Kafka+Spark Streaming+Elasticserachによるシステム構築と検証の進め方
2016年7月27日 0:00
はじめに
前回はSpark Streamingの概要と検証シナリオ、および構築するシステムの概要を解説しました。今回はシステムの詳細構成と検証の進め方、および初期設定における性能測定結果について解説します。
この検証ではメッセージキューのKafka、ストリームデータ処理のSpark Streaming、検索エンジンのElasticsearchを組み合わせたリアルタイムのセンサデータ処理システムを構築しています。今回はKafkaとElasticsearchの詳細なアーキテクチャやKafkaとSparkの接続時の注意点も解説します。
システムの詳細構成
マシン構成とマシンスペック
評価に向けたマシンの初期構成を図1に示します。本システムは以下のノードから構成されます。
- センサデータを収集してKafkaに送信する収集・配信ノード
- Kafkaクラスタを構成してメッセージの受け渡しを行うキューとして動作するKafkaノード
- SparkクラスタにアプリケーションをデプロイするSpark Clientノード
- Sparkクラスタのリソース管理をするSpark Masterノード
- Sparkアプリケーションの実行とデータ蓄積を行うSpark Worker+Elasticsearchノード
- 蓄積したデータを可視化するKibanaノード
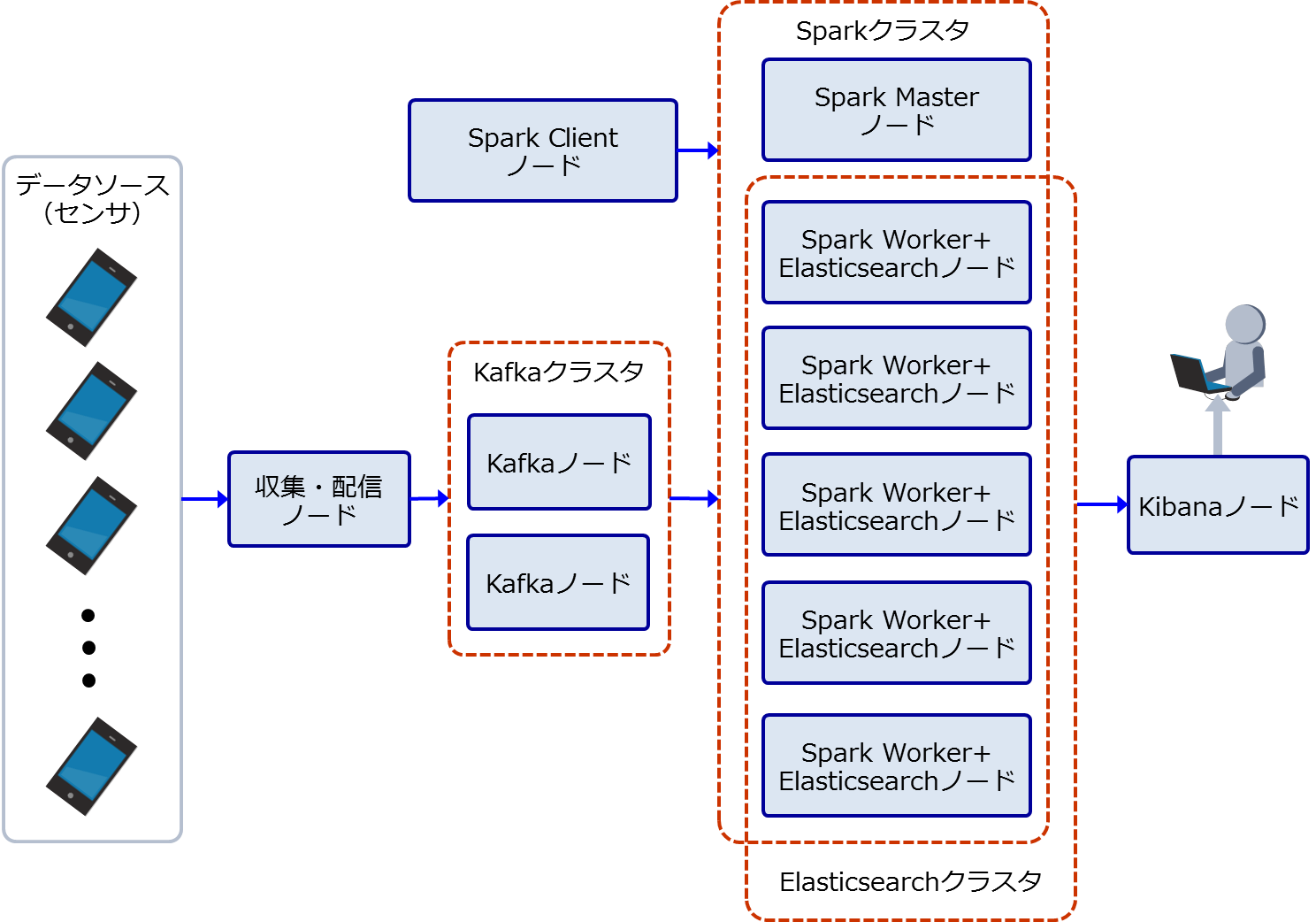
図1:マシンの初期構成
今回は仮想化環境を利用して性能評価を実施しました。初期構成のマシンスペックを表1に示します。
表1:初期構成のマシンスペック
| # | ノード | 台数 | CPUコア | メモリ | OS |
|---|---|---|---|---|---|
| 1 | 収集・配信ノード | 1 | 2 (4vCore) | 8GB | Red Hat Enterprise Linux 7.2 |
| 2 | Kafkaノード | 2 | 2 (4vCore) | 8GB | Red Hat Enterprise Linux 7.2 |
| 3 | Spark Clientノード | 1 | 2 (4vCore) | 8GB | Red Hat Enterprise Linux 7.2 |
| 4 | Spark Masterノード | 1 | 2 (4vCore) | 8GB | Red Hat Enterprise Linux 7.2 |
| 5 | Spark Worker+Elasticsearchノード | 5 | 4 (8vCore) | 16GB | Red Hat Enterprise Linux 7.2 |
| 6 | Kibanaノード | 1 | 2 (4vCore) | 8GB | Red Hat Enterprise Linux 7.2 |
測定環境
また、今回の測定は仮想化環境上で実施したため、物理環境とはディスク性能やネットワーク帯域が異なります。検証前に測定したディスク性能とネットワーク帯域を表2に示します。
