Kafka、Spark、Elasticsearchのパラメータチューニング
2016年8月18日 0:00
はじめに
第2回では、Spark Streamingを中心としたリアルタイムなセンサデータ処理システムの構築方法と、性能検証の進め方、および初期設定における性能測定結果を解説しました。
今回はシステムを構成するメッセージキュー「Kafka」、ストリームデータ処理エンジン「Spark Streaming」、検索エンジン「Elasticsearch」のチューニング方法と、チューニング後の性能測定結果について解説します。
前回のおさらい:初期設定における測定結果
初期設定で測定した結果、Kafkaの格納性能は8,026メッセージ/秒、Sparkの処理性能は19,346メッセージ/秒となりました。Kafkaがボトルネックとなり、システム全体のリアルタイム処理は8,026メッセージ/秒となります(図1)。この結果から、初期設定では第2回で解説した目標性能である10,000メッセージ/秒の処理性能を満たすことはできませんでした。
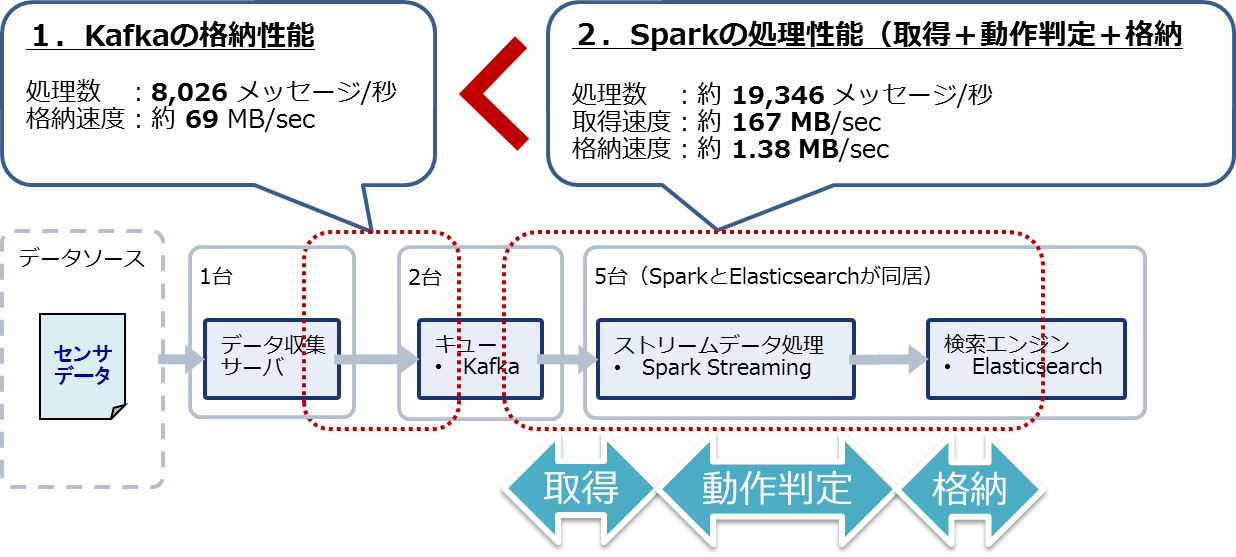
図1:初期設定における測定結果
Kafkaのパラメータチューニング
KafkaのProducer(データ送信ライブラリ)はメッセージをバッファリングし、まとめてBroker(キューサーバー)に送信します。そのためBrokerだけでなくProducerのパラメータチューニングも重要になります。なお、ProducerおよびBrokerの仕組みについては第2回の解説を参照してください。
Kafkaの格納性能に影響するパラメータ
Producerの送信性能に影響するパラメータを表1に示します。また、表1の各パラメータが送信処理のどこに影響するのかを図2に示します。
表1:Kafka Producerの送信性能に影響するパラメータ
| # | パラメータ ※ | デフォルト値 | 説明 |
|---|---|---|---|
| 1 | メモリバッファサイズ (buffer.memory) | 32MB | Producerが使用できるメモリ量。この値を増やすとキューイングできるメッセージ数が増え、送信待ちデータが増加した際にも対応できるようになる。今回の測定では送信待ちの影響をなるべく避けるため512MBで固定 |
| 2 | リクエストサイズ (max.request.size) | 1MB | ProducerのバッチはBrokerのパーティションに対応し、1Brokerのパーティションに対応する全バッチに格納されたメッセージの合計サイズがこの上限に達するとリクエストが送信される。今回の測定では#3のバッチサイズのみを変動させるため、測定に影響しないように100MBで固定 |
| 3 | バッチサイズ (batch.size) | 16KB | 1つのバッチに格納できる合計メッセージサイズ。Producerはメッセージをバッチという単位でバッファリングする。1Brokerのパーティションに対応する全バッチがすべて満杯になるとリクエストが送信される |
