NOSQLは「知る時代」から「使う時代」へ
本連載では、オープンソースの分散KVS(Key-Value Store)である「okuyama」と、その関連技術について、4回にわたって解説します。okuyamaは、クラウド時代のデータ・ストレージと言われる、「NOSQL」と呼ぶ部類に属するデータ・ストレージです。連載では、NOSQLが登場した背
2011年2月3日 20:00
本連載では、オープンソースの分散KVS(Key-Value Store)である「okuyama」と、その関連技術について、4回にわたって解説します。
okuyamaは、クラウド時代のデータ・ストレージと言われる、「NOSQL」と呼ぶ部類に属するデータ・ストレージです。連載では、NOSQLが登場した背景や関連ソフトウエアの特色を整理したのち、okuyamaの概要と機能の紹介、そして実際にどのように配置・運用するか、などを解説します。
- 第1回: NOSQLは「知る時代」から「使う時代へ」
- - NOSQLの登場した背景や特性、NOSQLの種別を紹介します。
- 第2回: NOSQLの新顔、分散KVS「okuyama」の機能
- - 分散KVS「okuyama」の概要から機能の詳細までを解説します。
- 第3回: 分散KVS「okuyama」の使い方
- - 実際にokuyamaを起動してから利用までの手順と運用方法を解説します。
- 第4回: 分散KVS「okuyama」の活用ノウハウ
- - 実際にシステムに組み込んだ場合の活用方法を事例も合わせて解説します。
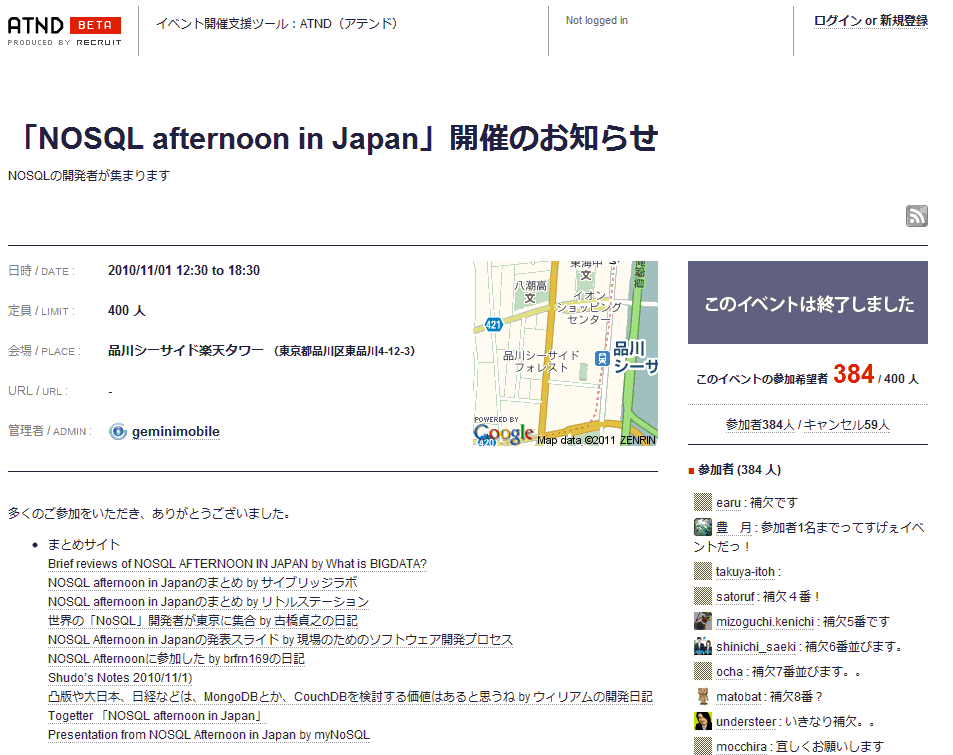
NOSQLは、ここ数年で大きく注目を集めました。各地で頻ぱんに勉強会などのイベントが開催されています。2010年11月に開催された「NOSQL afternoon in Japan」では、同様のプロダクトを代表する各国の開発者が登壇したこともあり、400人近くの参加者が集まりました(図1)。
しかし、NOSQL関連ソフトの特色や構築・運用ノウハウなどは、まだまだ広く知れ渡ってはいないのが現状です。NOSQLは単体で利用することも可能ですが、RDBMS(リレーショナル・データベース)と組み合わせて利用してこそ真の性能を発揮することができる、と筆者は考えています。
|
| 図1: 2010年11月1日開催の「NOSQL afternoon in Japan」参加申し込み画面(ATND)(クリックで拡大) |
1. NOSQLとは何か
(1)NOSQLが生まれた背景
NOSQLは、なぜ登場したのか。これには、昨今のインターネットの普及と、それによる情報量の増大が深く関係していると考えられます。
インターネットの普及は、日本で考えると、1990年代の後半から急激に上昇しています。それと同時に、インターネットに接続する社会的インフラも急速に発展しました。今では、いつでもインターネットに接続できる環境が整いつつあります。このような背景に後押しされるかのように、インターネット上での情報の生まれ方も変化してきています。
インターネット環境に常時接続できる環境が整ったことで、個人が生み出す情報も、広くネットワーク上で公開されるようになりました。これは、個人のホーム・ページなどから始まり、ブログ、Twitterなど、多種多様な形で生み出され続けています。加えて、これらのデータに対するアクセス要求も多様化しています。
