目次
- はじめに
- おさらい:HadoopとSparkとは何か
本連載の検証で取り上げる「Spark SQL」は、Sparkを構成するコンポーネントの1つです。またSparkもHadoopのエコシステムを構成するOSSのひとつです。そこでSpark SQLを説明する前に「HadoopとSparkとは何か」を簡単に説明します。
Hadoopの概要
HadoopはIAサーバを複数台用いて大量のデータ(ビッグデータ)を並列分散処理する基盤です。「MapReduce」と呼ばれる処理で入力データを分割して並列分散処理(Map)し、その結果を集約(Reduce)して出力データを生成します。
現在主流のバージョン2.x系は表1に示す3種類のコンポーネントで構成されます。表1:Hadoopを構成するコンポーネント一覧(2.x系) # コンポーネント 説明 1 MapReduce2 バッチ処理向け分散処理フレームワーク 2 YARN (Yet Another Resource Negotiator) クラスタリソース管理 3 HDFS (Hadoop Distributed File System) 分散ファイルシステムSparkの概要 Sparkはデータをインメモリで処理することでMapReduceの課題を解決するコンポーネントです。従来、Hadoop(MapReduce)には「HDFSを介したディスク書き込み/読み込みを繰り返すことから、全体でディスクI/Oにかかるコストが高くなる」という課題がありました。SparkもMapReduceと同様に入力データを分割して並列分散処理(Map)し、その結果を集約(Reduce)して出力データを生成しますが、その処理の大半をメモリ上で行うためMapReduceよりもディスクI/O回数が少なく高速に動作します。 Sparkは表2に示す並列分散処理のエンジンと、用途別のライブラリ群で構成されます。表2:Sparkを構成するコンポーネント一覧 # コンポーネント 説明 1 Spark Core Sparkの分散処理フレームワーク。基本機能を提供する 2 Spark SQL 構造データにSQLを利用するためのAPIを提供する 3 Spark Streaming マイクロバッチ方式によるストリームデータ処理機能を提供する 4 GraphX グラフ構造データを処理するためのAPIを提供する 5 MLlib 機械学習アルゴリズムを使用するためのAPIを提供するHadoopとSparkの概要については、「ユースケースで徹底検証! Sparkのビッグデータ処理機能を試す」で詳細に解説していますので、そちらも併せてご覧ください。 Spark 2.0の主な変更点 Spark 2.0のリリースノートに記載されている主な変更点を表3に示します。表3:Spark 2.0の主な変更点 # 変更点 説明 1 性能改善 SQLの処理速度が2倍から10倍に向上 2 Parquet/ORCファイルの読み書き性能を改善 3 Spark SQLの改善 SQLを記述するDataFrame/Dataset APIを統合※4 SQL記述方法として国際基準ANSI SQL2003をサポート 5 MLlib APIの改善 MLlibの処理をDataFrameで記述できるようになった 6 DataFrameで記述できる機械学習アルゴリズムを追加※:Spark 2.0でのDatasetとは型を持つテーブル形式のデータ集合のこと、DataFrameは型を持たないDatasetのこと。 「Spark 2.0を活用する」という視点で見ると、性能が改善していること、アプリケーションでのデータ処理(ソースコード)の記述方法が変わったことの2点が主な変更点といえます。このうち、本連載では性能改善の検証結果を解説します。 アプリケーションのソースコードを記述する上での大きな違いは、DataFrameを使うときに呼び出すAPI(エントリポイント)が変わったことです。Spark 1.6ではSQLContextおよびHiveContextでしたが、Spark 2.0ではSparkSessionが用意されました。DataFrameは概念的にはリレーショナルデータベース(RDB)のテーブルと等価とされています。そのためDataFrameだけでなくcsvやjsonのような構造化されたファイル、Hiveテーブル、RDBテーブルもSparkSessionをエントリポイントとして利用でき、エントリポイントの使い分けを意識する必要がなくなったことで処理ロジックの実装に集中できます。 本連載で検証のために作成したアプリケーションからソースコードでの違いを一部抜粋して示します。アプリケーションはScala言語で実装し、Hiveテーブルからデータを読み込んでSparkで値を足し合わせる処理をします。 importするライブラリ DataFrame APIエントリポイントが統合されたことで、importすべきライブラリが変わりました。
