AI_dev Europe 2024開催、キーノートとMOFを解説したセッションを紹介
生成型AIに特化したカンファレンスAI_dev Europe 2024から、生成型AIのオープン度を判定するMOFを解説する
2024年8月21日 6:00
The Linux Foundation(LF)が主催する生成型AIに特化したカンファレンスAI_devが2024年6月19日、20日の両日にパリで開催された。会場はパリ5区にあるMaison de la Mutualiteというところで、今回のようなカンファレンスだけではなくライブや演劇なども開催される建物である。メインとなった地下1階のシアターは、キャバレーのような舞台も用意できるしつらえになっていた。

AI_devが行われた会場の外観

地下1階のメインシアター。丸いテーブルに椅子がキャバレー的
キーノート
最初に行われたキーノートではLF AI&Data FoundationのエグゼクティブディレクターであるIbrahim Haddad氏が登壇し、スポンサーへの謝辞、LF AI&Data Foundationの概略などを語った後に現在の生成型AIが抱える問題点を解説した。この記事ではキーノートとそこで紹介された新しいフレームワークのModel Openness Frameworkの解説セッションを合わせて紹介したい。
●初日のキーノートの動画:Keynote: Welcome & Opening Remarks

キーノートに登壇したLF AI&Data FoundationのIbrahim Haddad氏
ここではソースコードがメインの現在のオープンソースソフトウェアと比べて、生成型AIに関する「オープンの定義」が定まっていないこと、従来のOSSのライセンスをソースコードではないデータセットなどのアーティファクトに適用していること、利用に関するさまざまな制約が存在すること、モデルに関するさまざまなコンポーネントが公開されていないことなどを課題として挙げた。

生成型AIに関する「オープン」の問題点
その現状を改善するためにModel Openness Framework(MOF)を発表し、第3者が生成型AIのモデルとそれに関連するコンポーネントなどの「オープン」の度合いを比較検証できる仕組みを作ったと説明した。

MOFを発表
MOFが検証する「オープン」の度合いはソフトウェア、データモデル、ドキュメントの3つに分かれており、それぞれについてさらに細分化したサブコンポーネントが定義されている。

MOFのコンポーネント
またオープンの度合いについては3つの段階で評価されるとしている。クラス3が最も低くアーキテクチャーや評価結果などが公開されていること、クラス2がクラス3に加えてトレーニングや推論のためのコード及びライブラリーやツールなどのコードが公開されていることが条件となっている。また最もレベルの高いクラス1では研究論文が存在すること、データセットそのものとデータセットを準備するためのコード、モデルのパラメータなどが公開されていることが条件となる。

MOFのクラス分けを解説。一番上が「Open Science」と称されている
このOpen Scienceについては後半でより詳しく紹介するが、ここではMOFのためのツールModel Openness Toolを紹介。すでにベータ版として公開されており、多くのモデルがMOTを使ってオープンの度合いを公開している。
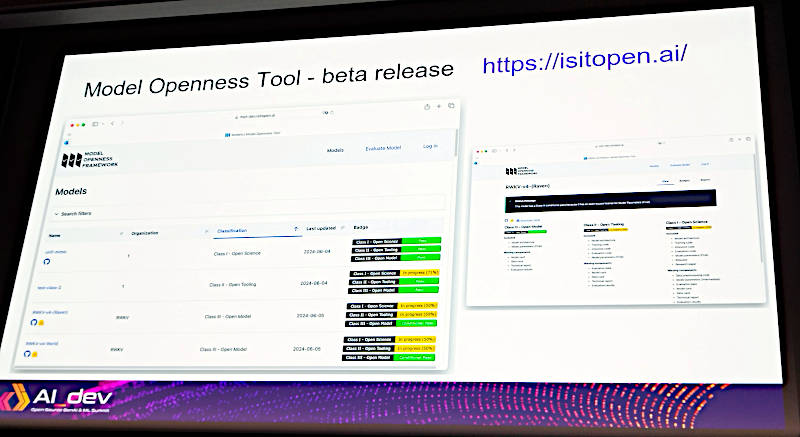
MOTのスクリーンショットで簡単にツールを紹介
MOTは以下のURLからアクセスできる。
●参考:MOT:https://isitopen.ai/
Model Openness Frameworkに関するセッション
ここからはMOFに関する別セッションから、その概要と問題点などを紹介する。セッションのタイトルは「Introducing Model Openness Framework : Achieving Completeness and Openness in a Confusing Generative AI landscape」という非常に長いもので要約すれば、「MOFによって混乱した生成型AIの世界に完全性とオープンさを導入する」となり、かなり大見えを切った感がある。
MOFの解説セッション。登壇者はLF AI&Data Foundationのメンバーだ
登壇者はGenerative AI Commons(GenAI Commons)のチェアパーソンであるFutureweiのAnni Lai氏、そしてCailean Osborne氏、Matt White氏の3名だ。Osborne氏はLFのリサーチャー、White氏はLFのGMでもあるが、PyTorch Foundationのエグゼクティブディレクターでもある人物だ。Generative AI CommonsはLF AI&Data Foundationの下部組織で、LF AI&Data Foundation自体がLF配下の組織であることを考えるとLFの一部と考えるのが妥当だろう。LFにはCNCFも含まれているが、Generative AI CommonsとCNCFはAIについてはかなりオーバーラップしている部分があるようにも思える。しかし、後に行ったIbrahim Haddad氏へのインタビューでは、両者は協調して活動しているとのことだ。

