はじめに
前回は、Spark 2.0の主な変更点としてSpark 1.6よりも性能が向上し、アプリケーションの実装が容易になったことを解説しました。また、その性能検証のシナリオとして、電力消費量データを集計し可視化するケースを想定することを解説しました。今回は、シナリオに基づいた検証を行うための環境(システム構成、パラメータ)とその検証結果を解説します。
システム構成
データ分析システムの概要
データ分析システムは、図1のように管理画面とデータ分析アプリケーション、データ処理基盤の3つから成ります。設備企画担当者は管理画面を介してドリルダウン分析を行います。予めデータ分析アプリケーションで設備の負荷を集計し、その演算処理を実行するのがデータ処理基盤です。本連載で取り上げるデータ処理基盤にはHadoopおよびSparkを導入しています。
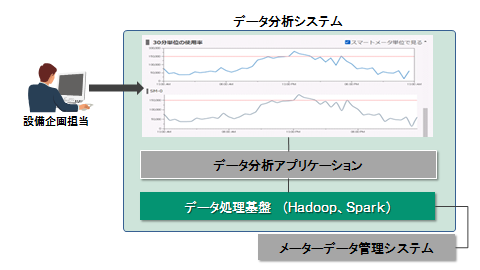
図1:データ分析システムの構成
ハードウェア構成
データ処理基盤は仮想サーバ3台、物理サーバ7台の計10台とネットワークから構成されるHadoopクラスタです(図2)。Workerノード間ではHDFSのレプリカ作成やSparkのシャッフル処理によって頻繁にデータ交換が発生するため、Workerノード間を接続するネットワークには10Gbpsの回線を使用しています。
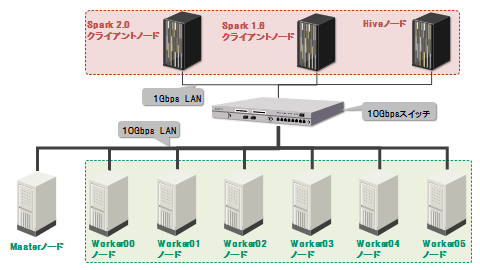
図2:Hadoopクラスタのマシン構成
また、クラスタを構成するマシンのスペックは表1の通りです。物理マシンのWorkerノードに搭載された10台のディスクのうち2台をRAID0構成でOSインストール用に割り当て、残りの8台をHDFSに割り当てています。
表1:クラスタを構成するマシンのスペック一覧
| # | ノード名 | マシン種別 | CPUコア[個] | メモリ[GB] | ディスク | ||
|---|---|---|---|---|---|---|---|
| 容量[GB] | 数[個] | 総容量[GB] | |||||
| 1 | Spark 2.0 クライアントノード | 仮想 | 2 (2スレッド) | 8 | 80 | 1 | 80 |
| 2 | Spark 1.6 クライアントノード | 仮想 | 2 (2スレッド) | 8 | 80 | 1 | 80 |
| 3 | Hiveノード | 仮想 | 2 (2スレッド) | 8 | 80 | 1 | 80 |
| 4 | Masterノード | 物理 | 16 (32スレッド) | 128 | 900 | 8 | 7,200 |
| 5 | Workerノード (Worker 00 - 05) | 物理 | 20 (40スレッド) | 384 | 1,200 | 10 | 12,000 |
ソフトウェア構成
ノードごとに与えたロールとインストールしたソフトウェアは図3の通りです。Workerノードは6ノードとも同じロールを設定しています。また、全ノードにOSとしてRed Hat Enterprise Linux 6.7を導入します。