7 Structured Streamingの登場 バッチ処理とインタラクティブ処理をDataFrameで同様に記述できるようになった。ただしα版であり、安定版や機能追加は次バージョン以降でリリース予定 8 SparkRの改善 R言語でSparkの処理を記述するSparkRでユーザ定義関数をサポートSpark 1.6 Spark 2.0import org.apache.spark.SparkConf宣言する変数 importするライブラリが変わったことで、宣言すべき変数とその初期化処理も変わりました。
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.sql.SparkSessionSpark 1.6 Spark 2.0val sparkConf = new SparkConf()
.setAppName(this.getClass.toString())
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
……
sc.stop()val spark = SparkSessionHiveテーブルからデータを読み込む処理 宣言する変数が変わったことで、Hiveテーブルへアクセスするメソッドを持つオブジェクトも変わりました。
.builder()
.appName(this.getClass.toString())
.enableHiveSupport()
.getOrCreate()
……
spark.stop()Spark 1.6 Spark 2.0import hiveContext.implicits._なお、SparkSessionのソースコード記述方法の詳細は、Spark SQL, DataFrames and Datasets Guideを参照してください。 また、そのほか詳細な変更点についてはApache Software Foundationが公開するSpark 2.0のリリースノート(Spark Release 2.0.0)を参照してください。本連載執筆時点での最新版は2016年10月30日にリリースされたSpark 2.0.1 です。 Spark SQLの概要 Spark SQLは、Sparkの処理をSQLで記述するためのコンポーネントです。SQLでの開発に慣れている開発者は直感的に処理を記述できます。また、Spark SQLはSQLで記述された処理の実行計画を最適化してから実行するため高速に動作します。 Spark SQLでは、表4に示す構造化データセットを扱うことができます。
val recordsFromHive = hiveContext.sql( HiveQL文 )
……import spark.implicits._
val recordsFromHive = spark.sql( HiveQL文 )
……表4:Spark SQLが標準でサポートする構造化データセット # ファイルフォーマット 説明 1 テキストファイル(CSV) CSV形式のテキストファイル 2 JSONファイル JSON(JavaScript Object Notation)形式のテキストファイル 3 Parquetファイル HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ 4 ORCFile Optimized Row Columnarの略。HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ 5 JDBCをサポートするデータソース Spark SQLはRDBMSなどの外部データソースにJDBCインタフェースを通してクエリを発行できる 6 Hiveテーブル Hiveで扱うデータを格納したテーブルまた、Spark SQLにおけるSQLの記述方法を表5に示します。表5:Spark SQLにおけるSQLの記述方法 # フォーマット 説明 1 DataFrame / Dataset API SQLライクなメソッドを提供するAPI 2 HiveQL Hiveで使用されるSQLライクなクエリ言語 3 SQL 2003 国際標準規格であるANSI SQL2003のこと本連載の検証シナリオ 本連載では、電力会社における配電事業を検証シナリオとします。具体的には、電力会社が保有する設備にかかる負荷をすばやく分析・可視化するために、消費者の電気使用量(以降、消費電力量)を表すデータを分析前に集計します。この集計処理にSparkを活用し、このようなシナリオでどの程度の性能を発揮できるかを検証します。 配電事業の概要と設備構成 配電事業では、変電所から各家庭などへ電気を送ります。このときに使用する設備一式を「配電系統」と呼びます。一般的に配電事業では効率や可用性を考慮して配電系統を構成しますが、本検証では簡単化のため配電系統は1つで変電所から分岐のない配電線が伸びているものと想定します(図1)。 配電系統はいくつかの設備からなり、それぞれ上位の設備があります。スマートメータ(メータ)の上位には変圧器、変圧器の上位には区間、区間の上位には配電線、配電線の上位には変電所があります。