定期的に発生する障害の解決
定期的に発生する障害の解決
Apache httpdサーバーとApache Tomcatサーバー上でアプリケーションが稼働しているWebサーバ2台と、PostgreSQLが稼働しているデータベースサーバー1台で構成されているシステムに対して、アプリケーションの稼働監視(データベースに登録されている情報の検索)をクライアント端末のアクセス経路と同じインターネット経由で実施していた。
サービスイン後しばらくして、1週間に1回程度の頻度でアプリケーションの稼働障害を検知するようになった。障害を検知した時に状況を確認すると、Webサーバーへの接続後、タイムアウトするまで応答が全くない状態であった。また、ロードバランサー配下のネットワーク経由で2台のWebサーバーに直接接続して確認すると、障害が発生しているのは1台のみであった。
障害の原因調査
このシステムは、Apache httpdサーバーとApache Tomcatサーバー上でアプリケーションが稼働しているWebサーバー2台と、PostgreSQLが稼働しているデータベースサーバー1台で構成されていた。このシステムに対して、アプリケーションの稼働監視(データベースに登録されている情報の検索)を、クライアント端末のアクセス経路と同じインターネット経由で実施していた(図2)。
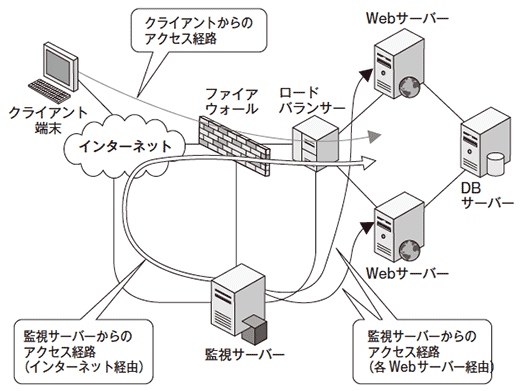
サービスインしてしばらく経ったとき、1週間に1回程度の頻度で、アプリケーションの稼働障害を検知するようになった。障害を検知したときに状況を確認すると、Webサーバーへの接続後、タイムアウトするまで応答がまったくない状態であった。また、ロードバランサー配下のネットワーク経由で、2台のWebサーバーに直接接続して確認すると、障害が発生しているのは1台のみであることがわかった。
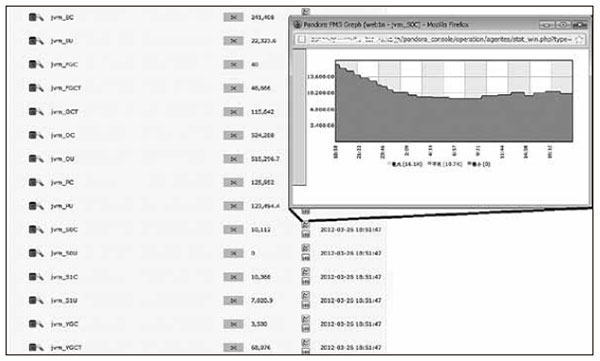
障害発生時のサービスへの影響が大きいため、暫定対処として、ロードバランサーのヘルスチェック設定を変更して、クライアントがタイムアウトする前に、障害が発生したWebサーバーをロードバランス(負荷分散)の対象から外れるようにした。さらに、ロードバランサー配下のネットワーク経由で、2台のWebサーバー個々に対して、アプリケーション稼働監視を実施するようにした後、根本原因の調査を開始した。障害発生状況、およびWebサーバーとデータベースサーバーで収集していたリソース情報から、WebサーバーのTomcat上で稼働しているJavaアプリケーションが障害原因であると推測し、JVMのメモリー使用状況やJavaのスレッド情報を元に、障害発生時のJavaアプリケーションの詳細状況を確認することにした。監視システムでは、このような事態に備えて、JVMのメモリー使用状況やJavaのスレッド情報を状況分析のために常に収集している。これは、jstatコマンドおよびTomcatのManagerアプリケーションから得られる情報を、監視システムが自動的に集め保存する仕組みだ(図3)。
「統合システム運用管理システム」で障害回避
これらの情報から、我々は、
- 各Webサーバーでアプリケーションの稼働障害を検知した時刻前後のJVMメモリー使用状況
- スレッド情報
- Webサーバーのリソース情報
を付き合わせた結果、障害要因はメモリー使用量ではなく(JVMのメモリー使用状況に問題はなかった)、Javaのスレッド数が上限に達して新規スレッドを生成できなくなったことであることが判明した。また、スレッド数が増加し始めた時点で、もっとも古いスレッドのリクエスト内容が同一であることから、問題のある処理についても、ある程度特定することができた。
そこで、とりあえずの対処としては、監視システムにてスレッド数がある値以上になったときに、Apache httpdおよびApache Tomcatを再起動するよう設定した。その後、根本的な対処として、収集した情報とTomcatおよびアプリケーションのログから、アプリケーション側の処理の問題点を抽出し、開発チームでアプリケーションの修正を実施し、アプリケーションの稼働障害が発生しないように改善した。
これは、「統合運用管理システム」によって、システムの問題解決のための情報収集からとりあえずの対処までを、実現した例である。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