図3:クラスタの論理構成
検証内容
本検証ではSpark 2.0がSpark 1.6よりどの程度性能向上しているかを調べます。そのために、Spark 1.6とSpark 2.0それぞれで消費電力量データの集計処理に要する時間を測定し、結果を比較して評価します。また、集計処理に用いる消費電力量データのデータ量は1日分、30日分、365日分の3通りとします。
検証範囲
データ分析システムのうち、データ分析アプリケーションとデータ処理基盤が性能検証の対象です。データ処理基盤にはHadoopおよびSparkを導入しています。処理性能として測定する処理時間の範囲は、内部集計バッチを実行してから電力消費量データの集計処理が完了するまでに要した時間とします(図4)。
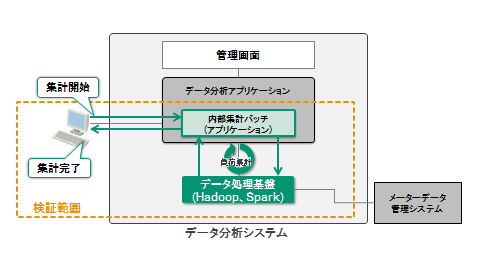
図4:検証範囲
処理内容
検証範囲で実施する具体的な処理を説明します。処理内容は図5のとおりです。
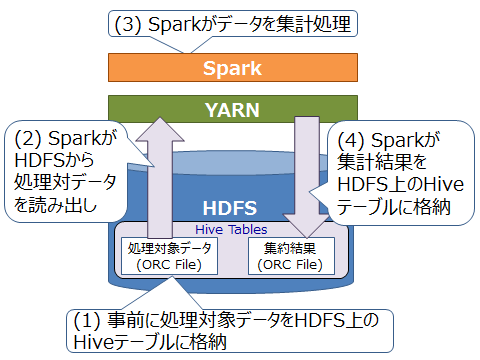
図5:本検証での処理手順
本検証では、簡単化のためデータ処理基盤内部のHDFS上に構築したHiveテーブルに事前に処理対象データを格納した状態から集計処理を開始します(1)。このテーブルのデータをSpark SQLで読み出し(2)、Sparkでデータを集計処理し(3)、集計結果を別のHiveテーブルに書き出します(4)。Hiveテーブルへの書き出しが完了した状態で集計処理完了とします。
このうち(3)が設備ごとの負荷を集計して算出する処理です。前回でも説明した通り、配電設備の負荷はその下位の設備の負荷を合計して求めることができます(図6)。
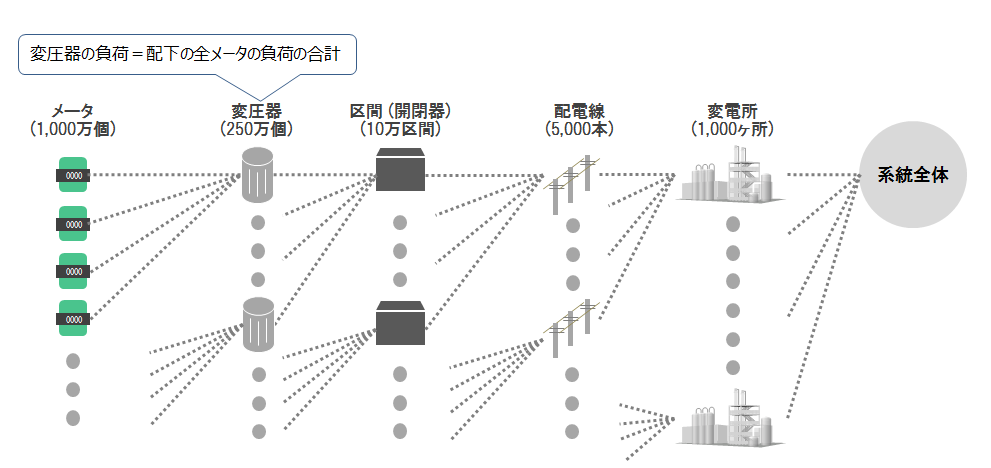
図6:負荷を求めるための考え方
Spark SQLで各設備の負荷を求めるには、まずメータ計測値(メータごとの消費電力量)を変圧器ごとに集計し、結果をHiveテーブルへ書き込みます。この処理手順はテーブルの結合(Join)と値の集計処理(GroupByとSUM)から成ります(図7)。次に変圧器の負荷を区間ごとに集計してHiveテーブルに結果を書き込みます。これを系統全体の負荷が求まるまで繰り返します。
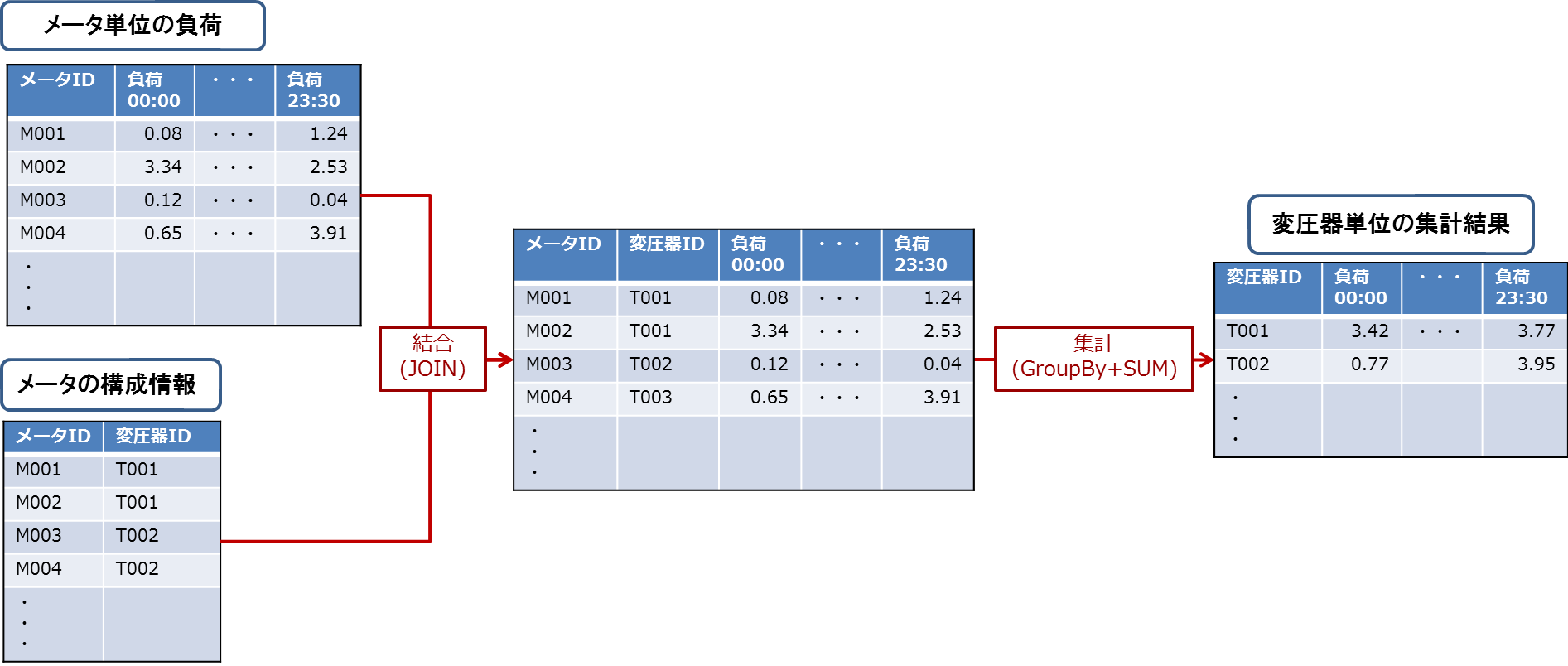
図7:設備ごとに負荷を集計する処理
データセット
本検証で使用したデータを表2に示します。このデータはすべてORCFile形式でHiveテーブルに格納しています。
表2:データセット一覧
| # | テーブル名 | レコード数 | サイズ | 説明 |
|---|---|---|---|---|
| 1 | 電力消費量 | 36億5,000万件 | 1,325GB | スマートメータから収集した電力消費量データを365日分(1日1,000万件)格納 |
| 2 | メータ | 1,000万件 | 78MB | メータの構成情報(管理テーブル) |
