パリで開催されたAI_dev Europe 2024から、各社の生成型AIがどれだけオープンなのかをモデル、データセット、リワード、データ処理のためのコードなどのポイントについて評価を解説するセッションを紹介する。セッションを担当したのはRaphael Semeteys氏、所属はWorldlineというフランスの電子決済のためのプラットフォームを開発運営する企業で、Developer Relationsのトップでもあるシニアアーキテクトだ。動画は以下から参照可能だ。
●動画:From OpenAI to Opensource AI: Navigating Between Commercial Ownership and Collaborative Openness
タイトルは「From OpenAI to Open Source AI : Navigating between Commercial Ownership and Collaborative Openness」2024年6月時点で存在する大規模言語モデル(Large Language Model)についてそのオープンの度合いを解説する内容だ。このカンファレンスではすでにGenerative AI CommonsがModel Openness Framework(MOF)を公開しているが、それとはまた異なる観点で整理していることに注目したい。

プレゼンテーションを行うSemeteys氏
まずはLLMの過去の進化を振り返り、2020年代では生成型AIに注目が集まるものの信頼性についてはまだ多くの課題があると説明。この認識は多くのプレゼンテーターが指摘している部分だ。MOFは信頼性以前にまずはオープンであるかどうかの指針を定義したという段階であり、信頼性を高めるための努力は各ベンダーや大学などの研究機関に委ねられているということだろう。

AIの進化を2010年代から振り返る
そして生成型AIはかつてのLinuxが経験したような状態になっていると語った。特にオープンソースにおいてさまざまなライセンスが登場し、結果としてライセンスが求める内容に関しての透明性が課題となっていると説明した。

生成型AIはLinuxのようなモメンタムを迎えていると説明
次に生成型AIが開発される流れを説明するチャートを使ってモデルがトレーニングされる段階ごとにデータセットやリワードが使われるということを解説。ここでは3つの段階に分けて説明している。最初の段階は基礎となるモデルを使ってモデルを作り、その後、ファインチューニングが行われ、最後に人間からのフィードバックを使った強化学習が行われるという内容だ。最後の段階で正しい結果に報酬を与えるリワードモデルが追加されていることがわかる。
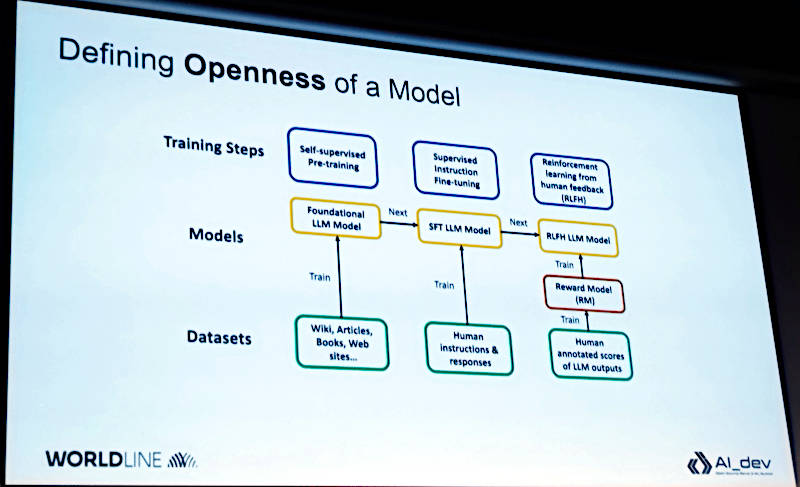
モデルの作られ方を3つの段階に分けて説明
そのチャートにグレイの色付けをしてモデル、リワードモデル、学習前のデータセット、ファインチューニング後のデータセット、データ処理のためのプログラムコードというカテゴリー分けを行っている。ここはMOFとの違いがかなり明確になる根幹となる部分だろう。MOFではLLMのアーキテクチャーやトレーニングや推論のためのコード、ドキュメントなども評価の範囲となっているが、ここではそこまでの細かな分類は存在していない。
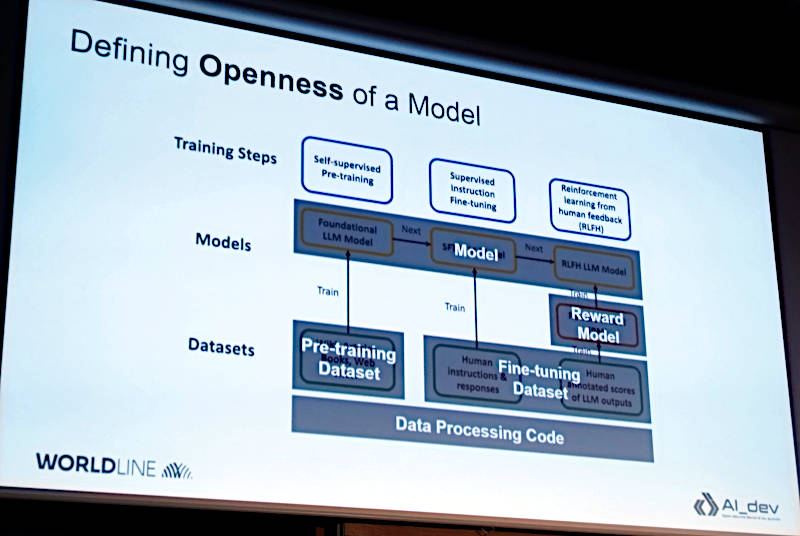
モデルの開発の対象をグレーで色分けして分類
そしてオープンの度合いのランクを5段階に分けて整理を行うというのがこのセッションの中核のポイントだ。
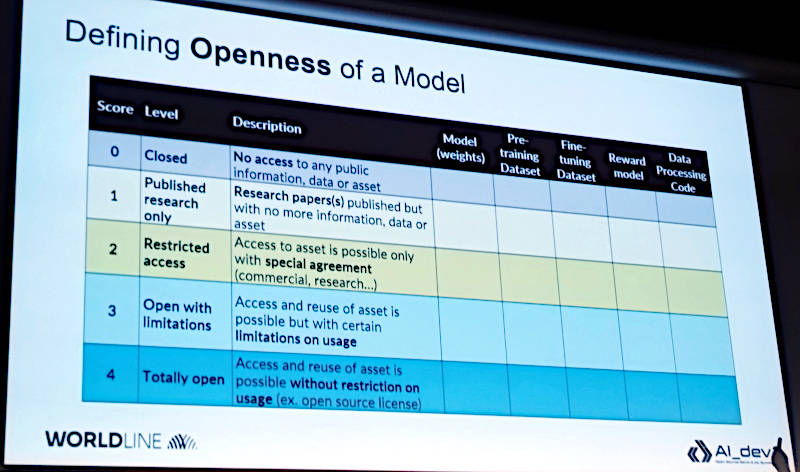
オープンの度合いを5段階で整理。5つのカテゴリーに適用する方法
ここからは具体的に対象を絞ってそのオープンさを解説する段階となった。最初に挙げられたのはOpenAIだ。