表2:検証前に測定したディスク性能とネットワーク帯域
| 測定内容 | 測定結果 |
|---|---|
| ディスク性能 | シーケンシャルReadは400MB/秒、シーケンシャルWriteは1000MB/秒程度。通常のHDDがシーケンシャルRead/Write共に100MB/秒程度であることを考えると、かなり高速なディスクである。これはストレージ装置のディスクを使用しているためと考えられる |
| ネットワーク帯域 | ホスト間のネットワーク帯域は送信/受信共に112MB/秒程度。これは1Gbps回線の実質速度とほぼ一致する |
プログラムの作成とデータセットの準備
自作したプログラム
今回の検証では、下記のプログラムを自作しました。
- データ配信プログラム(BasicKafkaProducer.javaを参照)
時系列のセンサデータが記述されたテキストファイルを読み込み、Kafkaへ擬似的にストリーム配信を行うプログラム(Javaで開発) - 動作判定プログラム(HumanActivityClassifier.scalaを参照)
Kafkaからセンサデータを読み出し、センサデータから動作種別を判定して判定結果をElasticsearchへ格納するプログラム(Scalaで開発したSparkアプリケーション)
なお、Kafkaからのデータ収集とElasticsearchへの格納はSpark用のライブラリを使用します。また、動作種別の判定には事前に学習済みの機械学習モデルを使用します。このモデルについては次節で説明します。
上記プログラムの位置づけを図2に示します。
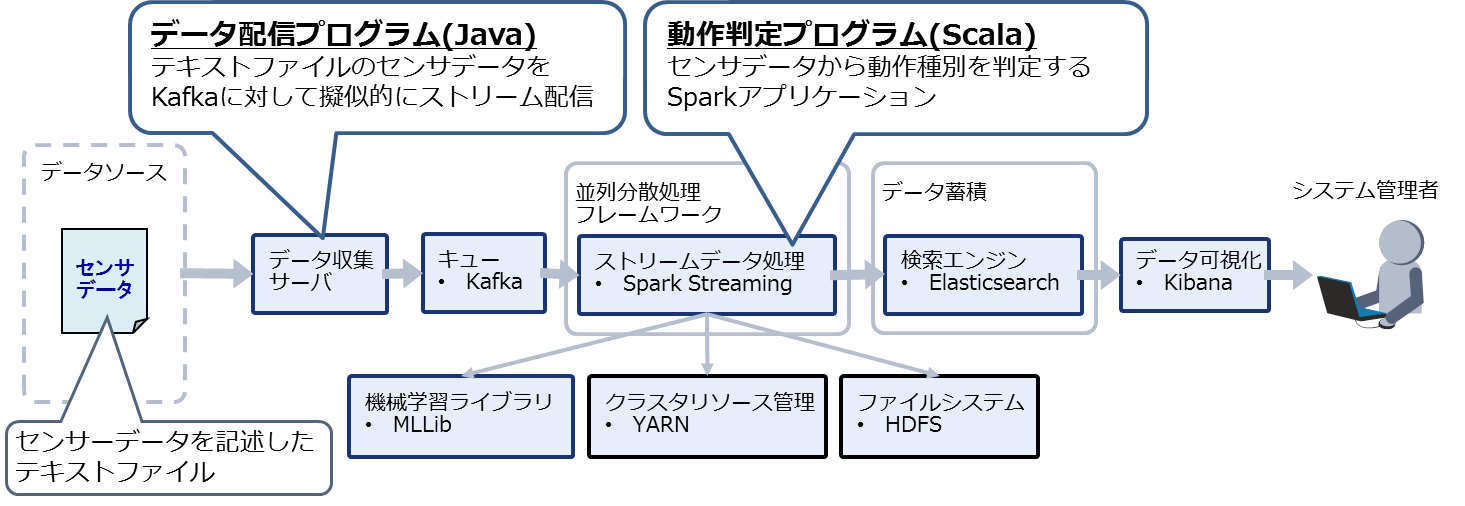
図2:作成したプログラム
検証用データセットとデータ変換内容
検証で使用するデータセットとシステム処理中のデータ変換内容は下記のようになります。
(1)学習用データ
本システムでは、Sparkの機械学習コンポーネントMLlibを使用して、事前にセンサデータから動作種別を判別するモデル(ロジスティック回帰モデル)を作成しています。この学習用データには表3に示すUCIリポジトリのオープンデータ(Human Activity Recognition Using Smartphones Data Set)を使用しました。この動作種別モデルは前述した動作判定プログラムが使用します。
表3:検証用データセット(スマートフォンの加速度センサデータ)
| # | 項目 | 内容 | |
|---|---|---|---|
| 1 | 入力値 | センサデータを表す561次元のDouble値ベクトル (X軸/Y軸/Z軸の加速度などから構成される) | |
| 2 | 出力値 | 入力値(センサデータ)に対応する動作種別。以下の6種類。 (1)歩いている (2)階段を上っている (3)階段を下っている (4)座っている (5)立っている (6)寝ている | |
| 3 | 学習用 | データ個数 | 7352個 |
| 4 | データサイズ | 1データ:8.76kb(8976byte)、全データ:62.9MB | |
| 5 | 評価用 | データ個数 | 2947個 |
