Sparkの性能向上のためのパラメータチューニングとバッチ処理向けの推奨構成
2017年1月25日 0:15
はじめに
前回は、Sparkで処理を実行したときのボトルネック箇所と、その対策について解説しました。今回は、「本検証のシナリオではどのようなクラスタ構成が良いか」検証した結果を解説します。
Spark2.0のパラメータチューニング
最適なクラスタ構成を検討するにあたり、今回はSparkの(設定ファイルspark-defaults.confに記述できる)パラメータのうちいくつかをチューニングします。条件は次の通りです。
- Sparkのバージョンは2.0
- 処理対象のデータは365日分の消費電力量データ
- Sparkのシャッフルファイル出力先ディスクはHDFSと共用(前回解説したもの)
パーティション数のチューニング
Sparkはデータを「パーティション」という単位で並列処理します。処理の流れは以下の通りです(図1)。今回はシャッフル処理後の適切なパーティション数を検証します。
(1)データソースからデータを読み出し
データソースがHDFSの場合、Sparkはブロック単位でHDFS上のファイル群を読み出し、各ブロックをパーティションとして扱います。Sparkのパーティション数はHDFSから読み出したBlock数と同じです。
(2)データを並列に変換処理
1パーティションを1タスクで並列に変換処理していきます。
(3)シャッフル処理
処理の途中でパーティション間のデータ交換(シャッフル)を行います。このときパーティション数はデフォルト設定で200個に変更されます。
(4)データストアにデータを書き込み
変換処理が完了したら、処理結果をパーティション単位で並列にデータストアへ書き込みます。
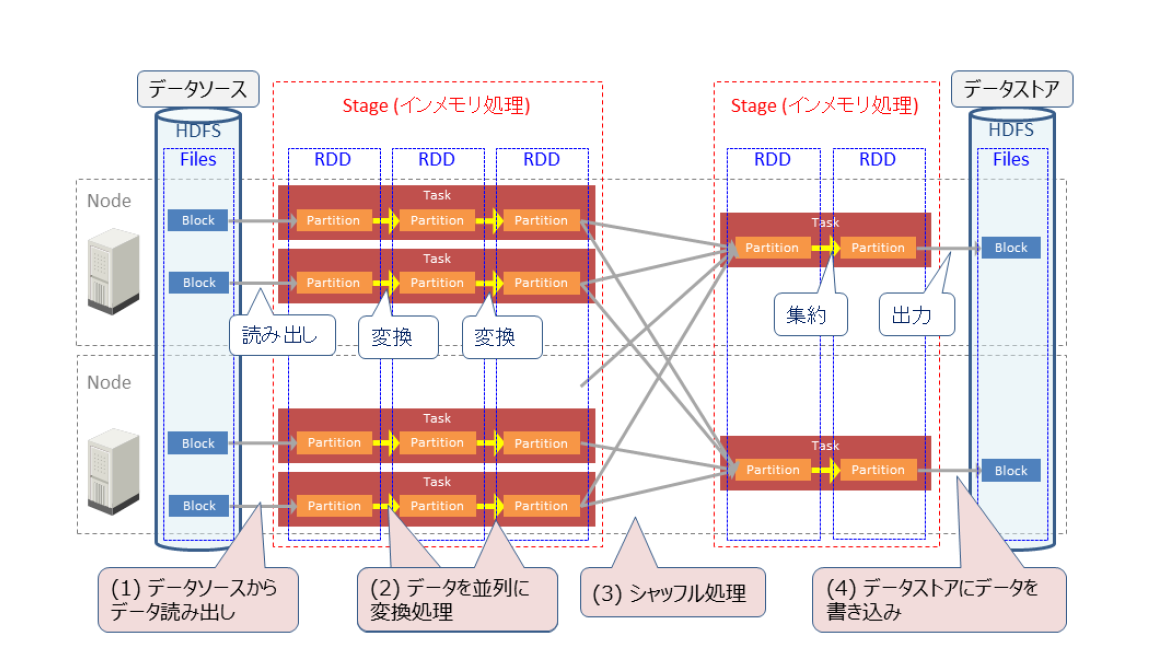
図1:Sparkのデータ処理
最適パーティション数の検証内容
Sparkが最初にHDFSからデータを読み込んだ時(図1(1))のパーティション数はファイルのブロック数と同じですが、DataFrame APIを使用してシャッフル処理(図1(3))すると、パーティション数が200個(デフォルト値)に変更されます。デフォルト設定では1パーティションを1コア(で動作する1タスク)が処理するため、最低でもコア数以上のパーティションがないと最適な設定とは言えません。またシャッフル処理後の適切なパーティション数は処理に依存します。
本検証でSparkに割り当てたコア数は210個です。そこでシャッフル処理後のパーティション数を200個(デフォルト値)と210個から5040個(割当コア数の24倍)の間で設定し、それぞれの処理時間を測定して最適なパラメータ設定値を求めます。
検証結果
シャッフル処理後のパーティション数設定と処理時間の関係を図2に示します。
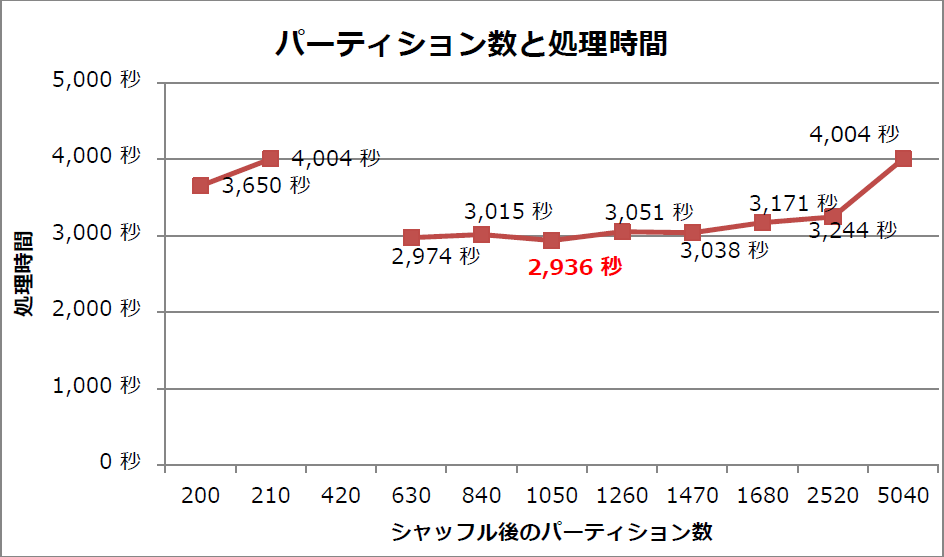