| 4 | 送信待機時間 (linger.ms) | 0ミリ秒 | 送信用シングルスレッドのループ待機時間。Requestサイズが上限に達していなくても、この時間が経過したら送信される。今回の測定では#3のバッチサイズのみを変動させるため、測定に影響を与えないように1000ミリ秒(1秒)で固定 |
| 5 | BrokerからのAckタイミング (acks) | ②Leader書き込み完了時 | Producerからの送信リクエストにBrokerがAck(格納処理結果)を返すタイミング。①即時、②Leader書き込み完了時、③全Followerにレプリケート完了時の3段階で設定可能。①にするとBroker格納時のエラーを検知できなくなるため、今回の測定ではデフォルト値の②Leader書き込み完了時で固定 |
| 6 | 送信の同期/非同期 (ソースコード内で設定) | 非同期 | 同期送信ではProducerからの送信リクエストにBrokerがAckを返してから、非同期送信ではAckの返却を待たずに次の送信を開始する。なお、送信エラーの検知は非同期送信でも可能(Producerのコールバック関数が呼ばれる)。同期送信は極めて遅く、特にメリットがないため今回の測定ではデフォルト値の非同期で固定 |
※: ()内はパラメータ名を表す。パラメータはKafka Producerのプロパティファイルまたはソースコード内で設定する
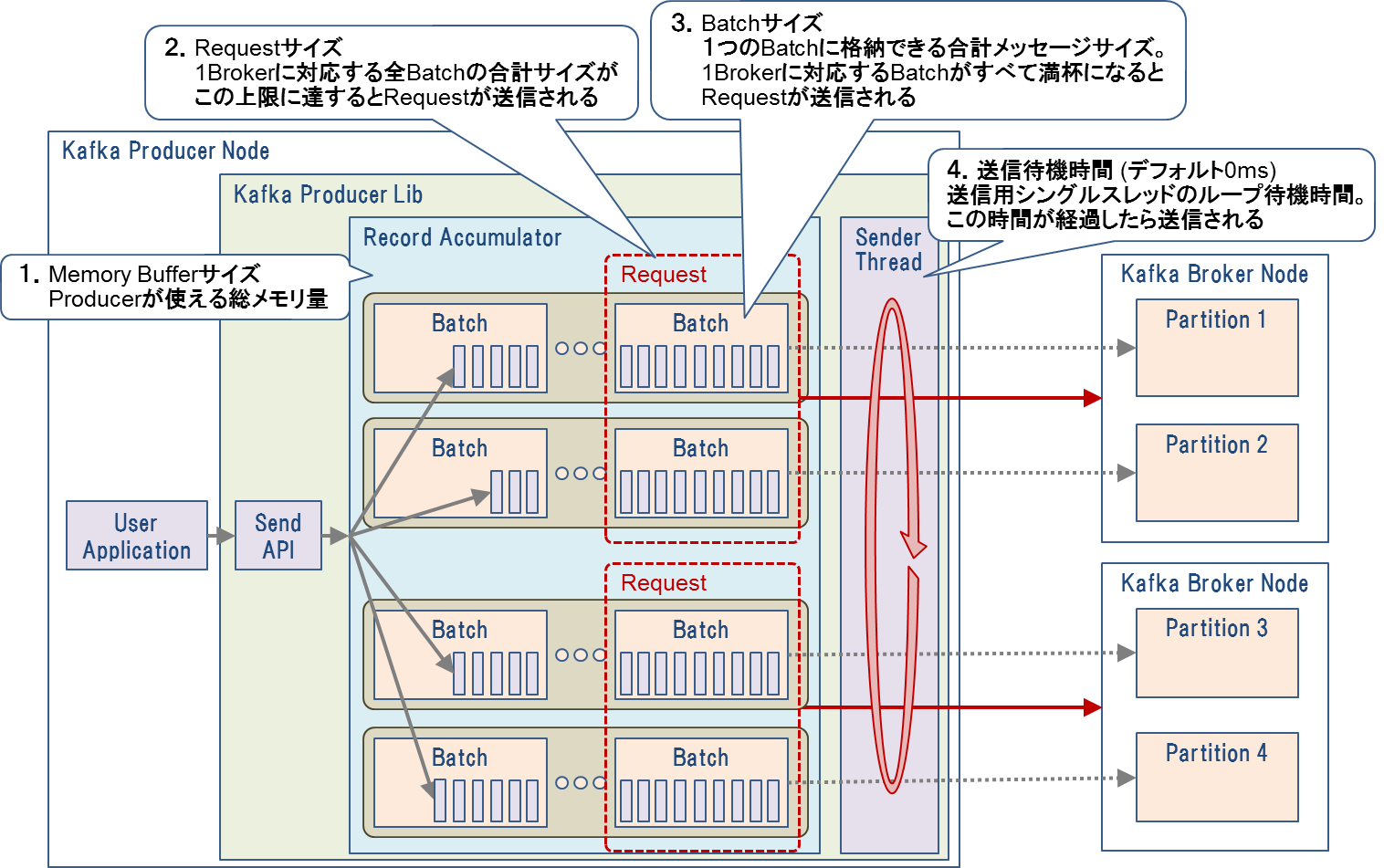
図2:Kafka Producerのパラメータ
Producerは表1#2のリクエストサイズ、#3のバッチサイズ、#4の送信待機時間のいずれかが上限に達した時にデータを送信します。今回はパラメータチューニングの効果を明確にするため、送信データ量を調整しやすい#3のバッチサイズのみを変動させて、他のパラメータは固定して測定しました。
Brokerの格納性能に影響するパラメータを表2に示します。今回の測定では変更可能なパラメータがないため、すべて固定値としました。
表2:Kafka Brokerの格納性能に影響するパラメータ
| # | パラメータ ※ | デフォルト値 | 説明 |
|---|---|---|---|
| 1 | パーティション数 (partitions) | 1個 | 1トピック(Kafkaのキュー)を構成するパーティション数。第2回で説明した通りSpark StreamingはKafkaのパーティション数と同数のタスクを生成して処理を行うため、Sparkクラスタのコア数(4ノード×8コア=32個)に合わせる |
| 2 | レプリカ作成数 (replication-factor) | 1個 | パーティションのレプリカ作成数(メインのパーティションを含むため1個=メインのパーティションのみでレプリカなし)。第2回で説明したデータ保護の要件から、システム障害時にデータを失わないようレプリカを作成する必要がある。今回の測定では2個(メインのパーティション+レプリカ1個作成)で固定 |