| 6 | データサイズ | 1データ:8.76kb(8976byte)、全データ:25.2MB | |
(2)配信データ
測定時には表3の評価用データを使用します。前述したデータ配信プログラムがテキストファイルから評価用データを読み込み、時刻と端末IDを付与してJSON形式のデータに変換してKafkaへ配信します。配信データの詳細を表4に示します。
表4:配信データの詳細
| # | 項目 | 内容 |
|---|---|---|
| 1 | 1メッセージの内容 | 時刻(ミリ秒表記のUNIX time) |
| 2 | 端末ID(5-10文字程度) | |
| 3 | センサデータ(561個のDouble値。表3を参照) | |
| 4 | 1メッセージのサイズ | 8.81kb(9,028byte) |
| 5 | メッセージのフォーマット | JSON形式 |
| 6 | 1メッセージの例 | { "time": 1457056210797, "user": "Test User", "data": "2.5717778e-001 …<省略>… -5.7978304e-002" } |
(3)出力データ
Sparkアプリケーションは、表4の配信データに含まれるセンサデータから動作種別を判定します。判定後の動作種別は表3の出力値で示した以下の6種類です。
- 歩いている
- 階段を上っている
- 階段を下っている
- 座っている
- 立っている
- 寝ている
また、SparkアプリケーションはUNIX time表記の時刻を文字列表記に変換します。Sparkアプリケーションの変換結果はElasticsearchに格納されます。変換結果の例(約75byteのJSON形式データ)を以下に示します。
{
"time": "2016/03/31 12:00:00.000",
"user": "Test User",
"activity": "RUNNING"
}
システムの処理の流れ
本システムの処理の流れを以下に示します。
- 収集サーバ上のデータ配信プログラムはテキストファイルに記述されたセンサデータを一定間隔で読み込み、疑似的なストリーミングデータとしてKafkaに送信する
- Kafkaは処理データ量の増加に対応するため、収集サーバから受信したデータをキューイングする
- Sparkアプリケーションは一定間隔でKafkaからデータを読み出し、学習済みの動作種別モデルを用いてセンサデータから動作種別を判定してElasticsearchに格納する
- KibanaはElasticsearchに格納された動作種別の時系列データを可視化する
以上のシステムの処理の流れを図3に示します。
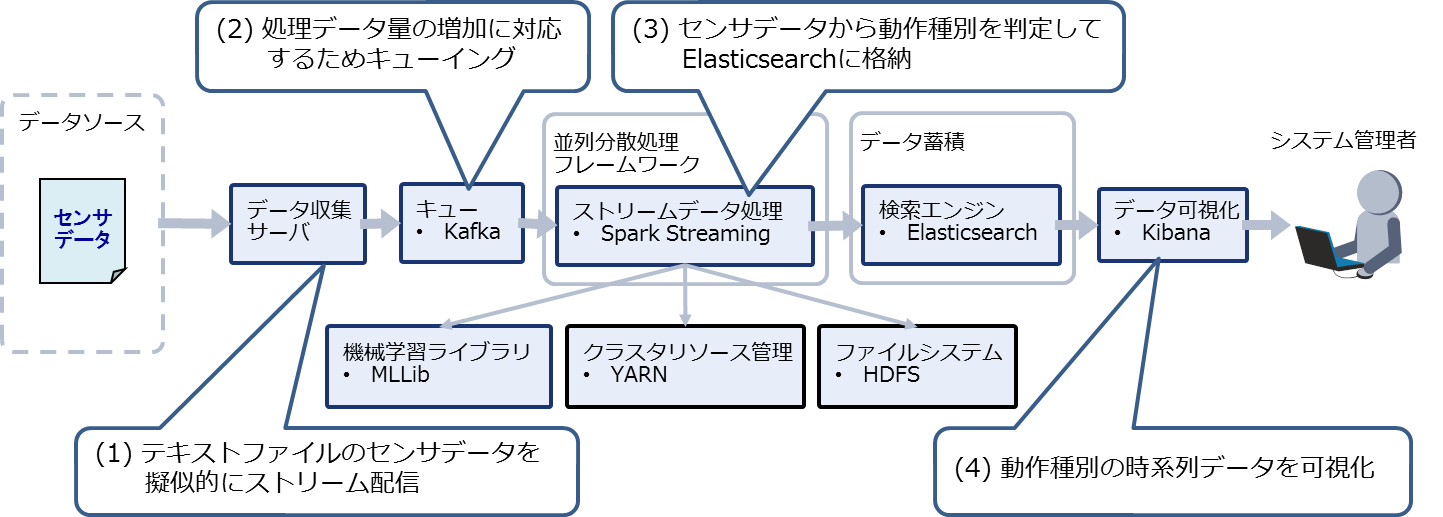
図3:システムの処理の流れ
検証の進め方
今回の検証では、まずデフォルトのパラメータで設定した各OSSを用いて、単位時間当たりの処理メッセージ数(データ量)を測定します。その後、各OSSのパラメータチューニングとシステム構成の変更を行い、性能がどこまで改善するかを検証します。
測定範囲