図2:シャッフル後のパーティション数設定と処理時間
この結果から、次のことが分かります。
- パーティション数が630個から1,470個の間では処理時間が約3,000秒で推移した
- パーティション数が1,050個のとき、処理時間は最短で2,936秒であった
デフォルト設定(200個)に比べて約700秒、本検証の初期設定(210個)と比べて約1,070秒短縮 - パーティション数が420個のときは処理が失敗した
最適パーティション数の考察
Sparkを実システムに適用する際には、コア数のほかに次のような要素にも影響を受けるため、事前に検証して最適なパーティション数を探る必要があります。
- ディスク台数(パーティション数はディスクへの並列書き込み数となるため)
- データ量(1パーティションあたりの保持データ量)
本検証では、パーティション数を1,050個に設定すると最も高速に処理を実行できたので、この値を最適な設定値とします(表1)。このパラメータ設定はspark-defaults.confに記述します。
シャッフル後のパーティション数を420個に設定したときに処理が失敗した原因は不明です。Sparkはメモリが少ない場合にデータをディスクに書き出して確保しますが、タイミングによって確保に失敗することがあるようです。
表1:本検証におけるパーティション数の最適な設定値
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | シャッフル後のDataFrameのパーティション数 | 1050 | spark.sql.shuffle.partitions |
Sparkへのメモリ割当量のチューニング
最適メモリ割当量の検証内容
Sparkにクラスタの全メモリを割り当てることはできません。クラスタではSparkのほかにOSやHadoopデーモンがメモリを使用するためです。前回、シャッフルファイルがディスクに書き込まれるとき、OSのページキャッシュが使われることを解説しました。今回の集計処理はシャッフルするデータ量が多く、ページキャッシュ用にある程度のメモリを確保する必要があります。
そこで本検証では、Sparkに割り当てるメモリ容量をクラスタの全メモリの75%に相当する1,728GB(デフォルト設定)から15%に相当する345GBの間で設定し、それぞれの処理時間を測定して最適なパラメータ設定値を求めます。
検証結果
Sparkに割り当てるメモリ容量を変化させたときの処理時間を図3に示します。
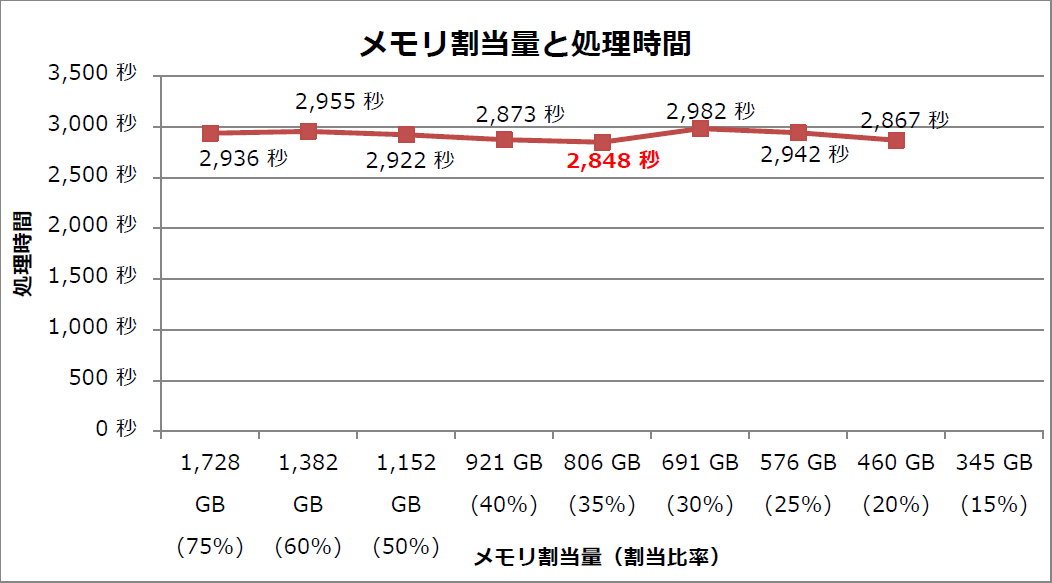
図3:Sparkへのメモリ割当量と処理時間
この結果から、次のことが分かります。
- Sparkへのメモリ割当量を減らしても処理時間に大きな変化は見られない
また本検証中に次のような事象に遭遇し、対応しました。
- メモリ割当量を減らすと、エグゼキュータのコンテナがYARNによって停止されることがある