| 3 | 変圧器 | 250万件 | 32MB | 変圧器の構成情報(管理テーブル) |
| 4 | 区間 | 10万件 | 835KB | 区間の構成情報(管理テーブル) |
| 5 | 配電線 | 5,000件 | 32KB | 配電線の構成情報(管理テーブル) |
パラメータ設定
本検証では、OSおよびHadoopを構成するコンポーネントの各種パラメータをそれぞれの表に示す通りに設定しました。特に記載していない項目やパラメータは初期設定の状態です。
OSに関するパラメータの設定値は表3の通りです。
表3:OSのパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 [設定ファイル] |
|---|---|---|---|
| 1 | スワップ頻度 | 1 | vm.swappiness [/etc/sysctl.conf] |
| 2 | Transparent Hugepage Compaction | never | [/sys/kernel/redhat_transparent_hugepage/defrag] |
スワップ頻度として設定する値は0~100の範囲内で設定し、値が大きいほどスワップ頻度も高くなります。処理対象のデータがディスクに格納された状態でJVMのガベージコレクションが発生するとディスクアクセスが頻発するため、本検証ではスワップ頻度を低く抑えます。
Transparent Hugepageは、メモリ管理の単位であるページの格納領域を初期設定の4KBよりも大きな単位に設定し、その領域を予め確保しておくことでアクセス時間を短縮する仕組みです。Transparent Hugepage Compactionの初期値はalways(常時使用)ですが、この場合はsystemのCPU使用率が高騰する恐れがあるため、本検証では使用しません。
HDFSに関するパラメータの設定値は表4の通りです。設定ファイルhdfs-site.xmlに記述します。
表4:HDFSのパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | HDFSに登録する領域 | file:///data/1, file:///data/2, file:///data/3, file:///data/4, file:///data/5, file:///data/6, file:///data/7, file:///data/8 | dfs.datanode.data.dir |
HDFSの使用領域として設定する値はWorkerノードのファイルパスです。本検証では、予めすべてのWorkerノードの/data/1、/data/2、……、/data/8にデバイス(ディスク)をマウントしています。
YARNに関するパラメータの設定値は表5の通りです。設定ファイルyarn-site.xmlに記述します。