配電した電気量は各家庭に設置されたメータから消費電力量として30分おきに収集し、毎月の料金請求に利用します。消費電力量データを電力会社が活用する方法 収集した電力消費量データは、電力会社が設備投資計画に役立てるケースを想定します。1,000万台のメータから消費電力量データを30分おきに収集し、データ分析システムに取り込んで電力会社の担当者が設備にかかる負荷を分析します。その結果を設備投資計画へ活用するという活用方法です。 その分析手法は、可視化ツールやBIソフトウェアで配電系統の負荷をドリルダウン分析することを想定します。ドリルダウンはデータ集計や分析で用いる手法の1つで、広い範囲の集計結果から集計範囲を一段階ずつ掘り下げていき、より詳細な集計を行う操作のことです。 今回の検証では「どの設備に負荷が集中しているのか」を調べるために、系統全体の負荷⇒変電所の負荷⇒配電線の負荷⇒区間の負荷⇒変圧器の負荷⇒メータの負荷、という手順で分析するものとします。図2は、ある変圧器の配下にあるメータ(SM-0、SM-7、SM-8)にかかる配電時の負荷の推移を可視化した時系列チャートです。消費電力量データをデータ分析システム内部で処理する内容 ドリルダウン分析では何度も上位設備から下位設備への掘り下げが行われるため、その度に結果を可視化する必要があります。しかし扱うデータは1日あたり1,000万件と多いため、可視化時に集計も行うには時間がかかり、すばやく分析することが難しいと予想されます。そこで本検証では、データ分析システム内部で配電系統の設備ごとの負荷を分析・可視化する前にSparkによるバッチ処理で集計するものとします。これにより分析時に実行される演算処理量を低減します。 各設備の負荷は、その設備の下位設備の負荷(消費電力量)の合計値で計算します(図3)。例えば、変圧器の負荷はその変圧器に属するメータすべての負荷を合計すると求めることができます。図2の場合ではメータSM-0、SM-7、SM-8が出す値の合計値がある変圧器にかかる負荷になります。つまり、ある設備の負荷を求めるためにはメータから得た消費電力量データを設備ごとに順番に足し合わせて集約する必要があります。おわりに 今回は、主に次の2点について解説しました。- Spark SQLでは実行する処理をSQLで記述し、直感的にデータ処理を実装できます。Spark 1.6から2.0にメジャーアップデートされた主な変更点は「性能向上」と「処理の記述方法」です。処理の記述方法ではDataFrameを利用するために呼び出すエントリポイントがSparkSessionに統合されエントリポイントの使い分けを意識する必要がなくなり、アプリケーションの処理ロジック実装に集中できるようになりました。性能向上については次回以降の検証結果を元に解説していきます。
- 検証シナリオでは、メータから30分おきに収集した消費電力量データを分析し、設備にかかる負荷を可視化するケースを想定します。ただ1日に1,000万件のデータが発生する環境では分析・可視化時にデータの集計処理もしていては作業に時間がかかります。そこでデータ分析システム内部で設備ごとの負荷を予めSparkで集計しておきます。
- Spark 2.0の主な変更点
- Spark SQLの概要
Spark SQLは、Sparkの処理をSQLで記述するためのコンポーネントです。SQLでの開発に慣れている開発者は直感的に処理を記述できます。また、Spark SQLはSQLで記述された処理の実行計画を最適化してから実行するため高速に動作します。
Spark SQLでは、表4に示す構造化データセットを扱うことができます。表4:Spark SQLが標準でサポートする構造化データセット # ファイルフォーマット 説明 1 テキストファイル(CSV) CSV形式のテキストファイル 2 JSONファイル JSON(JavaScript Object Notation)形式のテキストファイル 3 Parquetファイル HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ 4 ORCFile Optimized Row Columnarの略。HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ 5 JDBCをサポートするデータソース Spark SQLはRDBMSなどの外部データソースにJDBCインタフェースを通してクエリを発行できる 6 Hiveテーブル Hiveで扱うデータを格納したテーブルまた、Spark SQLにおけるSQLの記述方法を表5に示します。表5:Spark SQLにおけるSQLの記述方法 # フォーマット 説明 1 DataFrame / Dataset API SQLライクなメソッドを提供するAPI 2 HiveQL Hiveで使用されるSQLライクなクエリ言語 3 SQL 2003 国際標準規格であるANSI SQL2003のこと本連載の検証シナリオ 本連載では、電力会社における配電事業を検証シナリオとします。