本検証ではSparkへのメモリ割当量を619GB以下に設定したときにコンテナが停止されました。 - エグゼキュータに割り当てるメモリのオーバヘッド確保容量を増やすことでコンテナ停止を回避できた
コンテナ停止時にSparkのログを参照すると、オーバヘッド確保容量を調整するようメッセージが出力されました。よって今回は、メモリ割当量691GB、576GBのときにメモリオーバヘッドを20%に、メモリ割当量460GBのときにメモリオーバヘッドを30%に設定しました。
最適メモリ割当量の考察
最短の処理時間は2,848秒で、1,728GB(デフォルト設定)のときの2,936秒から約3%の高速化を達成しました。平均処理時間は2,915.6秒、標準偏差は47.6なので性能向上していると言えます。
よって、本検証では処理時間が最短だったSparkへのメモリ割当量806GB(クラスタ全体の約35%)を最適値に定めます(表2)。このパラメータ設定はspark-defaults.confに記述します。
表2:検証で求めたSparkへのメモリ割当容量の最適設定値
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | ドライバのメモリ容量 | 19GB | spark.driver.memory |
| 2 | 1エグゼキュータのメモリ容量 | 19GB | spark.executor.memory |
Sparkへのメモリ割当量が1,728GBのときのメモリ使用量の推移を図4に、メモリ割当量が460GBのときのメモリ使用量の推移を図5に示します。CacheがOSのページキャッシュ、UsedがSparkの使用メモリです。今回の検証内容のようにシャッフルのディスクI/O量が大きい場合は、Spark用のメモリを減らした分だけOSのページキャッシュが使用できるメモリが増え、ディスクI/Oが減少するため、結果として処理時間はあまり変わらなかったと考えられます。
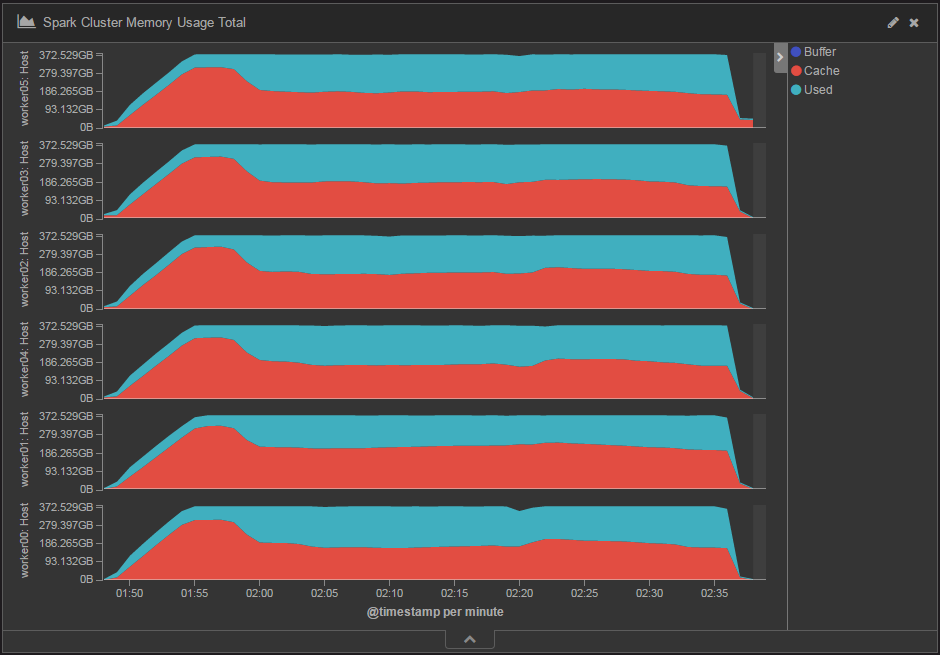
図4:Sparkへのメモリ割当量1,728GBのときのメモリ使用量の変化
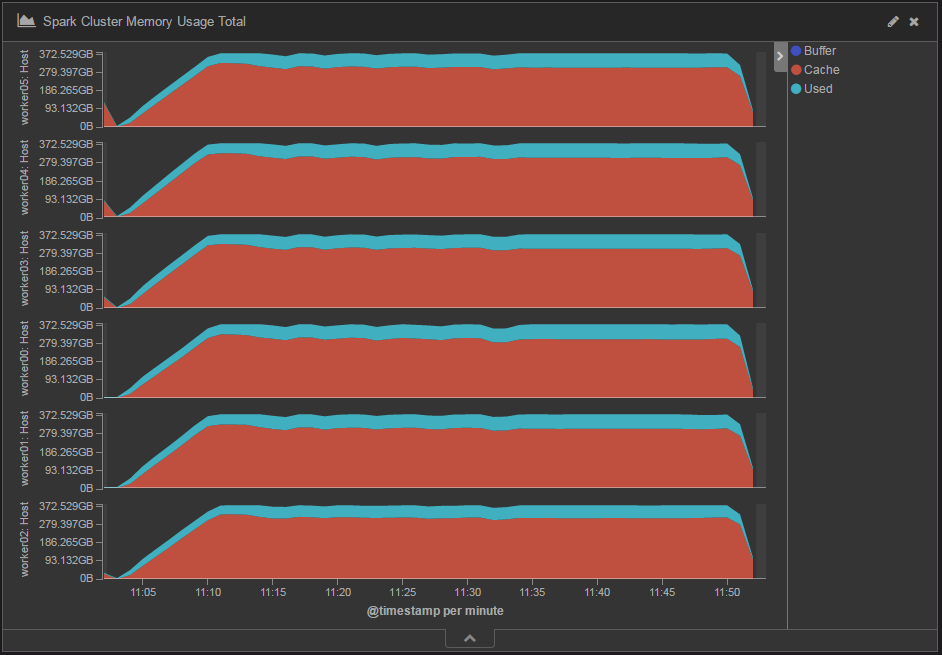
図5:Sparkへのメモリ割当量460GBのときのメモリ使用量の変化
よって、Sparkへのメモリ割当量は多ければ良いというわけではありません。前回で触れたシャッフル処理時のディスクアクセスを考慮して、ある程度のメモリをOSのページキャッシュ用に使わせるべきです。つまりSparkへ割り当てるメモリを増やすほどOSのページキャッシュに使えるメモリが減るため、メモリにシャッフルファイルが収まらずシャッフル処理(のディスクアクセス)に時間を浪費する恐れが高まります。この場合は、やはりクラスタに搭載するメモリ容量を十分に用意すべきです。