GenAI Commonsのミッション。倫理的で信頼できるAIを目指す
このスライドではGenAI Commonsの目的について説明している。倫理的で信頼できるAIの、オープンソースでの実装を支援するというのが目的であるという。

セッションが行われた部屋はかなり小さく参加者は30人程度か
Lai氏の後を引き継いだOsborne氏がオープンソースのAIについて課題を紹介。キーノートのHaddad氏のスライドよりもより具体的になっている。

オープンソースで開発されるAIの課題を紹介
ここではOpenAIという組織が存在するために「“Open” in AI」と記述されている。オープンソースのライセンスが不当に適用されていることなどの問題を挙げて説明した。
そしてオープンとプロプライエタリーのライセンスについて、具体的に名称を挙げて説明を行った。

オープンとプロプライエタリーのライセンスの例を紹介
ライセンスに関してはソフトウェアとライブラリー、ドキュメントなどが含まれているが、生成型AIのデータモデルについてはそのスコープに入っていないと説明。

従来のOSSライセンスがカバーする領域
しかし生成型AIに含まれる多くのコンポーネントについてはソースコード、データ、ドキュメントと種類を分けたとしても必要とするライセンスは異なり、それに追いついていないという。

生成型AIが含む多くのコンポーネントはライセンスに対する仕様が異なる
Model Openness Frameworkが生まれた背景は、このような状況を改善するための努力のひとつであると説明した。
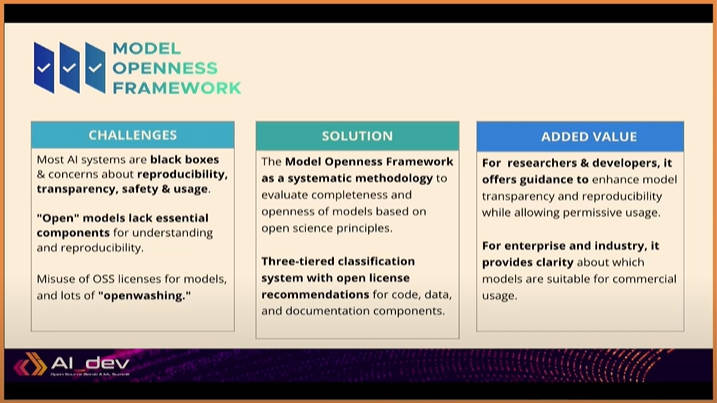
MOFが生まれた背景と解決策
多くのAIシステムがブラックボックス化しており、オープンではないモノに対してもオープンであるかのように宣伝されるオープンウォッシングが行われており、それを改善するためにMOFが開発されたことを説明。ここではトランスペアレンシー(透明性)とリプロダクティビティ(再現性)が課題と挙げられていることに注目したい。透明性は何が使われているのかといういわば成分を明らかにすることを、そして再現性は同じツールとデータを使えば同じ結果を再現できることを意味しており、ブラックボックス化しないためには必須の要件と言える。
そしてここでMOFのクラス1で出てきたOpen Scienceの解説を行った。

Open Scienceとは?
ここでは生成型AIをオープンサイエンス、つまり誰もがアクセスできる科学の一部として捉えている。科学論文の評価と同様のピアレビューやオープンな協業なども含まれているが、データに関してはオープンであることに加えて再利用、再配布を可能にするべきと言う内容も含まれている。

CompletenessとOpennessの概念を再度確認
セッションのタイトルにも含まれているCompletenessとOpennessについてここで説明を行い、生成型AIの評価は「完全性」と「オープンであること」の2つの軸で行うことがMOFの発想であることを説明した。

MOFの3つのクラスを解説
クラス3から必要なコンポーネントが徐々に増えて、クラス1に至ることで完全性とオープンの度合いが判定されるという仕組みだ。

実際にMOFの判定を行う際の手順を解説
ここからはMOFのツールであるModel Openess Toolを使って判定が行われる手順を簡単に説明した。実際のデモはこの後に登壇するWhite氏の担当だ。

