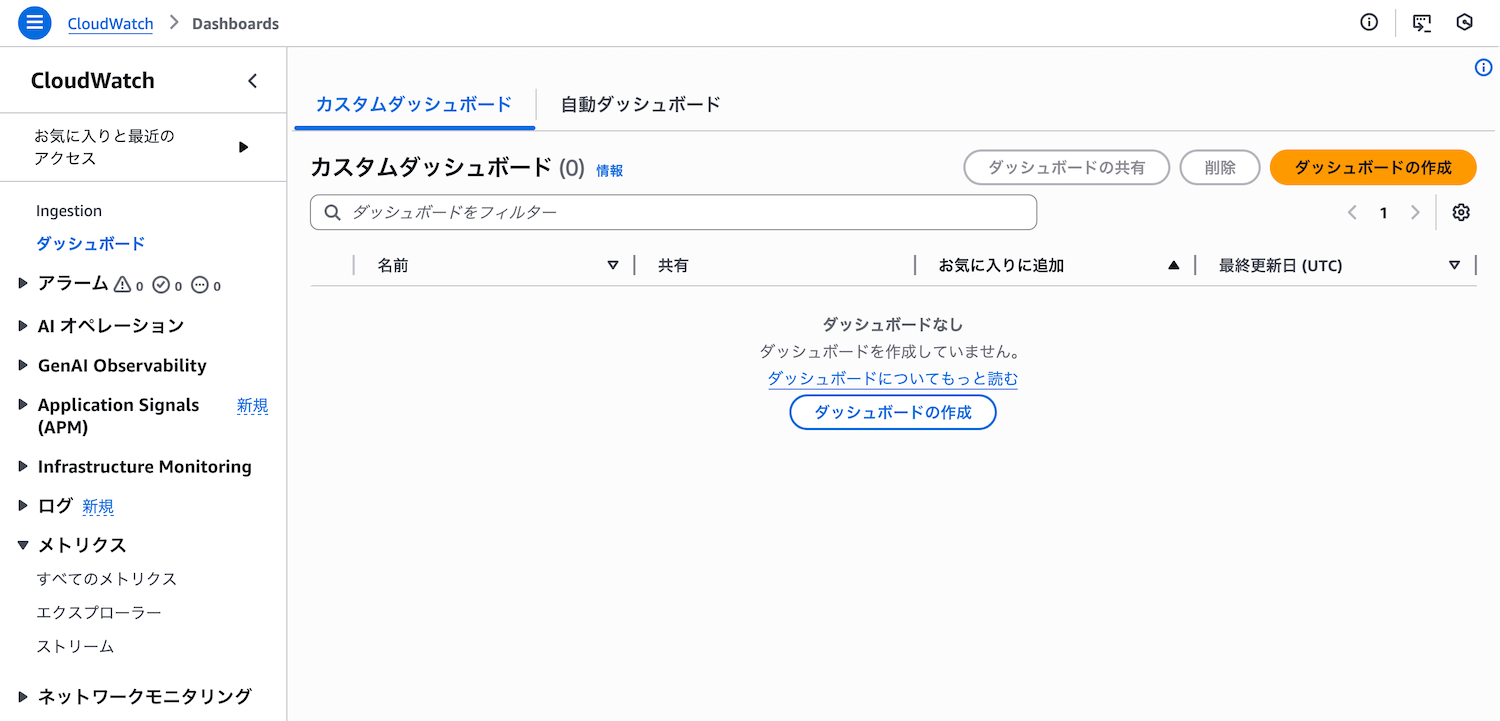
ステップ1: ダッシュボード名の設定
ダッシュボード名を入力します。例えば、DevEKS(開発環境用)、ProdEKS(本番環境用)のように環境ごとに作成します。今回は開発環境用のダッシュボードを作成します。
ステップ2: ウィジェットの追加
ダッシュボード名を決定した後、そのままウィジェットの追加画面に遷移します。もし遷移しなければ「ウィジェットの追加」をクリックし、「線」を選択します。
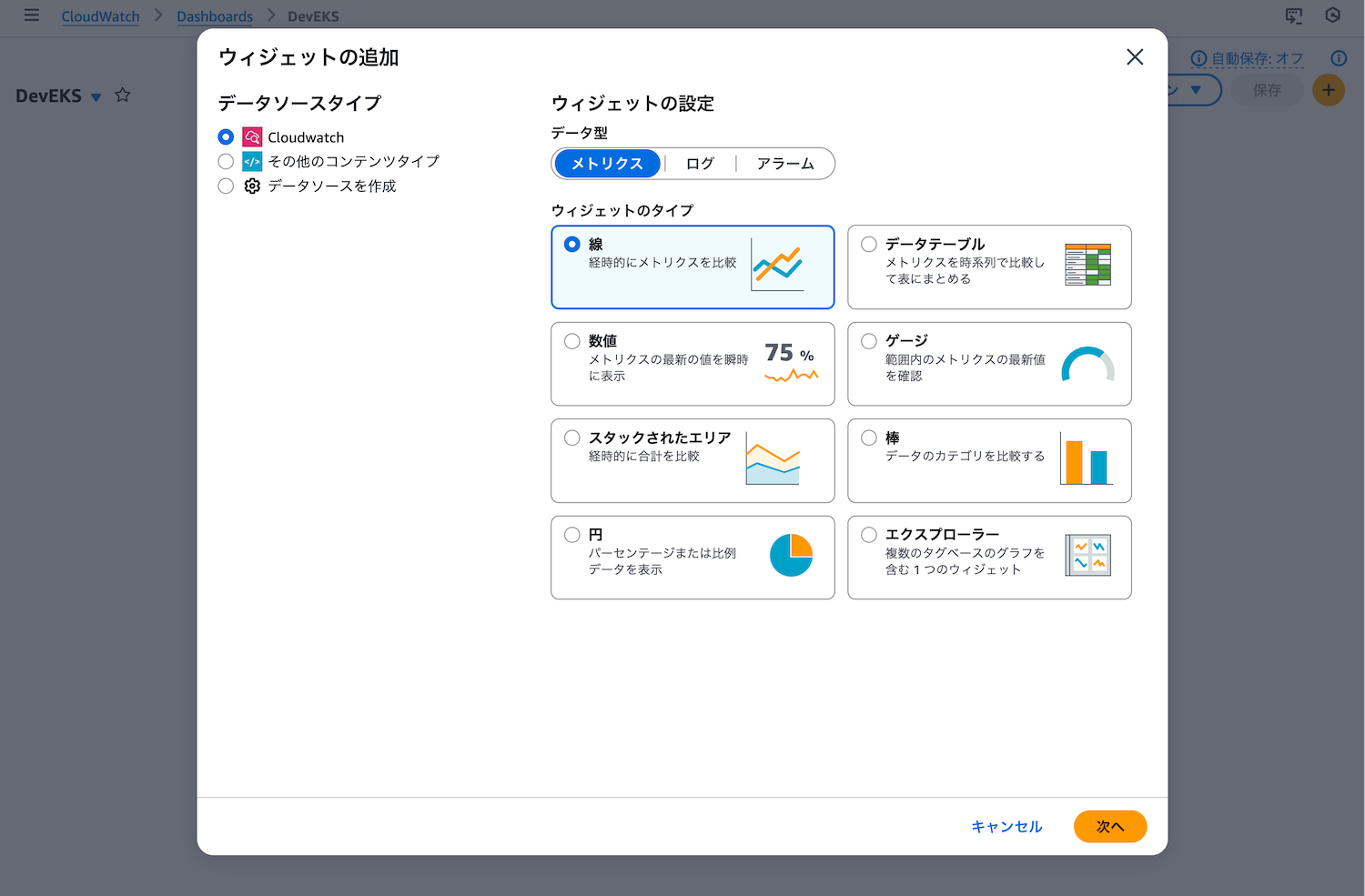
- 「メトリクス」タブで「EC2」→「Auto Scaling グループ別」を選択
- 検索窓に「dev」と入力
CPUUtilizationを選択- 「グラフ化したメトリクス」タブを選択
- 統計を「平均」、期間を「5分」に設定
- ウィジェットの作成をクリック
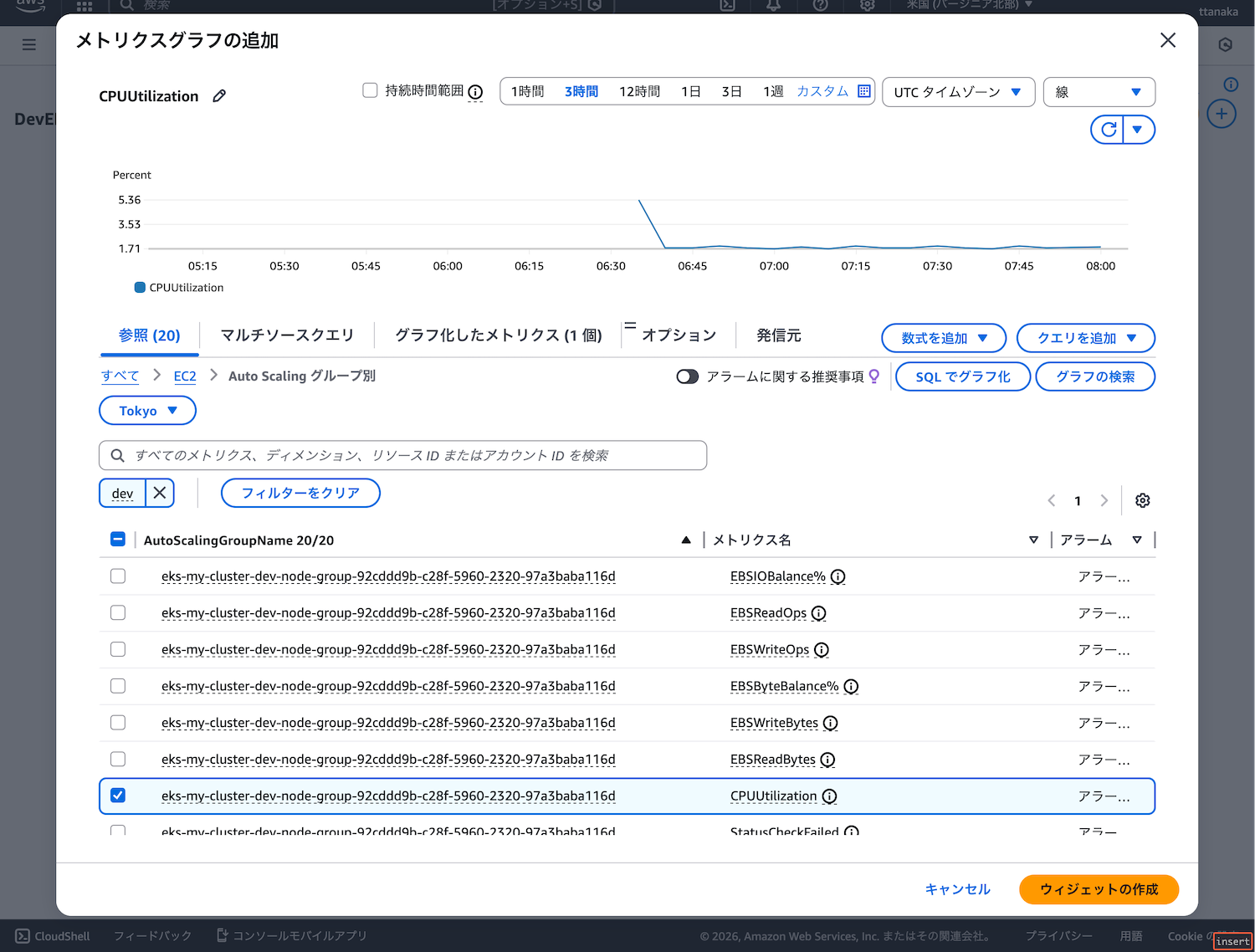
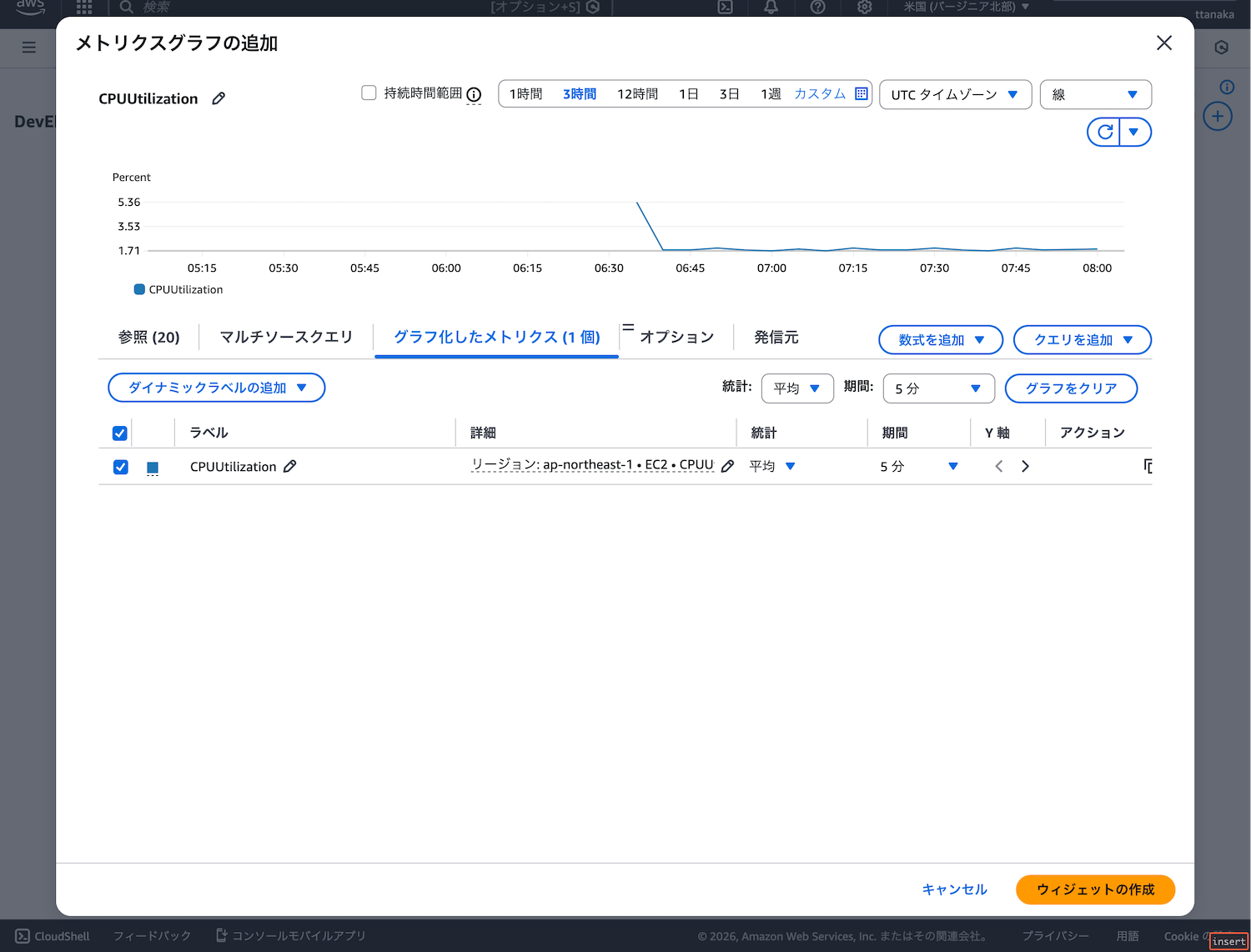
