2. 「okuyama」の活用事例
2. 「okuyama」の活用事例
(1)ケース1:データ共有のための永続化ストレージ
本ケースは集めたデータの共有というユースケースに適応したケースです。あるシステムが持つ特定のデータ(ユーザーのアクセス情報といった動的なものから、マスター情報のような静的に近い情報など)を複数の別システムが自身のデータと組み合わせて利用し、別の価値を生み出す、データ共有を目的にしたシステムです。
外部のシステムとデータを共有する場合、システム間でデータをファイルなどで連携したり、既に保持しているストレージに直接アクセスするなど幾つか方法はありますが、この場合は連携先を「okuyama」とし、外部のシステムは「okuyama」に参照を集中する構成としました。
この際に、格納するデータの種類別にパーティションを作成し、データ別に空間を分離し同一のキー値などが別のデータで出てきた場合も対応できるようにしました。実際に内部に格納されるデータ形式はデータ種別で異なりますが、格納するマスターデータをJSONなどの共通フォーマットでシリアライズされたデータや、項目単位にタブで区切られたTSVデータなどです。
「okuyama」を基盤に使うことで、データ量の増加やアクセス数の増加へは柔軟に対応できますが、利用システムに対して、「okuyama」の専用クライアントや、memcachedクライアントでのアクセスを強制してしまいます。これでは利用できるシステムへの制約が大きすぎるため、別途インターフェース用のRESTful WebAPIサービスを構築しました。このWebサービスはJSON、XML両方の形式データを応答することを可能とし、JavaScriptからの直接アクセスなどにも対応します。
今後はこのWebサービス上にユースケース単位でAPIを追加し、共有データに対する多角的なアクセスに対応する予定です。
またシステムをまたいで更新データとして活用したいデータにもこの構成は向いているかと思われます。例えば特定の在庫データを管理する場合など各システムが在庫を管理するのではなく、集中管理された在庫情報を参照、更新することで情報管理を一元化できます。
|
|
| 図2:データ共有のための永続化ストレージとしての活用事例(クリックで拡大) |
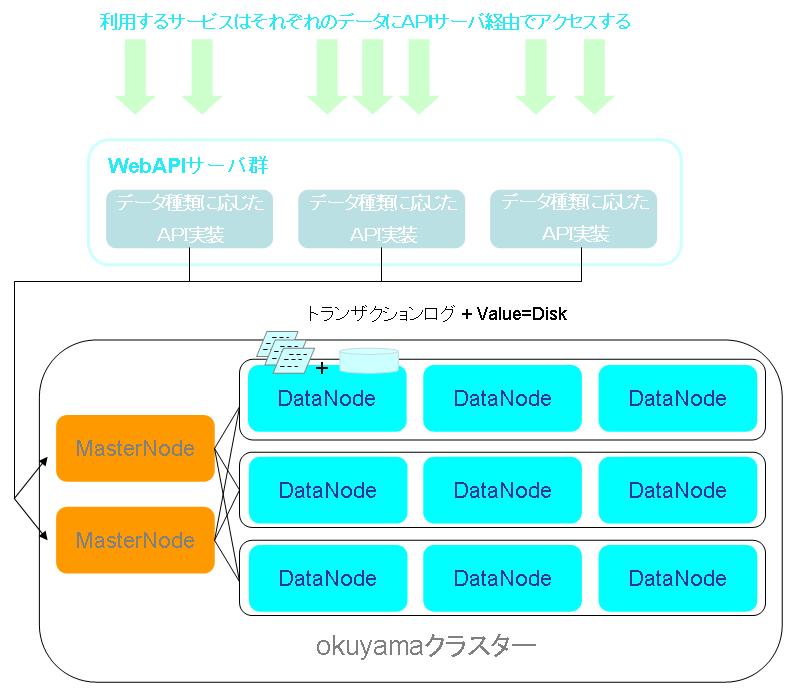
このケースの「okuyama」の構成ですが、レプリケーション数は2となり最も堅牢な設定としました。ストレージタイプはトランザクションログ+Key=メモリ,Value=Diskとしています。Diskを利用するためアクセス速度が問題になるかと思われますが、マスターデータなども含むため、1データあたりが大きくなり、メモリを大量に消費してしまうことを考慮してDiskとしました。その分レプリケーション数の多さでRead負荷を分散しています。
(2)ケース2:共有キャッシュサーバー(データセンター事業者)
本ケースは「okuyama」をキャッシュ用途に利用したケースです。