性能の測定範囲を図4に示します。今回のシステムでは、配信サーバからKafkaにデータを格納するまでの処理とKafkaからデータを取り出してSparkで処理し、Elasticsearchに格納するまでの処理がそれぞれ一連の処理となります。測定項目を表5に示します。
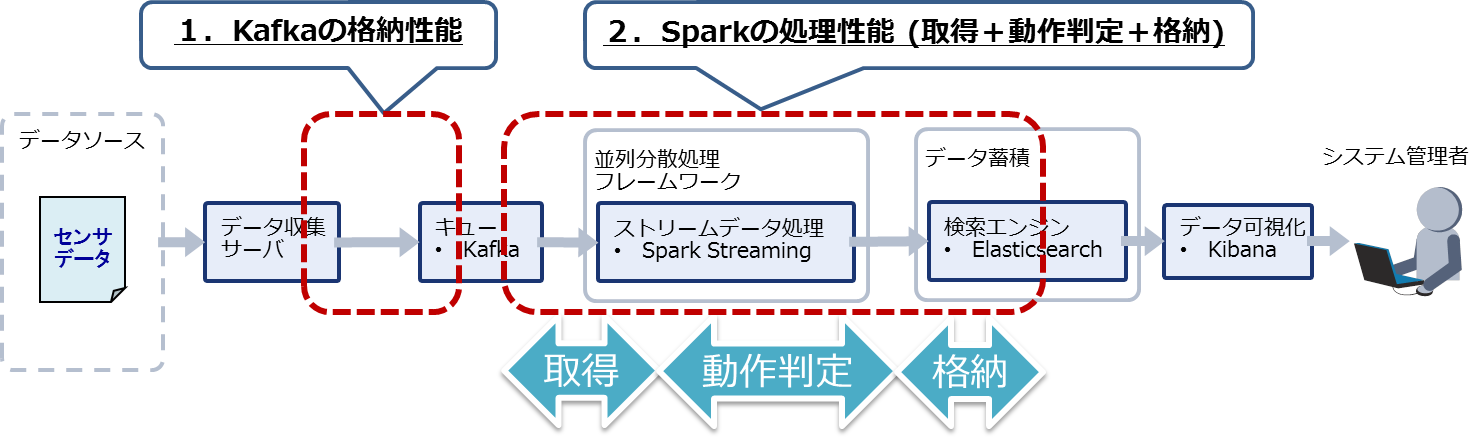
図4:測定範囲
表5:性能の測定項目
| # | OSS | 測定内容 |
|---|---|---|
| 1 | Kafka | Kafkaキューへの書き込み時間 |
| 2 | Kafkaキューからの読み込み時間 | |
| 3 | Spark Streaming | 処理時間 |
| 4 | Elasticsearch | Elasticsearchへの書き込み時間 |
目標性能と前提条件
第1回では、以下をサービスの前提条件として設定しました。
- サービスの同時利用者数は10,000人とする
- 入力データは最低1秒間隔で音楽配信サービスに通知される
- 動作の変化を判断した場合は5秒以内に選曲を行う
今回は、この前提条件から、以下の目標性能を設定します。
- Kafkaの格納性能とSparkの処理性能は共に10,000メッセージ/秒以上
- Sparkの処理インターバルは5秒以内
また、本システムではモバイル端末のストレージ容量を節約するため、送信済みのデータはモバイル端末に残さない前提とします。そのため、システム障害時にはモバイル端末から受信したデータを失わないようにする必要があります。そこで、以下のようなデータ保護に関する要件を追加します。
- KafkaおよびElasticsearchではデータのレプリカを作成する
- Elasticsearchではトランザクションログを同期的に書き込む
上記の要件にあるデータのレプリカ作成とElasticsearchのトランザクションログの詳細については後述します。
測定方法と性能の算出方法
今回の測定は、Kafkaへのメッセージ格納とSparkによるメッセージ取得・動作判定・格納処理を並列で実行した状態で行いました。Kafkaに300秒間メッセージを格納し続け、SparkはKafkaからメッセージを5秒間隔で取得し、動作判定とElasticsearchへの格納を行います。この300秒間の処理における秒間処理メッセージ数を測定しています。
KafkaはProducerからBrokerに書き込みした秒間メッセージ数を使用します。SparkはKafkaが格納したメッセージを1インターバル(5秒)のうち何秒で処理できたかを元に秒間処理メッセージ数を算出します。例えばKafkaに秒間10,000メッセージが格納され、それをSparkが1インターバル(5秒)のうち2.5秒ですべてを処理した場合、50,000/2.5=秒間20,000メッセージを処理したと計算します。
選択したOSSの詳細
今回の性能測定では、SparkのほかにKafkaとElasticsearchの性能が影響します。そのため、ここで改めてKafkaとElasticsearchの詳細を説明します。
Kafka
KafkaはPub/Subメッセージングモデルを採用した分散メッセージキューであり、スケーラビリティに優れた構成となっています(図5)。
