VMware vSphere環境の監視管理
これまでのサーバー・インフラ環境における監視運用第1回では、「VMware vSphereの運用課題」と題し、伊藤忠テクノソリューションズ(以下、CTC)が考える仮想化技術によるサーバー統合の成熟ステージの定義と、各ステージでの運用ポイントを紹介しました。ITサービス提供基盤の1つであるサーバー・イ
2009年12月11日 20:00
これまでのサーバー・インフラ環境における監視運用
第1回では、「VMware vSphereの運用課題」と題し、伊藤忠テクノソリューションズ(以下、CTC)が考える仮想化技術によるサーバー統合の成熟ステージの定義と、各ステージでの運用ポイントを紹介しました。
ITサービス提供基盤の1つであるサーバー・インフラ環境が正常に動作しているかどうか、障害が発生していないかどうかを「監視」することは、仮想化環境においても当然必要になる運用管理業務です。ここで注意すべきなのは、仮想化と言う新たな層が増えてサーバーの技術環境が変化したことにより、サーバー監視にも新たな視点や手法が必要となったことです。
今回は、仮想化サーバー・インフラ環境における監視について、考慮すべき点やツールの活用方法を紹介します。
サーバー・インフラ環境を監視する際の視点
VMware vSphereの仮想化サーバー・インフラ環境の監視を考える上で、まずは従来の物理サーバー環境を監視する際にどのような要件が求められていたかを整理してみます。
ユーザー企業へのサーバー機器の販売やインフラ構築を通して見えてきた、統合システム運用管理製品が提供するサーバー監視の視点には、以下のようなものがあります。
(1)ハードウエア障害の発生有無の監視
(2)ネットワーク疎通、OSへのアクセス可否を含むサーバー死活監視
(3)常時稼働するプロセスやサービスの監視
(4)ログなどに出力されるメッセージの監視
(5)ハードウエア・リソースの性能や使用状況の監視
従来のベンダー各社の統合システム運用管理製品では、それぞれの管理視点について、一般的に以下の特徴を備えているものが多いようです。
(1)のハードウエア障害の監視は、大抵はサーバー機器ベンダーが提供している、ハードウエアに特化した専用の管理ソフトを用いています。異常をSNMPトラップやメールで通知させたり、OSのシステム・ログなどへメッセージを出力させ、後述するOSログ監視機能を用いて管理するのが代表的です。
(2)のサーバー死活監視は、ネットワークで接続された監視マネージャから、ICMPやSNMPでポーリングを実施し、応答有無をチェックしているケースが多いです。
(3)(4)(5)に関しては概ね、各監視対象のサーバーOS内にエージェントと呼ばれる監視専用のプログラムを仕込んでおき、リモートから定期的に問い合わせを行い、エージェントから通知を上げさせる手法が一般的です。
VMware vSphere環境での監視の変化
それでは、VMware vSphereの環境は、従来のサーバー・インフラ監視に用いていた視点や手法を変えることなく流用できるのでしょうか。
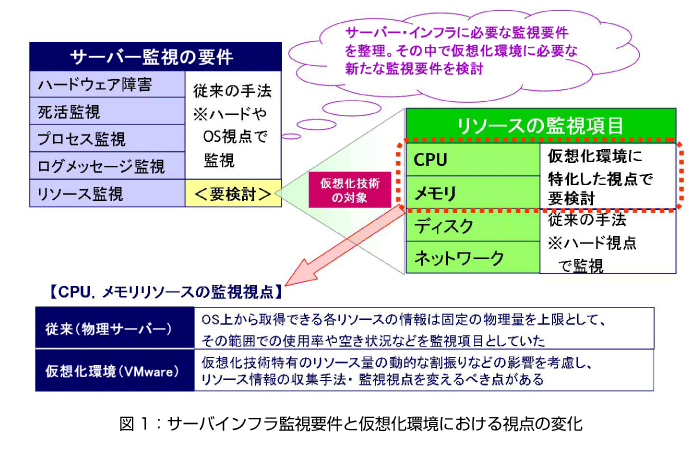
前述の(1)~(4)に関しては、監視対象とするハードウエアやOSから取得できる情報で監視することができ、従来の手法や監視ツールの機能が流用可能です。しかし、仮想マシンに対して物理リソースを論理的に割り当てる仮想化環境においては、(5)のリソース監視手法の再考が必要です。サーバー監視要件と仮想化環境での監視要件の相関関係は、図1に示す通りです。
仮想化インフラでは、CPU、メモリ、ディスク(ファイル・システム)、ネットワークが、キャパシティ管理の観点での監視対象です。その中でもCPUとメモリに関しては、仮想マシンを従来の物理サーバーと見立ててその中にエージェントを仕込む方法では十分とは言えません。なぜなら、この従来の監視手法は、CPUやメモリのリソースを“使用率”と言う尺度で見ているからです。
なぜ“使用率”と言う尺度では不十分なのかと言うと、VMware vSphereが提供する機能が仮想マシン上での“使用率”の計算根拠を動的に変化させ、仮想マシン上のリソースの最大値が不正確な情報になってしまうからです。
【“使用率”を動的に変化させる機能例】
- 物理リソースを複数の仮想マシンへ分配する際の動的割り当て
- リソースのオーバー・コミット機能
- 独自のメモリ・スワップ制御の挙動
- ハイパーバイザ層を経由してリソース制御することによるオーバーヘッド
本連載の第1回では、最近のハードウエアの技術進歩、仮想化技術への対応により、システムの稼働/運用においては仮想化ソフト自身のオーバーヘッドなどの要素が不安要因ではなくなりつつあることを説明しました。ですが、監視という運用管理が不要になる訳ではありませんので、仮想化環境特有の変化に対応した管理手法や機能を知っておくべきです。
次ページでは、VMware vSphereが仮想マシンに割り当てるCPUとメモリのリソースが、なぜ仮想マシンのOS上から見た情報だけで監視しきれないのかを、事例をもとに紹介します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