例えば、Googleに代表されるような検索エンジンは、莫大(ばくだい)な量のWebページを日々インデックス化し、ユーザーからの検索の要求に対して高速に応答します。また、ECサイトに最近導入が盛んなレコメンド・エンジンなどは、ほかのユーザーの購買情報などを整理することで実現しています。
このような多様で大量のデータに対するアクセスを考えたときに、「データベースの代表ともいえるRDBMSだけにすべてのデータ管理を任せるのではなく、データ特性に合ったほかの管理方法があっても良いのではないか」との考えから生み出されたものがNOSQLなのではないか、と筆者は考えています。
(2)NOSQLの特徴
NOSQLという言葉が誕生したのは、Wikipediaによると、1998年と結構古く、「SQLインタフェースを持たない軽量な関係データベース」と定義づけられています。
この「SQLをインターフェースに持たない」という部分を強く意識して「Not Only SQL」、略して「NOSQL」と呼ばれています。
しかし、NOSQLがRDBMSと異なる部分は、SQLインターフェースの有無だけではありません。システム全体の設計思想の段階で異なっている部分も、多く見受けられます。また、NOSQLに分類されるソフトウエアであっても、種類によって設計思想が異なることがあります。
この設計思想の違いを理解するには、CAP定理と呼ばれる理論を知ると、理解しやすくなります。
CAP定理とは、Eric Brewer氏が提唱した、「分散環境のシステムにおいては、一貫性、可用性 、分割耐性の3つすべてを同時に満たすことはできない」という定理です。
|
|
| 図2: CAP定理を構成する3つの要素 | |
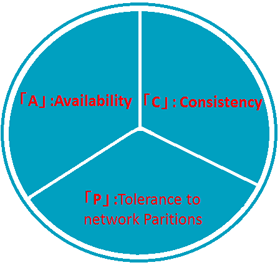
上記3つの中のうち、どれを満たすかで、ソフトウエアの特性が異なってきます。例えば、RDBMS (MySQLやPostgreSQLなど)は、多くの場合でCA (一貫性と可用性)を満たすことが多くなります。一方で、NOSQLは、APやCPを満たすことが多くなります。
このことから、RDBMSは一貫性を強く意識していることが分かります。また、一貫性を優先するために、単一のサーバー資源上でデータを管理する設計になっている場合が多いです。一方で、NOSQLは可用性や分割耐性のように、ネットワークを介して複数のサーバー資源を活用する使い方に対する意識が高いと言えます。
複数のサーバー資源を活用するスタイルには、背景として、最近のデータ生成のサイクルが頻ぱんで、単一のサーバーでは管理することが難しくなりつつあるという状況があるのではないでしょうか。
また、NOSQLの中には、システム稼働後であってもサーバー資源を動的に追加できる実装が、多く見受けられます。データ容量がサーバー資源に収まらなくなってきたタイミングで、サーバー資源を追加することで処理能力をコントロールしようという試みです。
背景には、データ生成量の上限を予想するのが難しい場合、あらかじめ必要となる資源を最適に配置することが困難である、という状況があります。このことからも、増え続けるデータを強く意識していることがうかがえます。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