しかし1システムだけではなく複数の異なるシステムが利用します。そのためパーティション機能を利用して、利用システム単位で領域を用意し、領域単位でシステムに割り当てる構成になります。つまり、管理者としてはキャッシュサーバーを個々で管理するのではなく、1つの「okuyama」クラスターを管理するだけで済むようになります。利用システム側としても、管理者側での一元管理により容量やサーバーステータスなどをシステム側でチェックする必要がないという利点があります。
また、パーティションは事前に容量を決める必要がないという特性があるため、利用システム単位で冗長な領域などが発生せず、全体の稼働率の効率化にもつながっています。このケースではアクセスするシステムがキャッシュとして利用することを想定しているため、アクセスインターフェースはmemcachedとしています。そのため利用システムにはmemcachedとして見えます。memcachedであれば、ローカルの開発環境での構築も容易なため、開発時はローカル上のmemcachedを利用して、 本番実稼働時はこのクラスターを利用するといったパターンも、アプリケーションロジックの変更なしに可能です。
このケースの「okuyama」の構成ですが、レプリケーション数は1とします。ストレージタイプは、レプリケーションの片側は完全メモリとし、もう片方はトランザクションログで永続化を行っています。さらに、Read時に利用するデータノードは完全メモリのノード側を普段は利用するように、「okuyama」のデータノードのアクセスバランス率を調整しています。普段利用しているノードがダウンしトランザクションログ側のノードにフェイルオーバーしたとしても、両ノードともメモリでのデータ管理とすることにより高速性を失わず、かつ最悪の両ノード停止時もトランザクションログが壊れない限りは永続性を保証できる構成としています。
この構成の場合、データノードが故障してもマスターノードの自動フェイルオーバーが働くため停止とはなりませんが、マスターノードが停止した場合はクライアントアプリケーションでなんらかの処置をしなければ障害になってしまいます。そのための対策として、LVS(Linux Virtual Server:Linux カーネルに搭載されているソフトウエアロードバランシング機能)を利用して冗長化を行っています。
|
|
| 図3:共有キャッシュサーバとしての活用事例(クリックで拡大) |
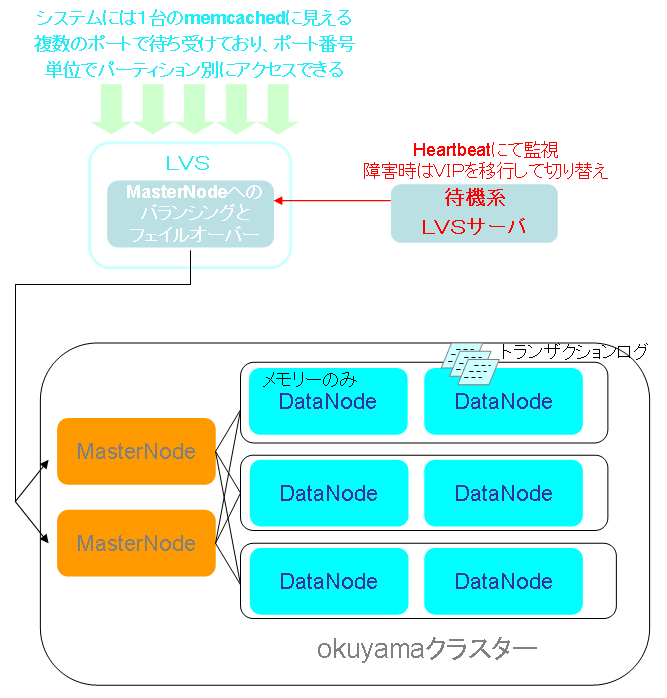
「okuyama」のマスターノードの前面にLVSサーバーを配置し、マスターノードへのアクセスをバランシングすると同時にマスターノードダウン時のフェイルオーバーも行っています。さらにLVSサーバーはheartbeatにてアクティブスタンバイ構成とし、LVSサーバーダウン時はLVSサーバーそのものがフェイルオーバーする仕組みになっています。
またLVSにより「okuyama」クラスター側のマスターノードの追加メンテナンス時なども、LVSの振り分け先をサーバーに追加することで、特に利用サービスに影響を与えずに実現することが可能となっています。
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