※: ()内はパラメータ名を表す。パラメータはコマンドラインからのトピック作成時に設定する
Kafkaのチューニング結果
ここまでに説明した理由から、今回の測定ではProducerのバッチサイズのみを変動させ、他のパラメータは固定して測定を行いました。測定時のパラメータを表3に示します。
表3:Kafkaの測定時のパラメータ
| # | コンポーネント | パラメータ | 測定値 |
|---|---|---|---|
| 1 | Producer | メモリバッファサイズ | 512MB(固定) |
| 2 | リクエストサイズ | 100MB(固定) | |
| 3 | バッチサイズ | 16~160KB | |
| 4 | 送信待機時間 | 1000ミリ秒(固定) | |
| 5 | BrokerからのAckタイミング | Leader書き込み完了時 | |
| 6 | 送信の同期/非同期 | 非同期(固定) | |
| 7 | Broker | パーティション数 | 32個(固定) |
| 8 | レプリカ作成数 | 2個 |
測定結果を図3に示します。バッチサイズが112KBのときに格納性能が最も高くなることが判明しました。よって、目標性能である10,000メッセージ/秒の格納性能はKafkaのチューニングのみで満たせることになります。

図3:Kafka Producerのバッチサイズと格納メッセージ数
Sparkのパラメータチューニング
初期設定での測定結果では、Sparkの処理性能はすでに目標性能(10,000メッセージ/秒)を満たしていましたが、今回はチューニングにより処理性能をどこまで伸ばせるかを確認しました。
Sparkの処理性能に影響するパラメータ
Sparkの処理性能に影響するパラメータを表4に示します。
表4:Sparkの処理性能に影響するパラメータ
| # | パラメータ ※ | デフォルト値 | 説明 |
|---|---|---|---|
| 1 | 処理インターバル (ソースコード内で指定) | なし | Spark Streamingがマイクロバッチ処理を実行する間隔。この処理インターバルごとにKafkaからのメッセージ取得、動作種別の判定、Elasticsearchへの格納が行われる。前回説明した通り入力データを5秒以内に処理する必要があるため、処理インターバルも5秒以内である必要がある |
| 2 | エグゼキュータ数 (num-executors) | 2個 | ワーカノードで起動するエグゼキュータのプロセス数。今回の測定環境は4ワーカノードなので、1ワーカノードあたり1プロセスを起動するために4個とした |
| 3 | エグゼキュータコア数 (executor-cores) | 1個 | 各エグゼキュータプロセスに割り当てるコア数。今回の測定では1ワーカノード8コアなので、全コアを使い切るために8個とした |
| 4 | エグゼキュータメモリ量 (executor-memory) | 1GB | 各エグゼキュータプロセスに割り当てるメモリ量。今回の測定では1ワーカノードのメモリが16GBなので、OSやHadoopデーモンが使用するメモリを4GB確保するとして、残りの12GBを割り当てた |