今回の手順でいくつか補足しておきます。まず、手順1で監視するメトリクスを「Auto Scaling グループ別」にしました。
EKSのノードはAuto Scaling Groupで管理され、自動で増減されます。「インスタンス別」で監視すると、オートスケール時に新規ノードが監視対象外になったり、削除済みノードが残ったりする問題が発生します。「Auto Scaling グループ別」にすることで、ノードの増減に自動で追従できます。
開発環境のAuto Scaling Group名には「dev」という文字が含まれているため、手順2でこれを検索しました。環境やリソースが増えると目的のメトリクスを探すのが大変なので、リソース名で絞り込むと良いでしょう。
メモリ使用率ウィジェット(CloudWatch Agent使用時)
メモリ使用率を監視するには、EKSノードに「CloudWatch Agent」をインストールする必要があります。CloudWatch Agentは追加の設定が必要なため、本記事では扱いません。本番環境ではメモリ監視の導入を検討してください。
- 同様の手順で「NetworkIn」と「NetworkOut」を選択
- 統計を「合計」に設定(トラフィック量の合計を確認)
- 「NetworkOut」のY軸を右に設定(「>」をクリック)
- ウィジェットの作成をクリック
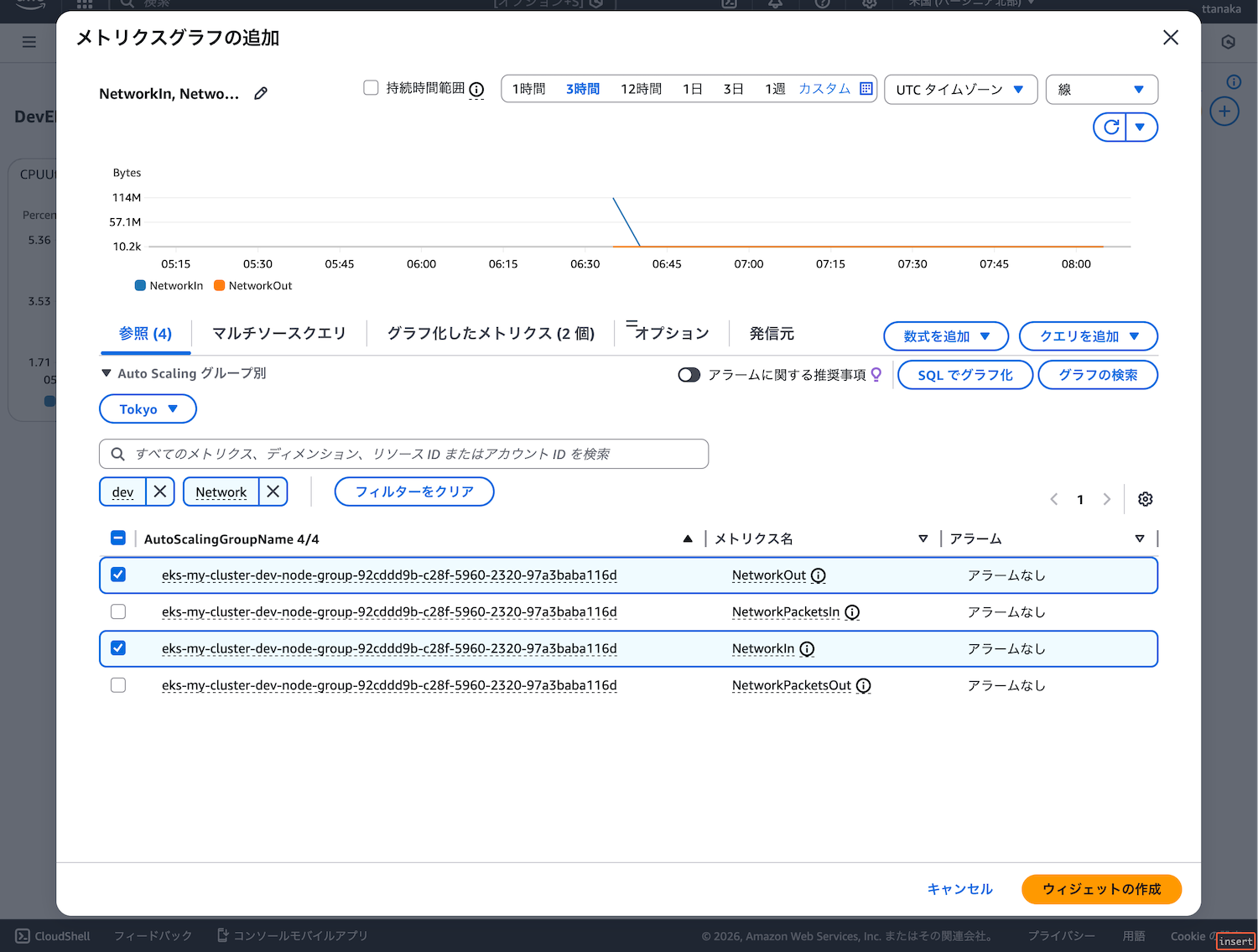
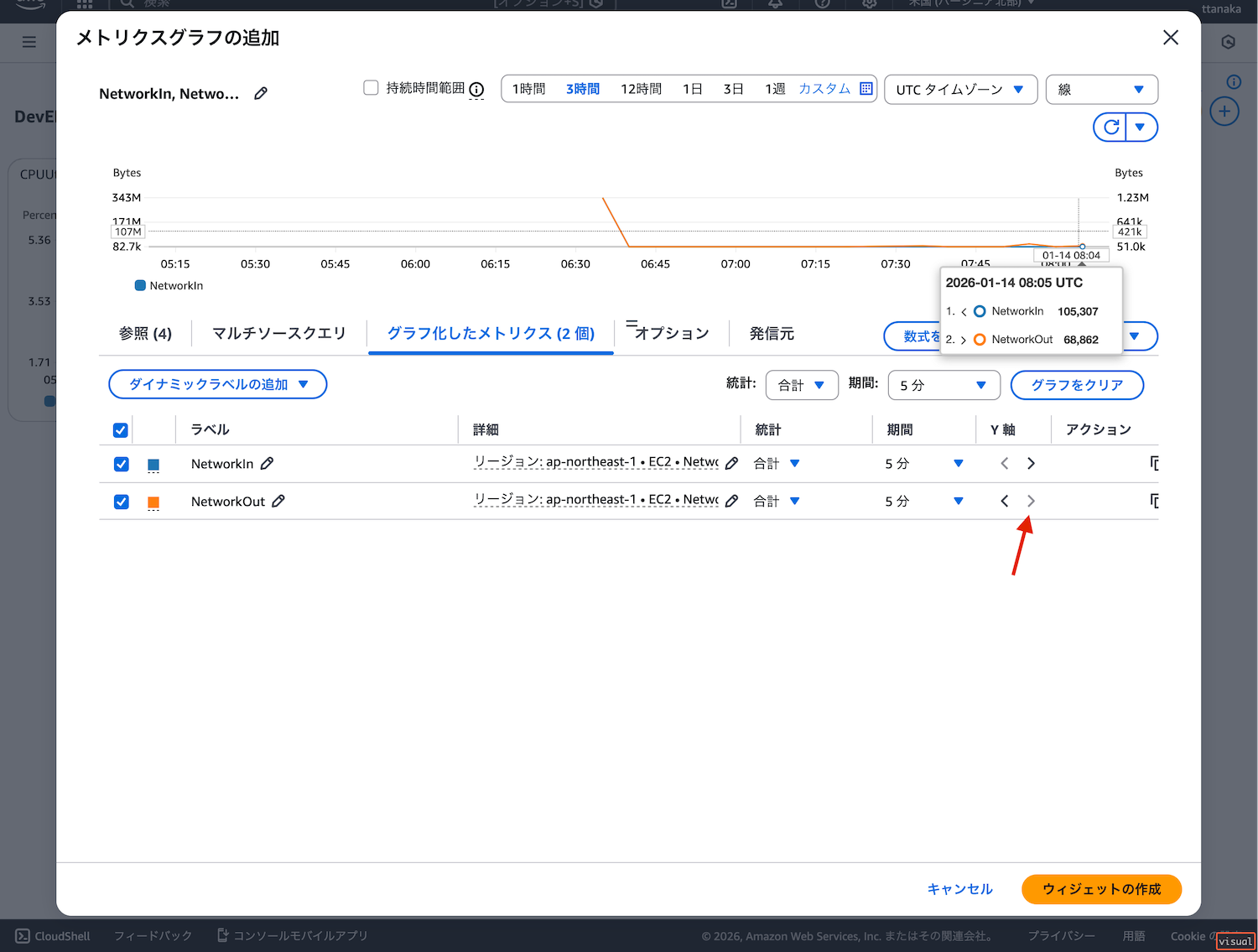
なぜY軸を変更したのか補足します。今回はNetworkInとNetworkOutのメトリクスを1つのグラフで表示しています。デフォルトの状態ではY軸は両方とも左です。2つのメトリクスが概ね同じくらいの数値であれば問題ありません。しかし、数値に極端な差がある場合、数値の小さい方のデータが水平な直線に見えてしまいます。
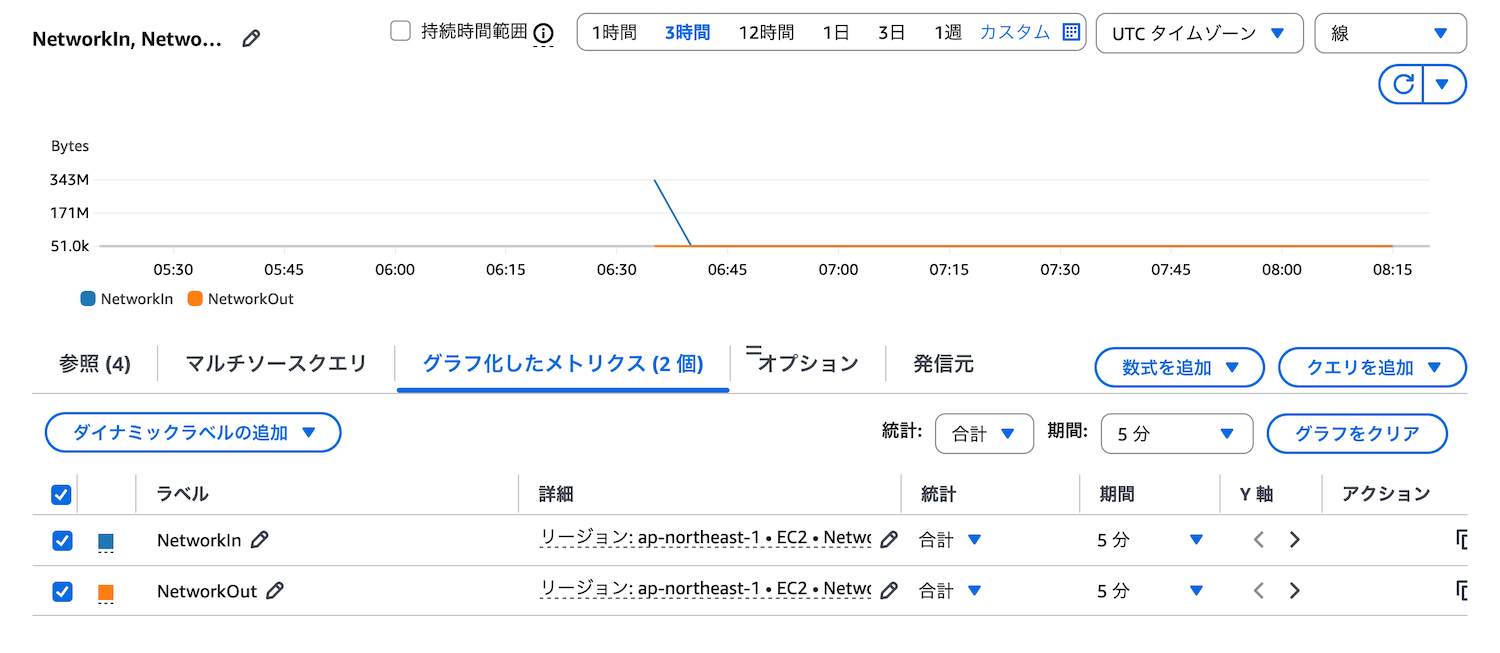
この図ではY軸を両方とも左に設定してあります。6:45から一直線で安定しているように見えるでしょう。
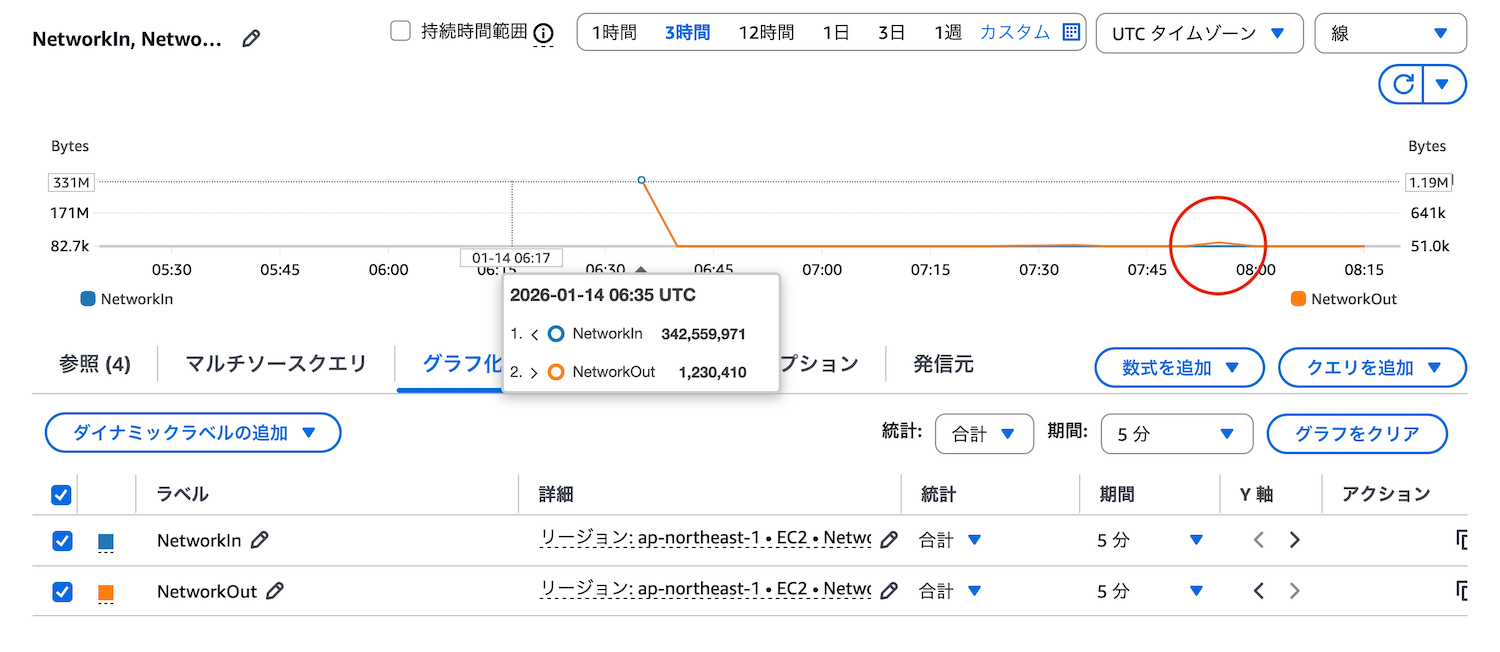