またシャッフルデータ量が多い場合は、シャッフル処理時にエグゼキュータへ割り当てられたメモリ容量を超過して、エグゼキュータのコンテナがYARNによって停止されることがあります。この事象はSparkに割り当てるメモリが少ないほど発生しやすいです。エグゼキュータに割り当てるメモリのオーバヘッド確保容量をデフォルト値の10%から増やす(表3)ことで回避できました。このパラメータ設定はSparkの設定ファイルspark-defaults.confに記述します。
表3:Sparkのエグゼキュータのパラメータ設定
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | エグゼキュータのメモリオーバヘッド確保容量(※) | 20%から30%程度 ただし処理やメモリ量で異なり試行錯誤が必要 | spark.yarn.executor.memoryOverhead |
(※):エグゼキュータ自身が使用するメモリ容量。デフォルトでは384MBもしくはSpark割当量の10%のうち、大きいほうの値が使用される
エグゼキュータ数のチューニング
ここでは、Sparkへのメモリ割当量を806GB(クラスタ全体の約35%)に設定した状態で検証します。
最適エグゼキュータ数の検証内容
エグゼキュータ数を増加させると、エグゼキュータ間での通信などを処理するオーバヘッドが増加します。一方で1エグゼキュータに割り当てるメモリ量が小さくなり、Javaのガベージコレクション(GC)にかかる時間やキャッシュミス、TLBミスが減少します。
そこで本検証では、エグゼキュータ数を11個から65個の間で設定し、それぞれの処理時間を測定して最適なパラメータ設定値を求めます。エグゼキュータ数を変化させた場合も、その増減に合わせてCPUコア数とメモリ量を調整することで、Sparkに割り当てる合計CPUコア数は210個、メモリ量は806GBで一定となるようにします。
検証結果
Sparkに割り当てるエグゼキュータ数を変化させたときの処理時間を図6に示します。
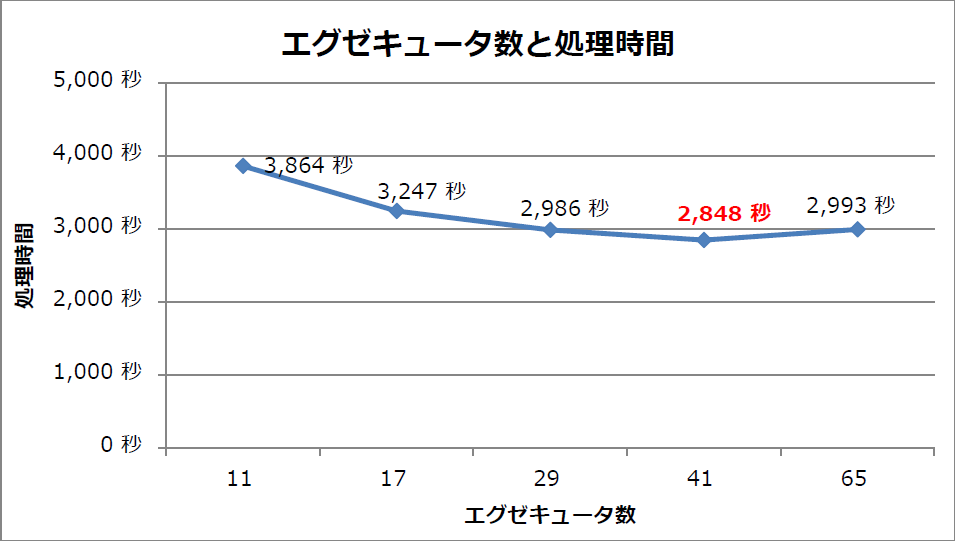
図6:エグゼキュータ数と処理時間
この結果から、次のことが分かります。
- エグゼキュータ数を増やすと処理時間が短縮できる傾向がある
- エグゼキュータ数が41個(初期設定)の場合に処理時間が最短(2,848秒)であった
最適エグゼキュータ数の考察
エグゼキュータ数を11個から41個まで増加させた間は処理時間が短縮され、65個に増加した場合は29個に設定したときと同程度の処理時間に戻っています。ここが、エグゼキュータあたりのリソースを絞ったことによるGCにかかる時間やキャッシュミスを低減できたことよりも、エグゼキュータ間で発生する処理のオーバヘッドが大きくなる境界と考えられます。
よって、本検証ではエグゼキュータ数41個(本検証の初期設定)を最適設定値として定めます(表4)。このパラメータ設定はspark-defaults.confに記述します。
表4:検証で求めたエグゼキュータ数の最適設定値