Kafkaは複数台のBrokerノードでクラスタを構成し、クラスタ上にTopicと呼ばれるキューを作成します。 書き込み側は入力メッセージをProducerという書き込み用ライブラリを通じてBrokerクラスタ上のTopicに書き込み、読み出し側はConsumerという読み出し用ライブラリを通じてTopicからメッセージを取り出します。
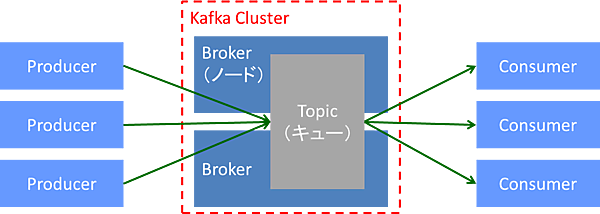
図5:Kafkaの仕組み
Kafkaの特徴を表6に、詳細なアーキテクチャを図6に示します。
表6:Kafkaの特徴
| # | 特徴 |
|---|---|
| 1 | キュー(Topicと呼ばれる)を複数定義可能 |
| 2 | 1つのキューに並列で書き込み/読み出しが可能 |
| 3 | クラスタ内でキューのレプリカを作成可能 |
| 4 | メッセージの永続化は保証しない(メモリ上に保持して定期的にディスク書き込み) ※レプリカも最初はメモリ上に保持して定期的にディスク書き込み |
Kafkaは仮想的な1つのキュー(Topic)を複数のノード(Broker)上に分散配置したパーティション(Partition)で構成します。このパーティション単位でデータを書き込み/読み込みして1つのキュー(Topic)に並列書き込み/読み出しを実現します。パーティション内のメッセージは一定期間が経過した後で自動的に削除されます。また、パーティションの容量を指定して容量を超えた分のメッセージを自動的に削除することも可能です。
書き込み側のアプリケーションはProducerを使用してメッセージを送信します。メッセージはランダムにTopicのどれか1つのパーティションに書き込まれます。Producerの仕組みについては後述します。
読み出し側のアプリケーションは1つ以上のConsumerを使用してConsumerグループを構成し、メッセージを並列に読み出します。Topicの各パーティションはConsumerグループ内の特定の1Consumerのみが読み出します。これによりTopicのメッセージを並列かつ(Consumerグループ内では)重複なく読み出すことができます。
また、各Consumerがメッセージをどこまで読み出したかはConsumer側で管理し、Broker側では排他制御を行いません。そのため、Consumer数が増加してもBroker側の負担は少なくて済みます。

図6:Kafkaのアーキテクチャ
Kafkaはクラスタ内のBroker間でパーティションのレプリカを作成します(図7)。レプリカの作成数は指定可能です。レプリカはLeader/Follower型と呼ばれ、読み書きできるのはLeaderのみです。メッセージはLeader/Follower共にOSページキャッシュに書き込まれるため、永続化の保証はありません(定期的にディスクへ書き込まれます)。BrokerはProducerがパーティションに書き込むときにAckを返します。このAckの返却タイミングは即時、Leaderの書き込み完了時、全Followerのレプリケート完了時のいずれかを指定できます。