こちらがY軸を左右に設定した図です。7:45〜8:00の間でNetworkOutが少し跳ねているように見えます。Y軸の単位を見てください。左軸は331Mを表し、右軸は1.19Mを表しています。InとOutで300倍ほど数値に差があるため、両方のグラフを左軸で表示した場合、数値の小さい方が一直線となっていました。
ステップ3: ダッシュボードのレイアウト調整
ウィジェットをドラッグ&ドロップで配置し、サイズを調整します。通常、CPU使用率を最上部に配置し、その下にネットワークトラフィックを配置すると見やすくなります。
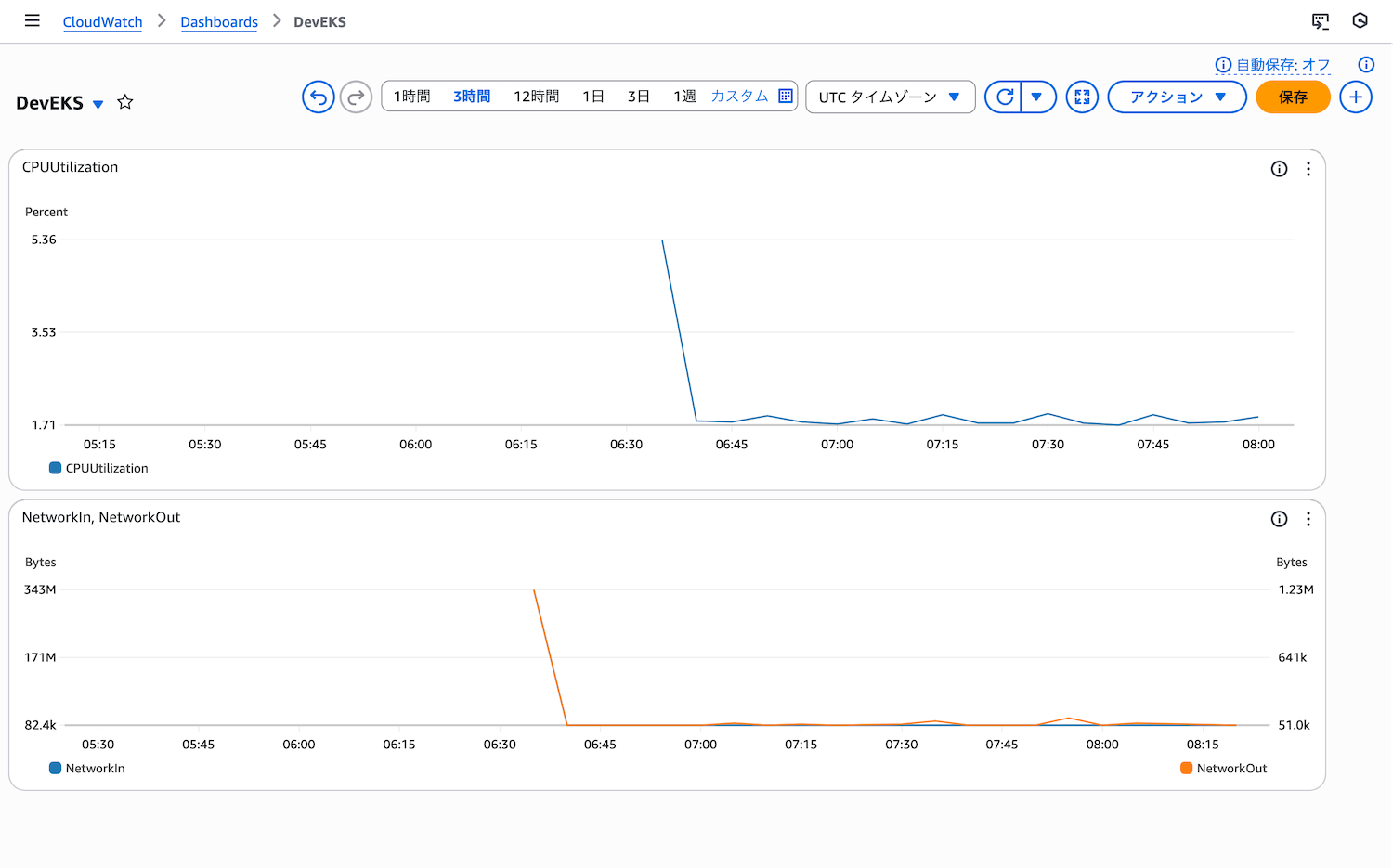
ステップ4: ダッシュボードの保存
右上の「ダッシュボードを保存」をクリックして保存します。
ダッシュボードの活用
作成したダッシュボードのURLを共有することで、チームメンバー全員が同じダッシュボードを閲覧できます。また、ダッシュボードは自動的に更新されるため、常に最新のメトリクスを確認できます。更新間隔はデフォルトで1分ですが、10秒、30秒、5分などに変更できます。