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | エグゼキュータ数 | 41 | spark.executor.instances |
コア数のチューニング
ここでは、Sparkのエグゼキュータ数を41個(本検証の初期設定値)に設定した状態で検証します。
最適コア数の検証内容
Sparkにクラスタの全CPUコアを割り当てることはできません。クラスタではSparkのほかにOSやHadoopデーモンがメモリと同様にCPUコアを使用するためです。またSparkにコア数を多く割り当てても、処理性能は向上しない可能性があります。Sparkからディスクへの書き込みがボトルネックとなり、Sparkに割り当てたCPU時間の多くをI/O waitに費やすかもしれないからです。
そこで本検証では、SparkへのCPUコア割当数を210個(初期設定)から46個(ドライバ5コア・エグゼキュータ1コア)の間で設定し、それぞれの処理時間を測定して最適なパラメータ設定値を求めます。
検証結果
Sparkに割り当てるCPUコア数を変化させたときの処理時間を7に示します。

図7:CPUコア割当数と処理時間
この結果から、次のことが分かります。
- Sparkに割り当てるコア数を減らすと処理時間が増加する
- Sparkへの割当コア数が210個(初期設定)のとき、処理時間が最短(2,848秒)であった
最適コア数の考察
割当コア数を減らすほど処理時間は増加しました。よって、最も割当コア数が多い本検証の初期値である210個を最適設定値として定めます(表5)。このパラメータ設定はspark-defaults.confに記述します。
表5:CPUコア割当数の最適設定値
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | ドライバのCPUコア数 | 5 | spark.driver.cores |
| 2 | 1エグゼキュータのCPUコア数 | 5 | spark.executor.cores |
パラメータチューニングの総括
本連載で全4回にわたって検証したパラメータチューニングを振り返ります。
チューニングの効果
今回、Spark 2.0に各チューニングを施した場合の処理時間を図8にまとめます。チューニングを実施することで、本検証での初期設定時に比べて約4.7倍の高速化を達成しました。

図8:Spark 2.0に施したチューニングと処理時間
バッチ処理向けのクラスタ推奨構成
本検証の結果と考察を基に、バッチ処理向けのHadoop(Spark 2.0)クラスタ構成の考え方の一例を表6~9に示します。表6:推奨マシンスペック
| # | ノード(ロール) | 台数 | CPUコア | メモリ容量 | ディスク数 |
|---|---|---|---|---|---|
| 1 | Client | 1 | 2コア以上 | 8GB以上 | 1 |