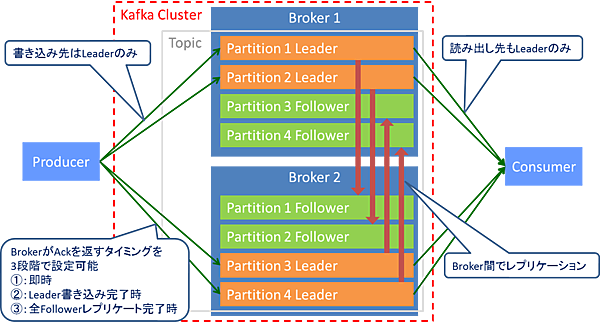
図7:Kafkaのパーティションのレプリケーション
Producerの仕組みを図8に示します。ユーザアプリケーションはProducerのAPIを通じて送信したいメッセージを登録します。Producerは登録されたメッセージをBatchという単位でバッファリングします。Batchはパーティション単位でキューイングされ、各キューの先頭のBatchがBroker単位でまとめて送信されます(これをリクエストと呼びます)。Brokerは受信したリクエストに含まれる各Batch内のメッセージを対応するパーティションに格納します。
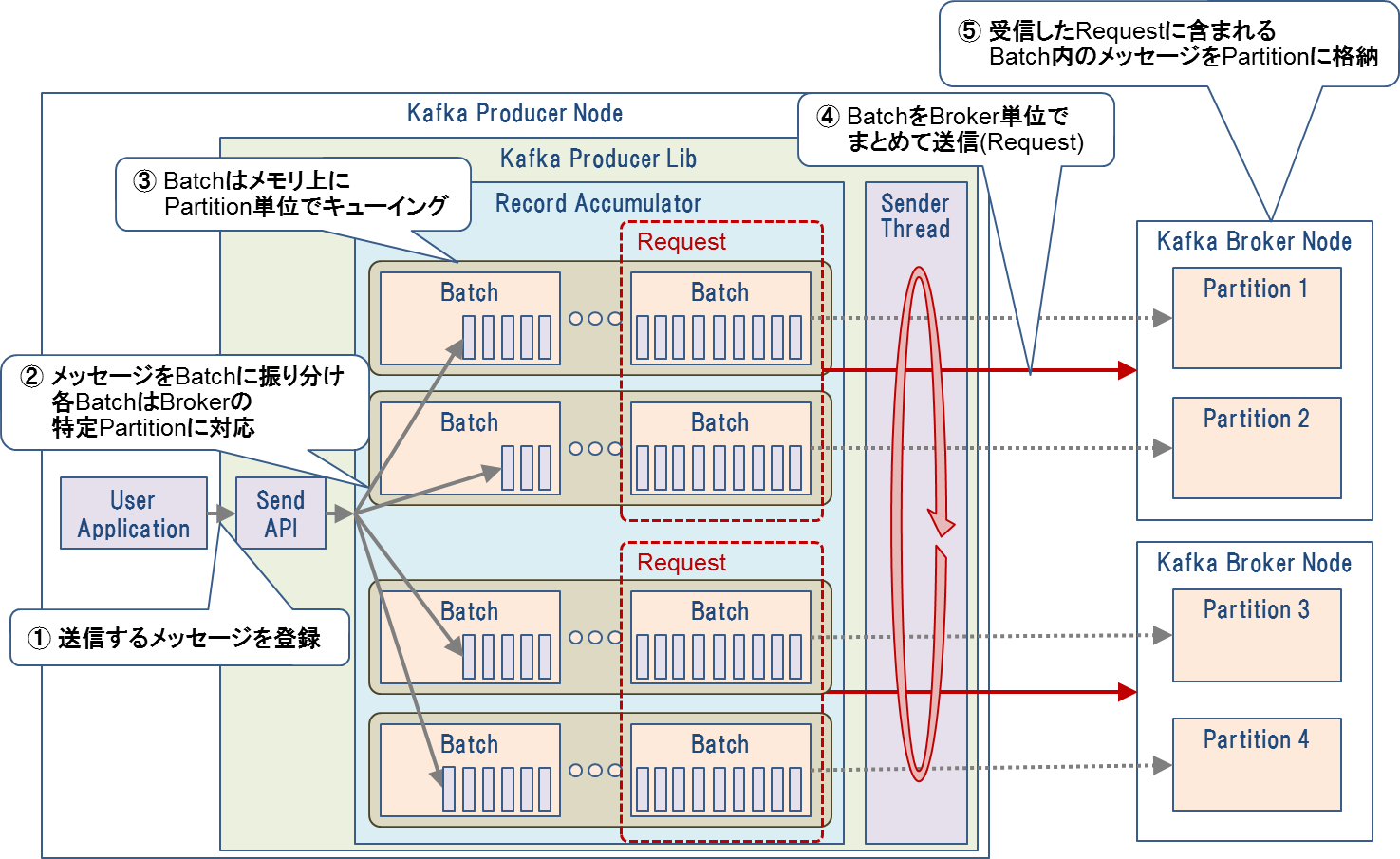
図8:Kafka Producerの仕組み
Elasticsearch
Elasticsearchは全文検索エンジンです。Elasticsearchのデータ構造とデータ格納処理の流れを解説します。
(a)Elasticsearchのデータ構造
Elasticsearchのデータ構造を図9に示します。Elasticsearchは複数台のノードでクラスタを組み、データを分散して保持できます。またIndex(RDBMSにおけるDatabaseに相当)を各ノードに分散させた複数のシャードで構成します。シャードは耐障害性を確保するためにレプリカを作成できます(デフォルトでは1個)。Index内には複数のType(RDBMSにおけるTableに相当)を作成でき、Typeには複数のドキュメント(RDBMSにおけるレコード(Tableの一行)に相当)を格納します。
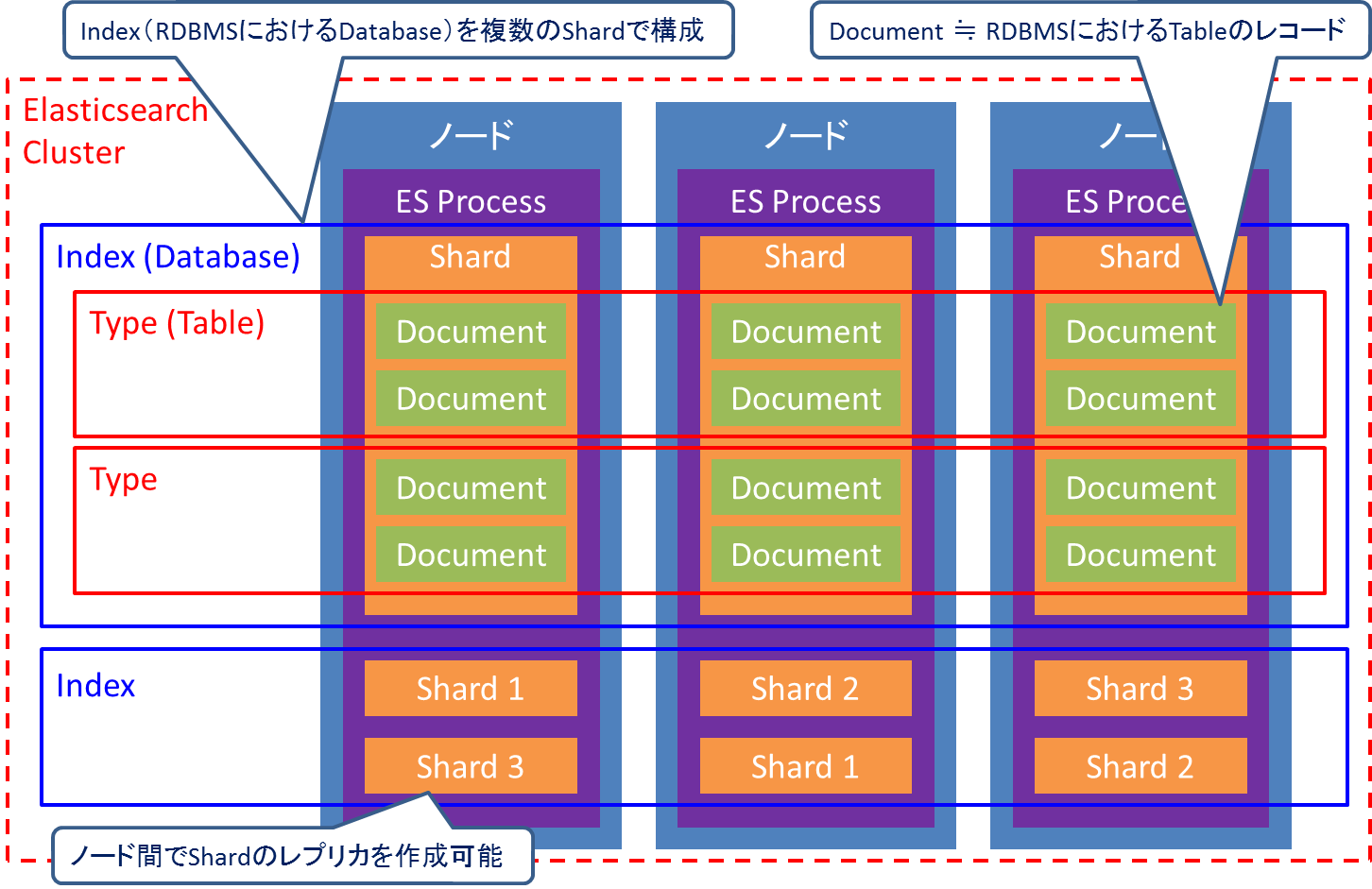
図9:Elasticsearchのデータ構造
今回構築したシステムでは、Sparkで動作種別を判定したメッセージをElasticsearchにドキュメントとして格納しています。
(b)Elasticsearchのデータ格納処理の流れ
Elasticsearchのデータ格納処理の流れを以下に示します。
(1)格納リクエスト
Sparkは動作種別の判定結果をElasticsearchに格納するため、処理インターバルごとに格納リクエストを発行します。これにはElastic社が提供するSpark用のライブラリを使用します。
このライブラリでは格納リクエストにBulkリクエストを使用します。Bulkリクエストには1回のリクエストに複数のリクエストを含ませることができ、これを利用して複数のドキュメントを1回のリクエストにまとめて格納します。なお、格納リクエストのプロトコルはHTTP POSTです。
(2)インメモリバッファに格納
ElasticsearchがIndexリクエストで受け取ったドキュメントは、まずインメモリバッファに書き込まれます。
(3)トランスログを書き込み
Elasticsearchはリクエスト内容をディスク上のトランスログ(トランザクションログ)に書き込みます。デフォルト設定ではリクエストごとに同期書き込みを行います。このトランスログは永続化前のドキュメントが障害により失われた際の復旧に使用されます。