監視のベストプラクティス
監視対象の優先順位付け
すべてのメトリクスを同じ重要度で監視するのではなく、ビジネスへの影響度に応じて優先順位を付けることが重要です。
【優先度の高いメトリクス】- CPU使用率: アプリケーションのパフォーマンスに直接影響
- メモリ使用率: メモリ不足でPodが強制終了される可能性
- ネットワークエラー: 通信障害の兆候
- ネットワークトラフィック量: コストとパフォーマンスに影響
- ディスクI/O: ストレージボトルネックの検出
適切なモニタリング間隔の設定
メトリクスの収集間隔と表示期間は、監視目的に応じて調整します。
- リアルタイム監視: 1分間隔、過去1時間を表示
- 日次レビュー: 5分間隔、過去24時間を表示
- 長期トレンド分析: 1時間間隔、過去1週間〜1か月を表示
ダッシュボードの整理
ダッシュボードが増えすぎると、どのダッシュボードを見れば良いか分からなくなります。以下のように整理することをお勧めします。
- 概要ダッシュボード: 全体の健全性を一目で確認
- 環境別ダッシュボード: 開発、ステージング、本番など環境ごとに作成
- サービス別ダッシュボード: EKS、RDS、ALBなどサービスごとに作成
定期的なレビュー
ダッシュボードの設定は、定期的に見直す必要があります。アプリケーションの成長に伴って新しいメトリクスを追加したり、不要なメトリクスを削除したりします。
週次または月次でダッシュボードを確認し、以下の点をチェックします。
- 監視対象のリソースが増減していないか
- 表示期間や統計方法が適切か
- 新しいメトリクスを追加する必要があるか
ログとメトリクスの相関分析
メトリクスで異常を検知したら、CloudWatch Logsでアプリケーションログを確認することで、根本原因を特定できます。例えば、CPU使用率が急増した場合、アプリケーションログを確認することで、特定のAPIエンドポイントへのリクエストが急増していることを発見できます。
「CloudWatch Logs Insights」を使うと、ログを簡単にクエリできます。
fields @timestamp, @message
| filter @message like /error/