| 2 | Hive Metastore Server | 1 | 2コア以上 | 8GB以上 | 1 |
| 3 | Master | 1 | 4コア以上 | 16GB以上 | 1 |
| 4 | Worker | 多いほど良い | 多いほど良い | Sparkの処理データとシャッフルファイルが載る量以上 | OSインストール領域:1 シャッフル用:多いほど良い HDFS用:多いほど良い |
HDFSのブロックはデフォルトで3台に複製されるため、最低4台のWorkerノードを用意するべきです。Workerノード間は10Gbps回線での接続を推奨します。
Sparkのシャッフルファイル出力先(YARN)とHDFSは同じディスクを共用します。OSインストール領域のディスクは多量のアクセスによりハングする恐れがあるため、シャッフルファイル出力先とは共用しないことを推奨します。
表7:HDFSの推奨パラメータ設定(hdfs-site.xml)
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | HDFSが使用するディレクトリ | ノードに搭載されたディスクのうち、OSインストール先ディスク以外を使う。ディスクは多いほど良い | dfs.datanode.data.dir |
表8:YARNの推奨パラメータ設定(yarn-site.xml)
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | 1コンテナの割り当てメモリ容量上限 | サーバ(workerノード)1台が持つメモリ容量のうち75%程度を割り当てる | yarn.scheduler.maximum-allocation-mb |
| 2 | 1ノードの割り当てCPUコア数の上限 | OSやHadoopデーモンのために数コア残し、残りをすべて割り当てる | yarn.nodemanager.resource.cpu-vcores |
| 3 | 1ノードの割り当てメモリ容量の上限 | サーバ(workerノード)1台が持つメモリ容量のうち75%程度を割り当てる | yarn.nodemanager.resource.memory-mb |
| 4 | シャッフルファイル出力先 | ノードに搭載されたディスクのうち、OSインストール先ディスク以外を使う。HDFSが使うディスクと共用しても構わない。ディスクは多いほど良い | yarn.nodemanager.local-dirs |
表9:Sparkの推奨パラメータ設定(spark-defaults.conf)
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | ドライバのCPUコア数 | 5コア以下 | spark.driver.cores |
| 2 | 1エグゼキュータのCPUコア数 | 5コア以下 | spark.executor.cores |