具体的には、電力会社が保有する設備にかかる負荷をすばやく分析・可視化するために、消費者の電気使用量(以降、消費電力量)を表すデータを分析前に集計します。この集計処理にSparkを活用し、このようなシナリオでどの程度の性能を発揮できるかを検証します。 配電事業の概要と設備構成 配電事業では、変電所から各家庭などへ電気を送ります。このときに使用する設備一式を「配電系統」と呼びます。一般的に配電事業では効率や可用性を考慮して配電系統を構成しますが、本検証では簡単化のため配電系統は1つで変電所から分岐のない配電線が伸びているものと想定します(図1)。 配電系統はいくつかの設備からなり、それぞれ上位の設備があります。スマートメータ(メータ)の上位には変圧器、変圧器の上位には区間、区間の上位には配電線、配電線の上位には変電所があります。配電した電気量は各家庭に設置されたメータから消費電力量として30分おきに収集し、毎月の料金請求に利用します。消費電力量データを電力会社が活用する方法 収集した電力消費量データは、電力会社が設備投資計画に役立てるケースを想定します。1,000万台のメータから消費電力量データを30分おきに収集し、データ分析システムに取り込んで電力会社の担当者が設備にかかる負荷を分析します。その結果を設備投資計画へ活用するという活用方法です。 その分析手法は、可視化ツールやBIソフトウェアで配電系統の負荷をドリルダウン分析することを想定します。ドリルダウンはデータ集計や分析で用いる手法の1つで、広い範囲の集計結果から集計範囲を一段階ずつ掘り下げていき、より詳細な集計を行う操作のことです。 今回の検証では「どの設備に負荷が集中しているのか」を調べるために、系統全体の負荷⇒変電所の負荷⇒配電線の負荷⇒区間の負荷⇒変圧器の負荷⇒メータの負荷、という手順で分析するものとします。図2は、ある変圧器の配下にあるメータ(SM-0、SM-7、SM-8)にかかる配電時の負荷の推移を可視化した時系列チャートです。消費電力量データをデータ分析システム内部で処理する内容 ドリルダウン分析では何度も上位設備から下位設備への掘り下げが行われるため、その度に結果を可視化する必要があります。しかし扱うデータは1日あたり1,000万件と多いため、可視化時に集計も行うには時間がかかり、すばやく分析することが難しいと予想されます。そこで本検証では、データ分析システム内部で配電系統の設備ごとの負荷を分析・可視化する前にSparkによるバッチ処理で集計するものとします。これにより分析時に実行される演算処理量を低減します。 各設備の負荷は、その設備の下位設備の負荷(消費電力量)の合計値で計算します(図3)。例えば、変圧器の負荷はその変圧器に属するメータすべての負荷を合計すると求めることができます。図2の場合ではメータSM-0、SM-7、SM-8が出す値の合計値がある変圧器にかかる負荷になります。つまり、ある設備の負荷を求めるためにはメータから得た消費電力量データを設備ごとに順番に足し合わせて集約する必要があります。おわりに 今回は、主に次の2点について解説しました。
- Spark SQLでは実行する処理をSQLで記述し、直感的にデータ処理を実装できます。Spark 1.6から2.0にメジャーアップデートされた主な変更点は「性能向上」と「処理の記述方法」です。処理の記述方法ではDataFrameを利用するために呼び出すエントリポイントがSparkSessionに統合されエントリポイントの使い分けを意識する必要がなくなり、アプリケーションの処理ロジック実装に集中できるようになりました。性能向上については次回以降の検証結果を元に解説していきます。
- 検証シナリオでは、メータから30分おきに収集した消費電力量データを分析し、設備にかかる負荷を可視化するケースを想定します。ただ1日に1,000万件のデータが発生する環境では分析・可視化時にデータの集計処理もしていては作業に時間がかかります。そこでデータ分析システム内部で設備ごとの負荷を予めSparkで集計しておきます。
- 本連載の検証シナリオ
- おわりに
はじめに
ビッグデータの処理基盤として知られる「Apache Hadoop」(以降、Hadoop)のエコシステムを構成するOSSの1つ「Apache Spark」(以降、Spark)は、2016年7月にメジャーバージョン2.0がリリースされました。その大きな変更点はSQL処理APIの改善とパフォーマンス(処理性能)向上で、特に処理性能は「最大10倍に向上した」とリリースノートに記載されています。
そこで本連載では、最新版のSpark 2.0と1.x系の最新バージョンSpark 1.6.2(以降、Spark1.6)の性能を比較し、実際のシステムでどの程度活用できるのかを検証していきます。
おさらい:HadoopとSparkとは何か