表5:YARNのパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | 1コンテナの割り当てメモリ容量上限 | 384GB | yarn.scheduler.maximum-allocation-mb |
| 2 | 1ノードの割り当てCPUコア数の上限 | 40 | yarn.nodemanager.resource.cpu-vcores |
| 3 | 1ノードの割り当てメモリ容量の上限 | 384GB | yarn.nodemanager.resource.memory-mb |
コンテナはYARNによってWorkerノードに割り当てられます。通常はOSやHadoopデーモンのためにある程度のリソースを残しますが、今回は性能検証のために各項目の設定値をWorkerノードが持つリソース量の上限に合わせます。
Hive(ORCFile)に関するパラメータの設定値は表6の通りです。Hiveテーブルを作成するHiveQL文中のTBLPROPERTIESに設定します。
表6:Hive(ORCFile)のパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | stripeのサイズ | 64MB | orc.stripe.size |
| 2 | 圧縮形式 | SNAPPY | orc.compress |
stripeのサイズをHDFSのブロックサイズよりも小さく設定するとより高い性能を発揮できるため、本検証ではHDFSブロックサイズ(初期値256MB)よりも小さく設定します。
圧縮形式は一般的に性能重視の場合はSNAPPYを、圧縮率重視の場合はZLIBを設定します。今回は性能検証なので、より高速処理が期待できるSNAPPYを設定します。
YARN上でSparkを実行するときは、処理をスケジューリングするドライバ1個とタスクを処理するエグゼキュータ複数個がそれぞれYARNコンテナ上に生成されます(図8)。

図8:YARN上のSparkでアプリケーションを実行するときのリソース配分
これを踏まえたSparkのリソース割り当てに関するパラメータの設定値は表7の通りです。設定ファイルspark-defaults.confに記述します。
表7:Sparkのパラメータ設定値一覧
| # | 設定項目 | 設定値 | パラメータ名 |
|---|---|---|---|
| 1 | ドライバのCPUコア数 | 5 | spark.driver.cores |
| 2 | 1エグゼキュータのCPUコア数 | 5 | spark.executor.cores |
| 3 | エグゼキュータ数 | 41 | spark.executor.instances |
| 4 | ドライバのメモリ容量 | 37GB | spark.driver.memory |
| 5 | 1エグゼキュータのメモリ容量 | 37GB | spark.executor.memory |
| 6 | シリアライザ | KryoSerializer | spark.serializer |