| 3 | エグゼキュータ数 | 第6回の表7について解説した内容と同様の考え方 | spark.executor.instances |
| 4 | ドライバのメモリ容量 | spark.driver.memory | |
| 5 | 1エグゼキュータのメモリ容量 | spark.executor.memory | |
| 6 | シリアライザ | KryoSerializer | spark.serializer |
| 7 | シャッフル後のDataFrameのパーティション数 | 予め検証して最適な値を求める必要がある | spark.sql.shuffle.partitions |
OSとHive(ORCFile)の推奨パラメータ設定は第6回の時と同じです。
おわりに
本連載も、今回で最終回となります。最後にポイントをまとめます。
- Spark 2.0はSpark 1.6に比べて処理性能が約20%向上
本検証のシナリオ(電力データの集計処理)ではデータ結合を含む多段の集約処理を含むため、Sparkのシャッフル処理が頻発しディスクアクセスが処理時間の大半を占めました。企業が持つデータの多くはRDBMSで管理されていると考えられるため、そのようなデータを活用して動作する既存のバッチ処理にはデータ結合も含み、Spark1系からSpark 2.0に移行してもリリースノート記載の「Spark1系と比べて2倍から10倍」という処理性能は得られないと思われます。 - Spark活用のためにはクラスタに十分なメモリ容量を搭載すること
Sparkはシャッフルファイルを含むすべてのデータがメモリ(ページキャッシュ)に収まるとき、最も性能を発揮できます。扱うデータ量は処理によって異なるため、小規模なデータで予め試行し、必要なメモリ容量を見積もることを推奨します。メモリの増設が必要な場合はクラスタをスケールアウトしてメモリ総容量を増やすか、1ノード当たりの物理メモリ容量を増やすことになるかと思います。 - パラメータチューニングは慎重に
Sparkを用いたHadoopクラスタを構築する際は、机上での設計だけでなく実際の処理やデータを使って試行錯誤しながら慎重にパラメータ等を設定する必要があることに注意してください。
例えば、ページキャッシュにシャッフルファイルが収まらないとき、シャッフルファイル出力先をHDFSが使うディスクと共用する形で追加することで約3.6倍の性能向上を実現しました。ただしこの方法はHDFSのディスクアクセス性能を低下させるため、シャッフルファイルがページキャッシュに収まる場合は処理性能が若干低下します。またパーティション数のように実際に試してみないと最適値が分からないパラメータもあります。
最後になりましたが、本連載がSparkを用いたデータ分析システム構築の一助になれば幸いです。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