本連載の検証で取り上げる「Spark SQL」は、Sparkを構成するコンポーネントの1つです。またSparkもHadoopのエコシステムを構成するOSSのひとつです。そこでSpark SQLを説明する前に「HadoopとSparkとは何か」を簡単に説明します。
Hadoopの概要
HadoopはIAサーバを複数台用いて大量のデータ(ビッグデータ)を並列分散処理する基盤です。「MapReduce」と呼ばれる処理で入力データを分割して並列分散処理(Map)し、その結果を集約(Reduce)して出力データを生成します。
現在主流のバージョン2.x系は表1に示す3種類のコンポーネントで構成されます。
表1:Hadoopを構成するコンポーネント一覧(2.x系)
| # | コンポーネント | 説明 |
|---|---|---|
| 1 | MapReduce2 | バッチ処理向け分散処理フレームワーク |
| 2 | YARN (Yet Another Resource Negotiator) | クラスタリソース管理 |
| 3 | HDFS (Hadoop Distributed File System) | 分散ファイルシステム |
Sparkの概要
Sparkはデータをインメモリで処理することでMapReduceの課題を解決するコンポーネントです。従来、Hadoop(MapReduce)には「HDFSを介したディスク書き込み/読み込みを繰り返すことから、全体でディスクI/Oにかかるコストが高くなる」という課題がありました。SparkもMapReduceと同様に入力データを分割して並列分散処理(Map)し、その結果を集約(Reduce)して出力データを生成しますが、その処理の大半をメモリ上で行うためMapReduceよりもディスクI/O回数が少なく高速に動作します。
Sparkは表2に示す並列分散処理のエンジンと、用途別のライブラリ群で構成されます。表2:Sparkを構成するコンポーネント一覧
| # | コンポーネント | 説明 |
|---|---|---|
| 1 | Spark Core | Sparkの分散処理フレームワーク。基本機能を提供する |
| 2 | Spark SQL | 構造データにSQLを利用するためのAPIを提供する |
| 3 | Spark Streaming | マイクロバッチ方式によるストリームデータ処理機能を提供する |
| 4 | GraphX | グラフ構造データを処理するためのAPIを提供する |
| 5 | MLlib | 機械学習アルゴリズムを使用するためのAPIを提供する |
HadoopとSparkの概要については、「ユースケースで徹底検証! Sparkのビッグデータ処理機能を試す」で詳細に解説していますので、そちらも併せてご覧ください。
Spark 2.0の主な変更点
Spark 2.0のリリースノートに記載されている主な変更点を表3に示します。
表3:Spark 2.0の主な変更点
| # | 変更点 | 説明 |
|---|---|---|
| 1 | 性能改善 | SQLの処理速度が2倍から10倍に向上 |
| 2 | Parquet/ORCファイルの読み書き性能を改善 | |
| 3 | Spark SQLの改善 | SQLを記述するDataFrame/Dataset APIを統合※ |
| 4 | SQL記述方法として国際基準ANSI SQL2003をサポート | |
| 5 | MLlib APIの改善 | MLlibの処理をDataFrameで記述できるようになった |
| 6 | DataFrameで記述できる機械学習アルゴリズムを追加 | |
| 7 | Structured Streamingの登場 | バッチ処理とインタラクティブ処理をDataFrameで同様に記述できるようになった。ただしα版であり、安定版や機能追加は次バージョン以降でリリース予定 |
| 8 | SparkRの改善 | R言語でSparkの処理を記述するSparkRでユーザ定義関数をサポート |
※:Spark 2.0でのDatasetとは型を持つテーブル形式のデータ集合のこと、DataFrameは型を持たないDatasetのこと。
「Spark 2.0を活用する」という視点で見ると、性能が改善していること、アプリケーションでのデータ処理(ソースコード)の記述方法が変わったことの2点が主な変更点といえます。このうち、本連載では性能改善の検証結果を解説します。
アプリケーションのソースコードを記述する上での大きな違いは、DataFrameを使うときに呼び出すAPI(エントリポイント)が変わったことです。Spark 1.6ではSQLContextおよびHiveContextでしたが、Spark 2.0ではSparkSessionが用意されました。DataFrameは概念的にはリレーショナルデータベース(RDB)のテーブルと等価とされています。そのためDataFrameだけでなくcsvやjsonのような構造化されたファイル、Hiveテーブル、RDBテーブルもSparkSessionをエントリポイントとして利用でき、エントリポイントの使い分けを意識する必要がなくなったことで処理ロジックの実装に集中できます。