| 5 | ドライバコア数 (driver-cores) | 1個 | ドライバプロセスに割り当てるコア数。今回の測定では1ワーカノードが8コアなので、全コアを使い切るために8個とした |
| 6 | ドライバメモリ量 (driver-memory) | 1GB | ドライバプロセスに割り当てるメモリ量。今回の測定では1ワーカノードのメモリが16GBなので、OSやHadoopデーモンが使用するメモリを4GB確保するとして、、残りの12GBを割り当てた |
| 7 | タスク数 | なし | Sparkが並列処理するタスク数。デフォルト設定では1タスクは1エグゼキュータで処理される。前回説明した通りSpark StreamingはKafkaのパーティション数と同数のタスクを生成して処理を行うため、今回の測定では32タスクとなる |
※: ※()内はパラメータ名を表す。パラメータはコマンドラインでのSparkアプリケーション実行時、またはソースコード内で設定する
Sparkのチューニング結果
Kafkaをチューニングした状態でSparkをチューニングして測定を行いました。今回の測定では、表4で示した理由から処理インターバルのみを変動させ、他は固定としました。測定時のパラメータを表5に示します。
表5:Sparkの測定時のパラメータ
| # | パラメータ | 測定値 |
|---|---|---|
| 1 | 処理インターバル | 1~8秒 |
| 2 | エグゼキュータ数 | 4個(固定) |
| 3 | エグゼキュータコア数 | 8個(固定) |
| 4 | エグゼキュータメモリ量 | 12GB(固定) |
| 5 | ドライバコア数 | 8個(固定) |
| 6 | ドライバメモリ量 | 12GB(固定) |
| 7 | タスク数 | 32個(固定) |
Sparkの処理インターバルごとの秒間処理メッセージ数を図4に示します。処理インターバルが長くなるほどSparkの処理性能が高くなることが分かります。
しかし第2回で説明した通り、今回のシステムでは入力データを5秒以内に処理する必要があるため、処理インターバルも5秒以内である必要があります。よって今回の前提条件では、処理インターバルが5秒のときに最も処理性能が高くなります。
結果として、第2回で説明した初期設定における測定時と処理インターバルは変わらず、性能は向上しませんでした。
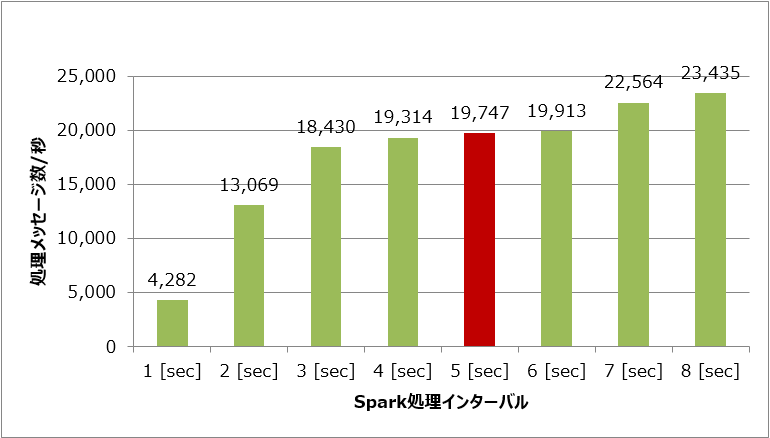
図4:Sparkの処理インターバルと処理メッセージ数
Elasticsearchのチューニング
図1で示した通り、今回測定したSparkの処理性能はKafkaからデータを取り出してSparkで処理し、Elasticsearchに格納するまでの処理時間です。そのため、Elasticsearchの格納性能をチューニングすることでSparkの処理性能がさらに向上すると考えられます。なお、Elasticsearchのデータ格納処理の流れについては第2回の解説を参照してください。