ドライバのCPUコア数と1エグゼキュータのCPUコア数は、HDFSのスループットを考慮すると5コア以下が良いとされる※ため、本検証ではそれぞれ5コアを設定します。
エグゼキュータ数の考え方は次の通りです。OSやHadoopデーモンもCPUを使用するため、各ノードに5コアを残し35コア(クラスタとしては210コア)をSparkに割り当てます。1エグゼキュータのCPUコア数は5コアと定めたので、エグゼキュータ数は最大42個設定できます。ただしドライバに割り当てるコアも必要なので、本検証ではエグゼキュータ数を41個に設定します。
ドライバのメモリ容量と1エグゼキュータのメモリ容量の考え方は次の通りです。OSやHadoopデーモンもメモリを使用することを考慮して、クラスタメモリ容量の75%(1,728GB)をSparkが使うものとします。よって、エグゼキュータとドライバ1個当たりのメモリ容量は約42GBです。ただしこの値は、ドライバとエグゼキュータのオーバーヘッド確保容量も含んだものです。オーバーヘッド確保容量はそれぞれ10%が初期設定されています。これらを考慮してドライバと1エグゼキュータのメモリ容量はそれぞれ37GBに設定します。
シリアライザは、ネットワーク転送やキャッシュ時のシリアライズ処理をデフォルト設定のJavaシリアライザよりも高速処理できるため、Kryoシリアライザを設定します。
※:Cloudera Engineer Blog - How-to: Tune Your Apache Spark Jobs (Part2) [http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/]
検証結果
検証結果を図9に示します。データ量が1日分と30日分のときは、Spark 1.6よりもSpark 2.0の方が高速に処理を完了できていることが分かります。しかしデータ量が365日分のとき、Spark 1.6ではジョブが完了せずに失敗しました。Spark 2.0ではジョブ完了までに13,281秒(約3時間40分)を要しており、これは30日分のデータ量での結果と比べると、データ量の割に非常に時間がかかっていると言えます。
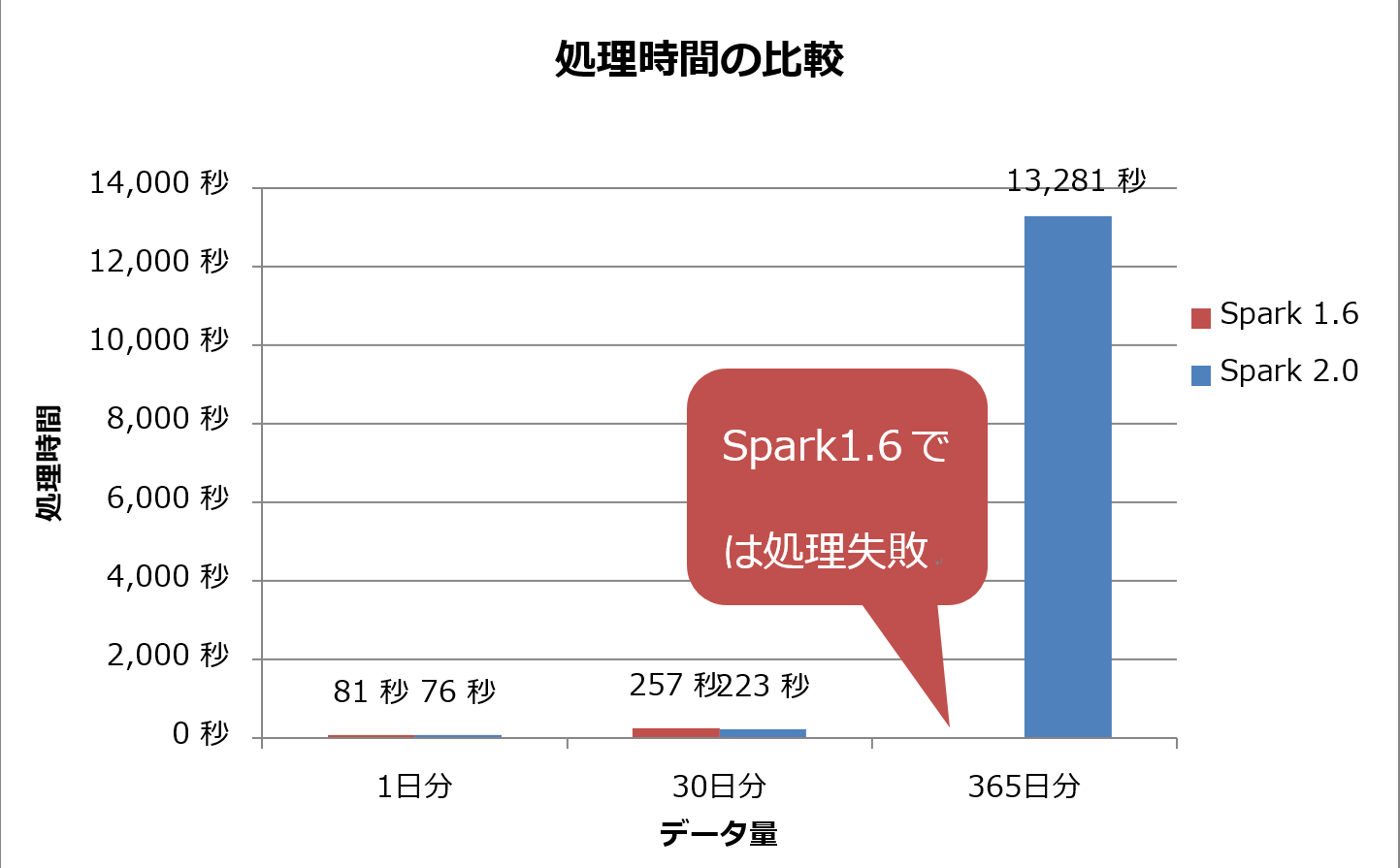
図9:Spark 2.0とSpark 1.6のデータ処理時間
おわりに
今回は、検証シナリオに基づいて実際にデータ処理基盤を構築し、データ処理にかかる時間を測定しました。1日分と30日分の消費電力量データを集計するとき、Spark 1.6よりもSpark 2.0の方が高速に処理を完了できることを確認できましたが、365日分の消費電力量データを集計処理するとSpark 2.0では処理時間が著しく長くなり、Spark 1.6はジョブが完了せず失敗しました。
次回は、なぜこのような結果になったのか、その原因について考察します。また、対策としてパラメータチューニングを施し、処理時間の短縮を試みます。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