(4)リフレッシュ(ソフトコミット)
Elasticsearchでは定期的(デフォルトでは1秒間隔)にリフレッシュ処理が行われ、インメモリバッファ上のドキュメントが検索可能となります。これは擬似リアルタイム検索を実現するための仕組みです。リフレッシュ処理が呼ばれると、インメモリバッファ上のドキュメントはまとめてセグメントという固まりに変換され、ファイルシステムキャッシュ上に配置されます。
(5)フラッシュ(ハードコミット)
Elasticsearchでは以下のいずれかのタイミングでフラッシュ処理が行われ、リフレッシュ処理とファイルシステムキャッシュ上のセグメントのディスク書き込みが行われます。
- トランスログのサイズが上限(デフォルトでは512MB)に達した
- 前回のフラッシュから一定時間(デフォルトでは30分)が経過した
- 前回のフラッシュから一定回数(デフォルトでは無制限)の操作(リクエストなど)が行われた
フラッシュ処理が完了するとメモリ上のドキュメントはすべて永続化されるため、トランスログは不要となり消去されます。
以上のデータ格納処理の流れを図10に示します。
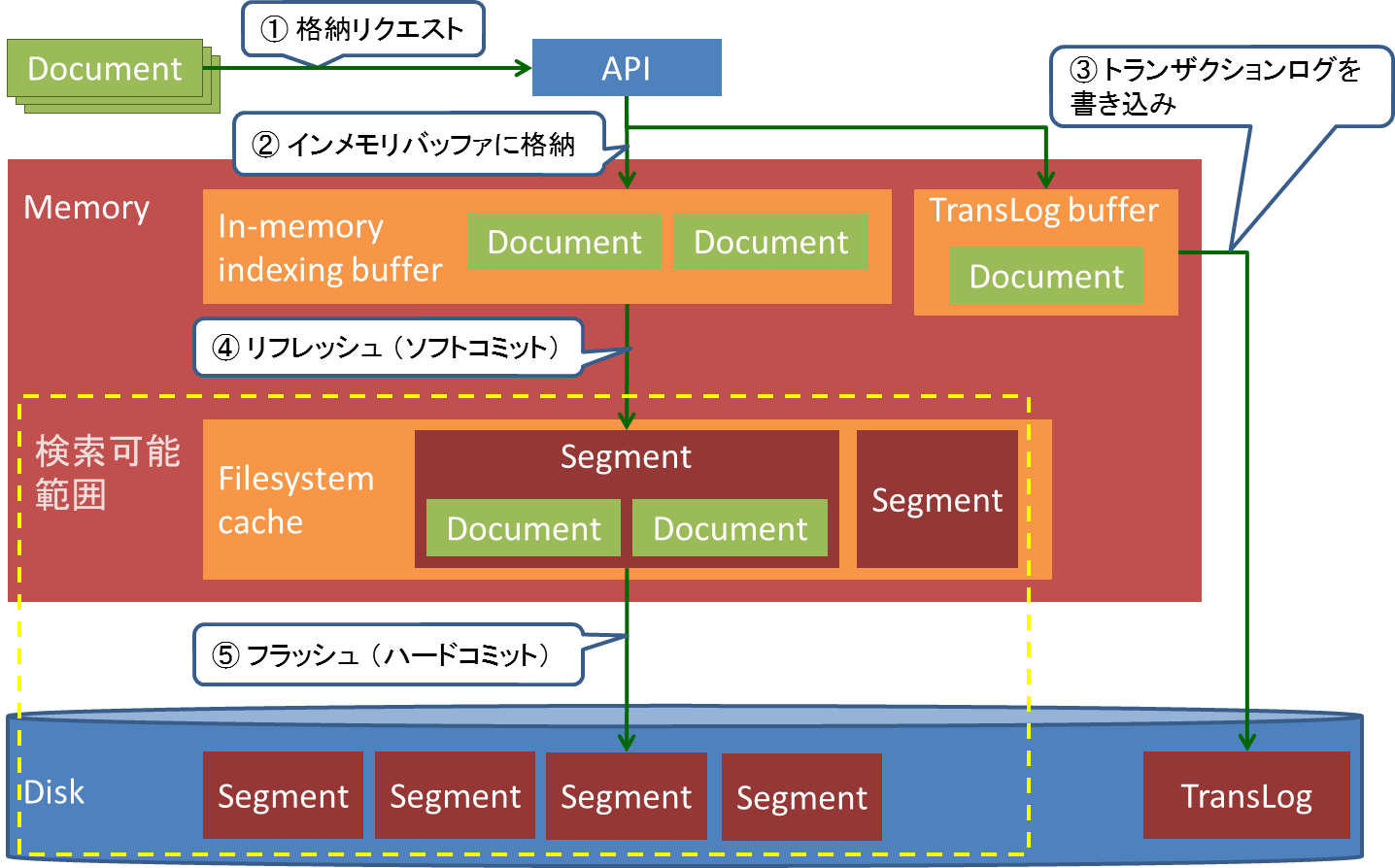
図10:Elasticsearchのデータ格納処理の流れ
測定の初期設定と測定結果
測定の初期設定
今回の評価では、基本的に各OSSで設定可能なパラメータはデフォルト値を利用します。デフォルト値がなく設定が必要なパラメータと、デフォルト値から変更したパラメータを表7に示します。
表7:初期パラメータ
| # | 対象OSS | パラメータ | 設定値 | 理由 |
|---|---|---|---|---|
| 1 | Kafka | パーティション数 | 32個 | 後述 |
| 2 | レプリカ作成数 | 1個 | 「目標性能と前提条件」の項を参照 | |
| 3 | Spark | 処理インターバル | 5秒 | 「目標性能と前提条件」の項を参照 |
| 4 | ドライバプログラムのコア数 | 8個 | ワーカノード1台のリソースをすべてドライバプログラム*1に割り当てるため、ワーカノードのCPUコア数「8」を設定 | |
| 5 | ドライバプログラムのメモリ量 | 12GB | ワーカノードのメモリ容量は16GBのため、OSやElasticsearchが使用する4GBを確保し、残りの12GBを割り当て | |
| 6 | エグゼキュータ数 | 4個 | ワーカノード5台のうち、ドライバプログラムが1台を使用するため、残り4台にエグゼキュータ*2を1個ずつ割り当て | |
| 7 | エグゼキュータのコア数 | 8個 | ワーカノード1台のリソースをすべてエグゼキュータに割り当てるため、ワーカノードのCPUコア数「8」を設定 | |
| 8 | エグゼキュータのメモリ量 | 12GB | ワーカノードのメモリ容量は16GBのため、OSやElasticsearchが使用する4GBを確保し、残りの12GBを割り当て | |
| 9 | Elasticsearch | レプリカ作成数 | 1個 | 「目標性能と前提条件」の項を参照 |