以下に、Elasticsearchのチューニング結果を示します。今回のシステム構成ではSparkのワーカノードにElasticsearchを同居させているため、Sparkクラスタのノード台数=Elasticsearchクラスタのノード台数となります。
Elasticsearchの格納性能に影響するパラメータ
前回説明したElasticsearchのデータ構造とデータ格納処理の流れから、Elasticsearchの格納性能に影響すると考えられるパラメータを表6に示します。また各パラメータが格納処理のどこに影響するのかを図5に示します。
表6:Elasticsearchの格納性能に影響するパラメータ
| # | パラメータ※ | デフォルト値 | 説明 |
|---|---|---|---|
| 1 | 格納インターバル (Sparkの処理インターバル) | なし | SparkがElasticsearchに格納リクエストを発行する間隔。Sparkの処理インターバルがElasticsearchの格納インターバルとなる。今回の測定ではSparkの処理インターバルである5秒で固定 |
| 2 | Bulkリクエスト数 (spark.es.batch.size.entries)※1 | 1,000リクエスト | 1回のBulkリクエストに含められる最大リクエスト数。このリクエスト数を超える場合は複数回に分けてBulkリクエストを行う。なおリクエストはSparkの各タスクが並列実行するため、このパラメータは1タスクあたりの最大リクエスト数となる。SparkはKafkaから取得したメッセージ(平均で秒間10,112メッセージ)をElasticsearchに格納するため、、1タスクあたりの格納ドキュメント数(=リクエスト数)は秒間10,112ドキュメント×5秒/32タスク=1,580となる。デフォルトのBulkリクエスト数は1,000で、上記のドキュメント数だとリクエストが2回に分割されるだけであり、性能への影響は小さいと考えられる。よってチューニングしても性能改善が見込めないため、今回の測定では1,000リクエストのままとした |
| 3 | Bulkリクエストサイズ (spark.es.batch.size.bytes)※1 | 1MB | 1回のBulkリクエストの最大サイズ。このサイズを超える場合は、複数回に分けてBulkリクエストを行う。リクエストはSparkの各タスクが並列実行するため、このパラメータは1タスクあたりの最大サイズとなる。#2で説明した通り1タスクあたりの格納ドキュメント数は1,580で1タスクあたりのリクエストサイズは1リクエスト1,580ドキュメント×75byte=約116KBとなる。デフォルトのBulkリクエストサイズは1MBとリクエストサイズより大きく、チューニングしても性能改善が見込めないため、今回の測定では1MBのままとした |
