Cloud Datastoreとは
Cloud Datastoreは、Google Cloud Platformで提供されるKey-Value型の管理型データベースです。代表的なPaaS(Platform as a Service)であるGoogle App Engineでは、デフォルトのデータベースとして使われています。シャーディングとレプリケーションが自動化されているため、スケーラビリティと可用性において優れています。
Cloud Datastoreは、「エンティティ(Entity)」というオブジェクトで構成されるスキーマレスのデータベースです。エンティティは、システム全体の識別子となるキー(Key)と、それ自身が持つデータであるプロパティ(Property)から成り立っています。
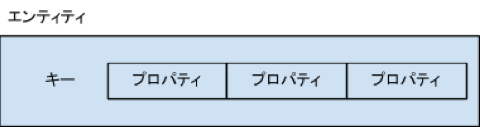
図1:Cloud Datastoreのエンティティの構造
Cloud Datastoreを使用するには、データベース環境として外部から利用する方法と、PythonあるいはJavaのインターフェースを通じてApp Engineから利用する方法の2種類があります。
図2:Cloud Datastoreの特徴
Cloud Datastore を始めよう −外部からの利用−
外部からCloud Datastoreを利用する時は、REST API(JSON)あるいは Node.js、Python、Java、Rubyなどのクライアントライブラリを使います。ここでは、クライアントライブラリとしてPythonを使った例を紹介します。
Compute Engineを起動する
前回記事「Google Compute Engineで仮想マシンを作る」にしたがって、Compute Engineのインスタンスを立ち上げます。
クライアントライブラリ(Python)のインストール
インスタンスが準備できたら、インスタンスにログインし、googledatastoreパッケージをインストールします。インストールには、virtualenvとpipが必要になります。
$ virtualenv gcd
$ gcd/bin/pip install --pre googledatastore
Service Account Credentialsの入力
環境変数としてDATASTORE_SERVICE_ACCOUNTとDATASTORE_PRIVATE_KEY_FILEを設定します。これらのService Account Credentialsは、Google Developers Consoleから取得します。
$ export DATASTORE_SERVICE_ACCOUNT=your_service_account
$ export DATASTORE_PRIVATE_KEY_FILE=your_private_key_file
デモコードの実施
Cloud Datastoreのデモコードをダウンロードし、解凍します。
$ wget https://github.com/GoogleCloudPlatform/google-cloud-datastore/archive/v1beta2-rev1-2.1.1.zip
$ unzip v1beta2-rev1-2.1.1.zip
パッケージに必要なモジュールをインストールします。
$ gcd/bin/pip install -r google-cloud-datastore-1beta2-rev1-2.1.1/python/requirements.txt
デモコード(adams.py)を実施します。
$ gcd/bin/python google-cloud-datastore-1beta2-rev1-2.1.1/python/demos/trivial/adams.py <dataset-id>
これでクライアントライブラリ(Python)を使ってCloud Datastoreへ接続が完了しました。デモコードについては、以下のページで確認できます。
Getting started with Google Cloud Datastore and Python/Protobuf
https://cloud.google.com/datastore/docs/getstarted/start_python/
Cloud Datastore を始めよう −App Engine からの利用−
App Engine(Python)でCloud Datastoreを利用する時には、Datastore APIまたはSQLに似た問い合わせ言語であるGQL(Google Query Language)を使うことができます。一方App Engine(Java)からCloud Datastoreを利用する際には、JDO(Java Data Objects)とJPA(Java Persistence API)を使用できます。ここでは、App Engine(Python)からDatastore API(Next DBモジュール、以下、NDB)を使った方法と、GQLを使った方法について説明します。
Datastore API
Datastore API(NDB)は、Google App Engine 1.6.4より標準コンポーネントとして組み込まれたモジュールで、データベースモデルの作成やクエリの実行といった基本的な処理に加え、トランザクション処理、キャッシュの自動化、および非同期でのデータ読み込み/書き込みなども可能です。
まず、NDBモジュールのModelを継承して、データモデルを定義します。NDBのプロパティにはいくつか種類がありますが、今回はIntegerPropertyとDateTimePropertyを使用します。各プロパティは、それぞれオプションを設定することもできます。
データモデルを定義したら、クラスメソッドを使ってデータベースに対する操作を記述します。この際にそれぞれのメソッドについて、スケールアウトしたときの計算量のオーダーを、おおまかに見積もっておくことをお勧めします。今回は、一般的なPut、Getという操作をそれぞれPutDatum、GetDataとして定義しています。

図3:Datastore API(NDB)でput、getを定義
GQL
GQLを使った場合、エンティティをSQLの列に相当するものとみなしてデータに問い合わせを行います。GQLでは、SELECT、WHERE、DISTINCT、GROUP BY、FROM、ORDER BY、OFFSET、LIMITという基本的な句をサポートしていますが、データセンター間での走査が非効率であるという理由からJOIN句やLIKE句がサポートされていないという制約があります。一見GQLを使うと、SQLのようにデータベースに問い合わせできるように見えますが、制約や効率性を考慮し、決してSQLの代替ではないという認識が必要です。
GQLを使って先ほどのgetData()と同じ結果を返すメソッドを書くと、以下のようになります。

図4:GQLを用いたgetの例
気になるCloud Datastoreのパフォーマンス
Cloud Datastoreでは単純なクエリに対するインデックスは全て自動生成され、検索はそれらのインデックスに基づいて行われるため非常に効率的です。一方、複雑なクエリに対するインデックス(複合インデックス)は、あらかじめ定義を登録しておく必要があります。複合インデックスには、複数のプロパティを指定できます。
一貫性の制御
Cloud Datastoreにおいて開発者は、強一貫性(Strong Consistency)と結果整合性(Eventual Consistency)という強さの異なる2種類の一貫性を選択可能です。場合に応じて一貫性を使い分けることで、パフォーマンスを最適化します。
リストプロパティの作成
一つのプロパティ内に複数の値を保存する場合は、プロパティのオプションに「repeated=True」を指定します。これにより、同じエンティティ内で1対多という関係性を、容易に作成できます。

図5:1つのプロパティ内に複数の値を保存する場合の指定
Self-merge Join
Cloud Datastoreでは、エンティティ間のJOINは非効率なのでサポートされませんが、エンティティ内におけるプロパティ同士のJOINについては、効率的なアルゴリズム(Zig-zag algorithm)が提供されています。このエンティティ内のJOINは、Self-merge joinと呼ばれ、リストプロパティと組み合わせて使うことで、強力な機能を発揮します。Self-merge joinでは、プロパティごとに作成されたインデックス間を行き来しながら、複数のプロパティ値の論理積(AND)を求めていきます。RDBMSでは2つのテーブルに分けて外部JOINを必要とするような処理についても、Cloud DatastoreではSelf-merge joinを使って一つのエンティティで効率的に処理できます。
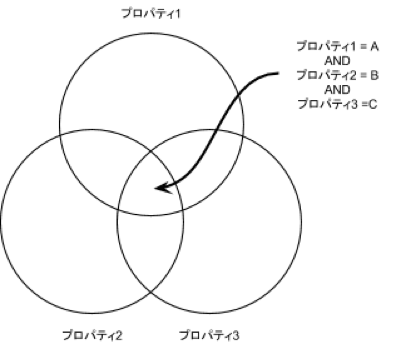
図6:Self-merge Join
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