※1 ドライバプログラムはSparkアプリケーションの実行中にワーカノードに常駐してアプリケーション全体のタスク実行を管理する
※2 エグゼキュータはSparkアプリケーションの実行中にワーカノードに常駐してタスクを実行する
表7でKafkaのパーティション数を32個に設定した理由について解説しましょう。まず、SparkがKafkaからデータを取得する方式には2種類(Spark Streaming + Kafka Integration Guide)があります(表8)。
表8:Kafkaからのデータ取得方式
| # | 方式 | 説明 |
|---|---|---|
| 1 | レシーバタスクを使用する | Kafkaからデータ取得するための専用タスクを立てる方式。At-least-onceを保障する(障害が発生しても各レコードが最低1回は取得される) |
| 2 | レシーバタスクを使用しない | Kafkaからのデータ取得に専用タスクを立てない方式。Spark 1.3以降で使用可能。Exactly-onceを保障する(障害が発生しても各レコードは確実に1回だけ取得される)。またKafkaのパーティション数と同数のSparkタスクが自動生成され、Kafkaの1パーティションのメッセージをSparkの1タスクが処理する |
今回の検証では、レシーバタスクを使用しない方式を採用しました。この方式ではKafkaのパーティション数と同数のSparkタスクが自動生成されます。Sparkでは1タスクを1コアで処理するため、Sparkに割り当てられたコア数よりタスク数が少ない場合、一部のコアは使用されないことになります。
表7で説明した通り、検証ではSparkがワーカノード4台(4エグゼキュータ)を使用し、各ワーカノードのCPUは8コアであるため、Sparkが処理に使用できるコア数は4ワーカノード×8コア=32コアとなります。Sparkのタスク数をコア数と同数の32タスクにするため、今回の検証ではKafkaのパーティション数を32個としました。
初期設定における測定結果
表7の初期設定で測定した結果、Kafkaには1秒間で平均8,026メッセージが格納され、それをSparkが1インターバル5秒のうち平均2.07秒ですべて処理しました。Kafkaの格納性能は8,026メッセージ/秒、Sparkの処理性能は8,026×5/2.07=19,346メッセージ/秒になります。
よってKafkaがボトルネックとなり、システム全体でリアルタイムに処理できるのは8,026メッセージ/秒となります(図11)。デフォルト設定では、目標性能である10,000メッセージ/秒の処理性能を満たすことはできませんでした。
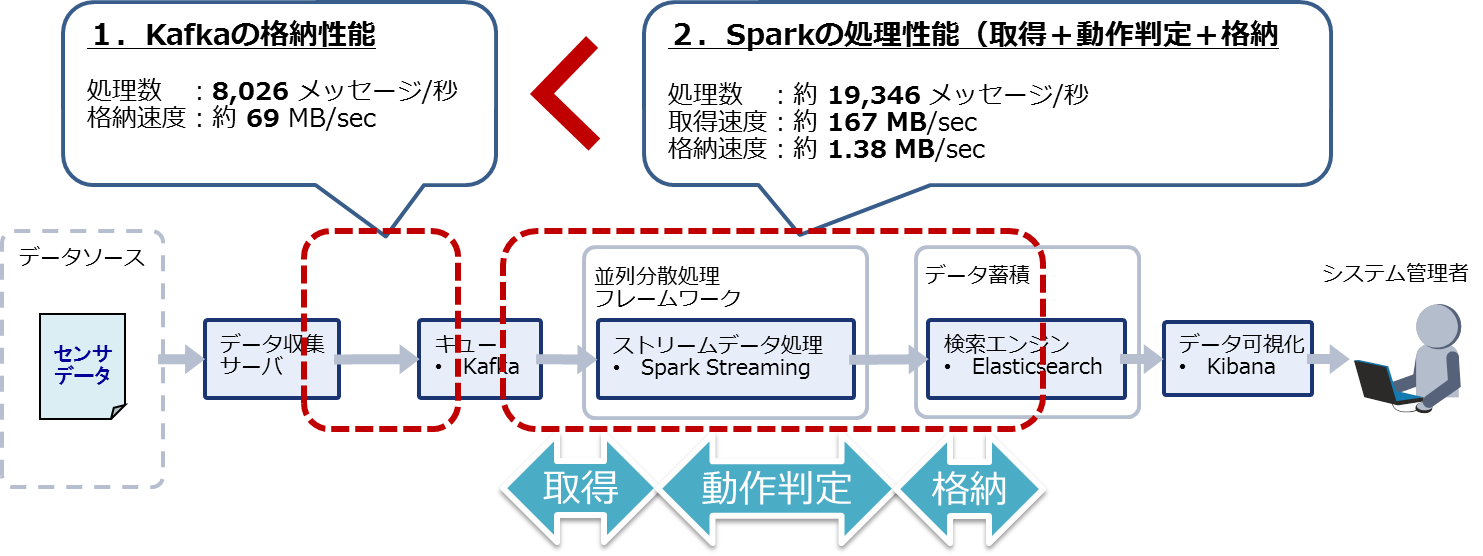
図11:デフォルト設定における測定結果
おわりに
今回はシステムの詳細構成から、初期設定における検証結果までを解説しました。次回は、システムのパラメータチューニングを行い、性能がどこまで改善したのかについて解説します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