| 4 | トランスログのコミット間隔 (index.translog.durabilityおよび index.translog.sync_interval)※2 | リクエストごとに同期実行 (非同期の場合は秒数で指定) | Elasticsearchへのリクエスト内容をディスク上のトランスログに書き込む間隔。トランスログは永続化前のドキュメントが障害で失われた際の復旧に使用される。システム障害時にデータを失わないためには、トランザクションログをリクエストごとに同期的に書き込む必要がある。そのため今回の測定では同期実行から変更なし |
| 5 | トランスログの上限サイズ (index.translog.flush_threshold_size)※2 | 512MB | トランスログが上限サイズに達するとファイルシステムキャッシュのフラッシュ処理が実施され、メモリ上のデータがディスクに書き込まれる。Kafkaから平均で秒間10,112メッセージを取得するため、測定期間中の格納データ量は10,112メッセージ×300秒×メッセージサイズ75byte=約217MBとなる。トランスログのデフォルト上限サイズ512MBは格納データ量の2倍以上大きいため、チューニングしても性能改善が見込めないと考え、今回の測定では512MBのままとした |
| 6 | リフレッシュ間隔 (index.refresh_interval)※2 | 1秒 | インメモリバッファのドキュメントに対してセグメントファイルへの変換を実行する間隔。セグメントファイルに変換されたドキュメントは検索可能。この間隔を長くするとインデクスの作成処理は軽くなるが、検索のリアルタイム性は低下する |
| 7 | フラッシュ間隔 (index.translog.flush_threshold_period)※2 | 30分 | 前回のフラッシュからこの設定期間が経過するとフラッシュ処理が実施され、メモリ上のデータがディスクに書き込まれる。今回の測定期間は5分(300秒)だが、デフォルトのフラッシュ間隔は30分と長くチューニングしても性能改善が見込めないため、今回の測定では30分のままとした |
| 8 | インデクスのシャード数 (index.number_of_shards)※2 | 5個(ノード数) | インデクスを構成するシャード数。今回の測定ではElasticsearchが5ノードのためシャード数も5個とした |
| 9 | レプリカの作成数 (index.number_of_replicas)※2 | 1個 | シャードの複製数(メインのシャードは含まない)。複数ノードでクラスタを組む場合はノード間でシャードのレプリケーション処理が行われる。レプリカ数が多くなるとレプリケーション処理の負荷が大きくなるため今回の測定ではデフォルト値の1個で固定 |
- ※1SparkとElasticsearchの連携ライブラリ「elasticsearch-spark」の設定であるため、パラメータはコマンドラインでのSparkアプリケーションの実行時に指定するか、Sparkの設定ファイル(spark-defaults.conf)に設定する。()内はパラメータ名を表す
- ※2パラメータはElasticsearchのAPIで設定するか、Elasticsearchの設定ファイルを編集する。()内はパラメータ名を表す