MOFができないことを説明
まず、MOFが開発者とユーザーに与えるメリットを簡単に説明、その後で現状のMOFができないこと、制限される部分について解説を行った。ここでは「深層学習に特化していること」「プライバシーや著作権との兼ね合いでデータセットを公開することは困難である場合を想定していること」「バイアスや安全性についての指針ではないこと」「シンプル過ぎるゆえにカバーできないエリアがあり得ること」などを挙げた。
現状のの各モデルをMOFで検証する
ここからはWhite氏が登壇してMOTを実際に使って紹介するフェーズとなったが、機材のトラブルで質疑応答が行われた。
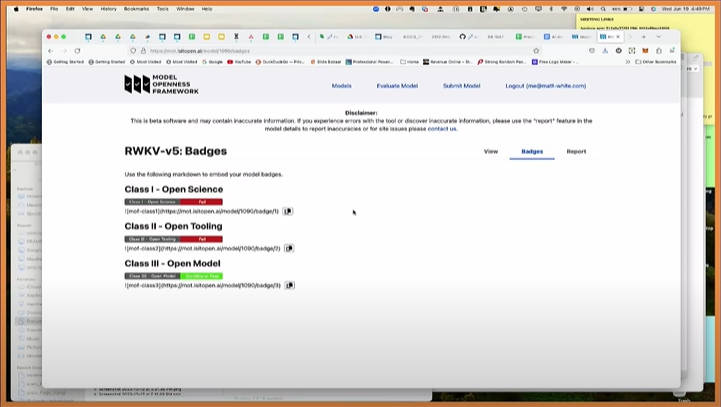
実際にMOFで検証された結果をバッジとして表示
ここではRWKV-v5を例に挙げてどのクラスを達成しているかをデモで見せている。
実際にMOTを利用するサイトで検索してみると、ほとんどのモデルがまだクラス3の途中までという段階なのがわかる。
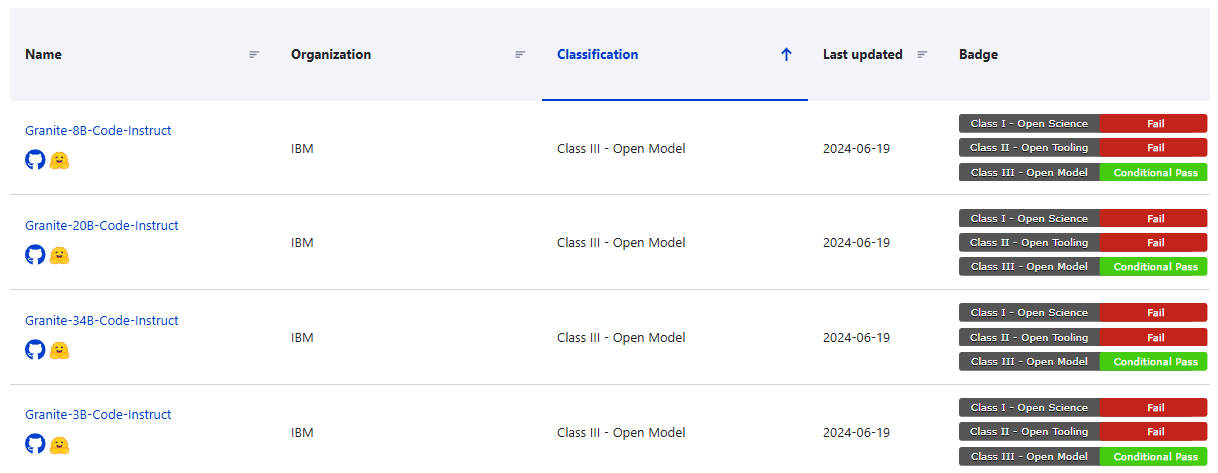
サイトから「IBM」で検索した結果。まだクラス3の途中という段階だ
上のスクリーンショットはIBMがRed Hat Summitで盛んにオープンソースのAIとして宣伝していたGraniteモデルについて検索を行った結果だが、まだクラス3の途中という段階だ。
このセッションではまだベータ版ということでこれからの改良を期待して欲しいというトーンで解説が行われたが、この新しい仕組みが本格的に広がるためには、何よりも開発を行う大学やベンダーにとって必要な評価とツールであるということを納得してもらう必要があるだろう。

現状、開発者にとってのメリットが少ない点はMOFの最大の懸念か
このスライドは開発者にとってのMOFの利点を整理したものだが、モデルをオープンにするガイドラインとなることが最初に挙げられており、そもそもそのガイドラインに沿って開発を行わなければいけない決定的な要因とはなっていない。また再現性やコラボレーションについても、一社で生成型AIによる利益を独占したい企業にとってみれば雑音だ。米国政府が調達にオープンソースソフトウェアであることを必須条件として挙げたことと比べたら、インパクトを感じられないというのが正直なところだろう。またMOFによって信頼できる倫理的なAIが達成できるかどうかについては何の担保もないと言える。特にこの部分が今後どのように深まっていくのか、引き続き注目したい。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