| sort @timestamp desc
| limit 100おわりに
本記事では、AWS CloudWatchを使ったEKSクラスターの監視方法を学びました。
CloudWatchでEC2インスタンス(EKSノード)のメトリクスを収集し、CPU使用率やネットワークトラフィックを監視する方法を解説しました。CloudWatchダッシュボードを作成することで複数のメトリクスを1つの画面で可視化し、インフラの健全性を一目で確認できるようになりました。
これらの監視手法により、以下のことを実現できます。
- インフラの可視化: メトリクスをグラフで可視化し、トレンドを把握
- チーム全体での状況共有: ダッシュボードを共有することで、全員が同じ情報を確認
- パフォーマンスの最適化: メトリクスを分析し、リソースの適切なサイジングを実現
ただし、ダッシュボードを定期的に確認するだけでは、問題の検知が遅れる可能性があります。24時間365日ダッシュボードを監視し続けることは現実的ではありません。
次回は、CloudWatchアラームを使った自動通知の設定について解説します。しきい値を超えたときに自動的にメールやSlackに通知を送ることで問題を早期に検知し、迅速に対応できる仕組みを学びます。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
「Terraform」のコードを自分で書けるようになろう
2024年5月7日 6:30
WSLとWindowsの設定ファイルを「chezmoi」を使って安全に管理しよう
2025年2月19日 6:30
バージョン管理を柔軟に! プロジェクト単位で「asdf」を使いこなす
2025年5月7日 6:30
インフラエンジニアの視点で見る、DevOpsを実現するためのツールとは
2023年5月16日 6:30
CI/CDを実現するツール「GitHub Actions」を使ってみよう
2024年6月27日 10:13
WSLで「direnv」を活用してプロジェクト単位で環境変数を管理しよう
2025年5月27日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