図5:Elasticsearchのパラメータ
Elasticsearchのチューニング結果
KafkaとSparkがチューニング済みの状態で、Elasticsearchをチューニングして測定を行いました。測定時のパラメータを表7に示します。今回の測定では表6で示した理由から、リフレッシュ間隔以外のパラメータは固定です。
表7:Elasticsearchの測定時のパラメータ
| # | パラメータ | 測定値 |
|---|---|---|
| 1 | 格納インターバル(Sparkの処理インターバル) | 5秒(固定) |
| 2 | Bulkリクエスト数 | 1000リクエスト(固定) |
| 3 | Bulkリクエストサイズ | 1MB(固定) |
| 4 | トランスログのコミット間隔 | 同期実行(固定) |
| 5 | トランスログの上限サイズ | 8512MB(固定) |
| 6 | リフレッシュ間隔 | 1,60秒 |
| 7 | フラッシュ間隔 | 30分(固定) |
| 8 | インデクスのシャード数 | 5個(固定) |
| 9 | レプリカの作成数 | 1個(固定) |
Elasticsearchのリフレッシュ間隔を変更した際の秒間格納ドキュメント数の変化を図6に示します。リフレッシュ間隔を60秒に伸ばすことで約5%の性能向上が見られました。
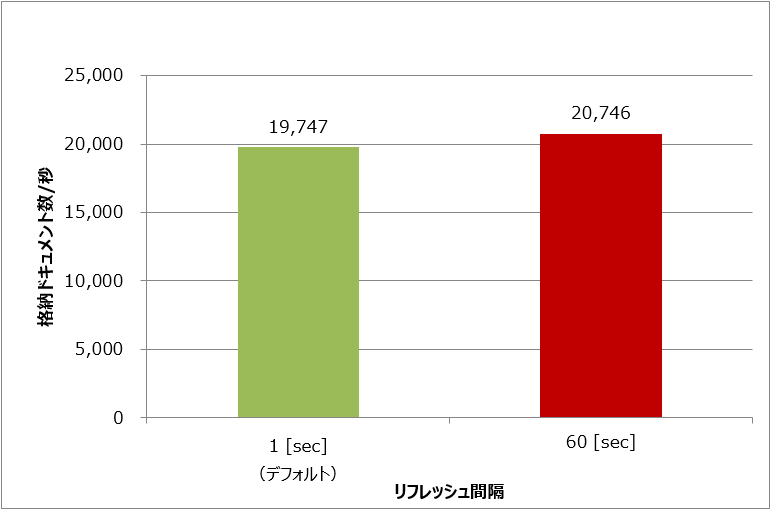
図6:Elasticsearchのリフレッシュ間隔と格納ドキュメント数
参考:性能重視のチューニング結果
上記のSparkとElasticsearchのチューニングでは処理性能が約5%しか改善されませんでした。これは今回のチューニングではレプリカを作成するなどデータの保護を重視したためです。
そこで、このデータ保護の要件を無視した場合、どの程度性能が向上するのかを測定しました。Elasticsearchのレプリカ作成を無効にして、トランスログの書き込みを非同期(60秒間隔)に設定しました。測定結果を図7に示します。
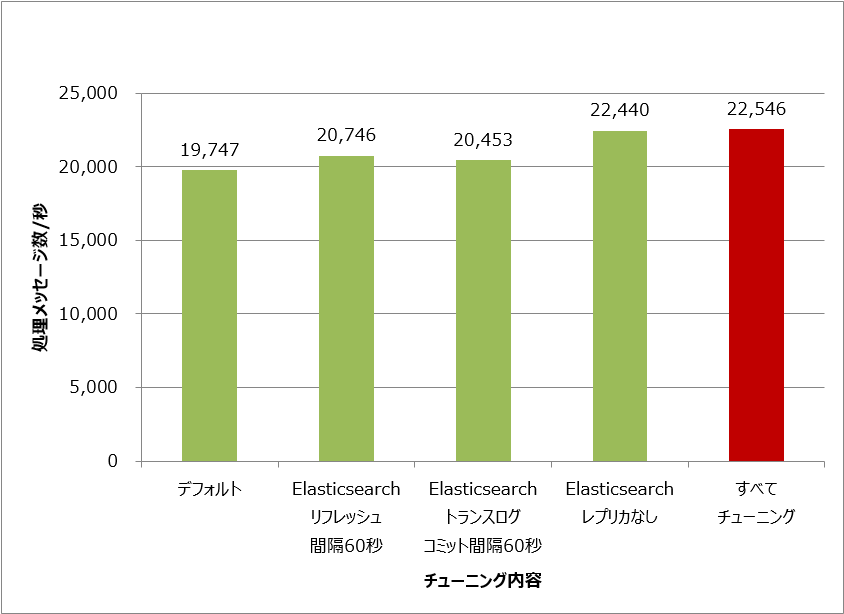
図7:性能重視のチューニングと処理メッセージ数
チューニング結果から、すべてのチューニングを行うことで約14%の性能向上が見られました。特にElasticsearchのレプリカの作成を無効にしたことで大きく性能が向上しました。
おわりに
今回はセンサデータ処理システムを構成するKafka、Spark Streaming、Elasticsearchのチューニング方法と、チューニング後の性能測定結果を解説しました。今回はデータの保護を重視したパラメータ設定で測定を行いましたが、重視する要件(障害耐性、格納性能、検索性能など)によってチューニングすべきパラメータは変わります。
次回は各OSSに割り当てるマシン台数の調整を行い、システム全体のボトルネックについて考察します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