市場を牽引するリーダーと位置付けられたOpenAI
ここでGPT-1、2ではモデル自体はオープンであったが、進化したGPT-3以降は研究のための論文だけが公開され、それ以外は完全にクローズドな状態になっていると説明。

特に問題なのは利用に関してOpenAIと競合することを禁止する条項が入ったこと
次のスライドではOpenAIと競合するようなビジネスでは利用を禁止するという条項が追加されたことを説明した。つまり、他のビジネス利用を目的としたLLMのトレーニングのためには使えないということを意味していると語った。

同じくマーケットリーダーのGoogleについて説明
GoogleについてもBERTの段階ではモデルやコードはオープンであったが、Gemini、Gemmaと進化するに従ってクローズドな状態に近付いていると説明。

違法行為や暴力、人権侵害などに繋がる用途には使えないなどの規制対象となる行為を列挙している
ここでは違法行為や暴力、人権侵害などに繋がる用途には使えないなどの規制対象が追加されたことを説明。競合するビジネスに使えないというOpenAIよりも倫理的だが、そもそものオープンソースの定義とは異なることを解説した。
他のビッグプレイヤーについても説明。現状を生成型AIのゴールドラッシュと表現
次に触れたのはMetaだ。

Metaについて解説。当初のオープンな状態からは後退している
MetaはRoBERTaからLlaMAに推移していく中で、データセットやコードについてはクローズドな状態になっていると説明。

月間のアクティブユーザーが7億人を超えると別のライセンスが必要
また月間のアクティブユーザーが7億人を超えるような場合についてはMetaから別のライセンスを取得する必要があるという条項が追加されたとして、利用については制約があることを説明した。

再利用についても「LlaMA 3」を各所に明記する必要がある条項を追加
ここではMetaは、再利用するユーザーにベースとなっている「LlaMA 3」の存在を明らかにすることを強いる条項を追加していると説明。ここでもオープンではあるが制約が発生していることを強調した。
続いてLlama 2から派生し、スタンフォード大などで研究が進んでいるAlpacaやVicunaなどについて説明を行った。

Llama 2から派生したモデルについて説明
これらのモデルはベースとなっているモデル、ここではMetaのLlama 2とOpenAIのShareGPTからの制約が発生することに注意しなければいけないと説明した。

その他のモデルについても説明。UAEのFalconやフランスのMistral AIのモデルについても触れている
ただしそれらのモデルについては、Apache 2.0のライセンスをベースとしているもののより詳しく読み込んで理解する必要があることを説明した。ここでの例はFalcon 180Bというモデルについて追加された内容を示している。

Apache 2.0を部分的に改変したライセンスが使われるFalconのモデル
Worldlineがフランスの企業であるためか、Mistral AIについても触れている。

Mistral AIについてはパブリッククラウドベンダーがマネタイズしないように制約を追加
「フレンチソース」という言葉を使ってさまざまな食材のエッセンスを混ぜ込んだライセンスと自虐的に紹介しているが、Mistral AIはパブリッククラウドベンダーがマネタイズのために使うことを禁じている。ここでは有償か無償かを問わず、利用できないような制限を明記しているのがポイントだろう。

その他の派生したLLMについても解説
ここでもライセンスに追加の条項が発生している例を説明。ここでは軍関係での利用を制約する条項のようだ。この条項を作っているのはAllen Insutitute for Artificial Intelligence (AI2)という組織のようだ。
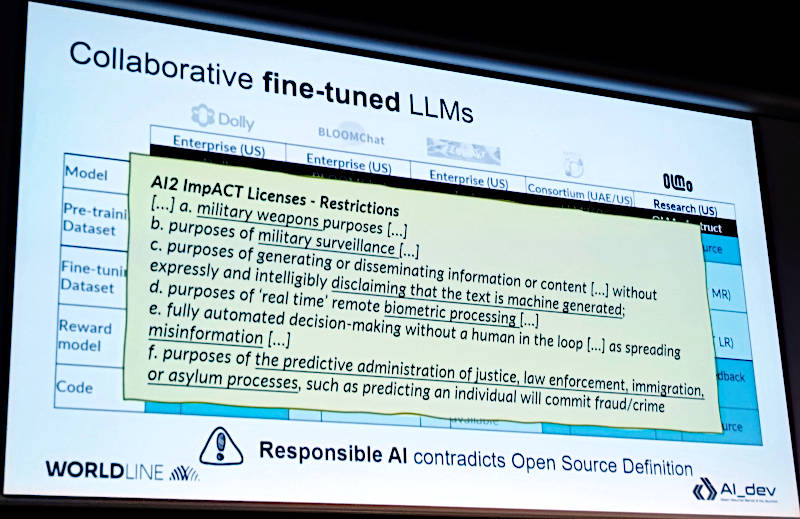
軍関係での利用を制限するライセンスの例
●参考:The AI2 ImpACT License Project: Open, Responsible AI Licenses for the Common Good
またモデル以外の要素についても説明を行った。ここではRed Hatが発表したInstructlab、Hugging Faceなどのコラボレーション、そしてAIチップの開発と利用の拡大、オープンソースのツールやフレームワークなど多くの要素や使われ方が増えていることに触れた。そしてこの変化を、趣味のOSだったLinuxがサーバーから組込系まで拡がっていった発展の仕方と似ていることを指摘した。テクノロジーの民主化と非中央集権的な管理体制という側面ではよく似ているという内容だ。

Linuxと同様にエコシステムが拡大している生成型AI
最後にこのセッションのまとめとしてクローズドなAPIからオープンに移行していく中で、無料ではなく自由なAIが達成されること、オープンな研究によって利用が拡がり、より競合の多い市場環境を経てお互いが競争するのではなく協力して開発するという方向に行って欲しいという願望も込めた内容を説明してセッションを終えた。
ちなみにMOFのセッションで紹介されたカテゴリー分けをここにも残しておこう。

Generative AI Commonsが発表したMOFのコンポーネント
Semeteys氏の分類との違いはドキュメントや構成ファイルなどが含まれていることで、エンジニアが作成に関わったことが感じられる内容になっている。オープンの度合いについてはクラスとして表現され5段階ではなく3段階となっている。

オープンの度合いを3段階で表現
多くの企業がどのモデルを選べば良いのか、ライセンスにはどんな制約があるのかを吟味している段階が2024年ということだろう。しかし開発の状況やライセンスについても日々変革が起こっているのが生成型AIのランドスケープと言える。2024年7月23日にMetaが発表したLlama 3.1は性能だけではなくオープンソースとして公開されるLLMの優位性を訴求する内容になっており、どのモデルを使うべきか悩みは尽きないというのが現状だろう。引き続き注目していきたい。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