本連載で検証のために作成したアプリケーションからソースコードでの違いを一部抜粋して示します。アプリケーションはScala言語で実装し、Hiveテーブルからデータを読み込んでSparkで値を足し合わせる処理をします。
importするライブラリ
DataFrame APIエントリポイントが統合されたことで、importすべきライブラリが変わりました。
| Spark 1.6 | Spark 2.0 |
|---|---|
| import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext import org.apache.spark.sql.hive.HiveContext | import org.apache.spark.sql.SparkSession |
宣言する変数
importするライブラリが変わったことで、宣言すべき変数とその初期化処理も変わりました。
| Spark 1.6 | Spark 2.0 |
|---|---|
| val sparkConf = new SparkConf() .setAppName(this.getClass.toString()) val sc = new SparkContext(sparkConf) val hiveContext = new HiveContext(sc) …… sc.stop() | val spark = SparkSession .builder() .appName(this.getClass.toString()) .enableHiveSupport() .getOrCreate() …… spark.stop() |
Hiveテーブルからデータを読み込む処理
宣言する変数が変わったことで、Hiveテーブルへアクセスするメソッドを持つオブジェクトも変わりました。
| Spark 1.6 | Spark 2.0 |
|---|---|
| import hiveContext.implicits._ val recordsFromHive = hiveContext.sql( HiveQL文 ) …… | import spark.implicits._ val recordsFromHive = spark.sql( HiveQL文 ) …… |
なお、SparkSessionのソースコード記述方法の詳細は、Spark SQL, DataFrames and Datasets Guideを参照してください。
また、そのほか詳細な変更点についてはApache Software Foundationが公開するSpark 2.0のリリースノート(Spark Release 2.0.0)を参照してください。本連載執筆時点での最新版は2016年10月30日にリリースされたSpark 2.0.1 です。
Spark SQLの概要
Spark SQLは、Sparkの処理をSQLで記述するためのコンポーネントです。SQLでの開発に慣れている開発者は直感的に処理を記述できます。また、Spark SQLはSQLで記述された処理の実行計画を最適化してから実行するため高速に動作します。
Spark SQLでは、表4に示す構造化データセットを扱うことができます。
表4:Spark SQLが標準でサポートする構造化データセット
| # | ファイルフォーマット | 説明 |
|---|---|---|
| 1 | テキストファイル(CSV) | CSV形式のテキストファイル |
| 2 | JSONファイル | JSON(JavaScript Object Notation)形式のテキストファイル |
| 3 | Parquetファイル | HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ |
| 4 | ORCFile | Optimized Row Columnarの略。HDFS上で利用できる圧縮された列指向ファイルフォーマットの1つ |
| 5 | JDBCをサポートするデータソース | Spark SQLはRDBMSなどの外部データソースにJDBCインタフェースを通してクエリを発行できる |
| 6 | Hiveテーブル | Hiveで扱うデータを格納したテーブル |
また、Spark SQLにおけるSQLの記述方法を表5に示します。
表5:Spark SQLにおけるSQLの記述方法
| # | フォーマット | 説明 |
|---|---|---|
| 1 | DataFrame / Dataset API | SQLライクなメソッドを提供するAPI |
| 2 | HiveQL | Hiveで使用されるSQLライクなクエリ言語 |
| 3 | SQL 2003 | 国際標準規格であるANSI SQL2003のこと |
本連載の検証シナリオ
本連載では、電力会社における配電事業を検証シナリオとします。具体的には、電力会社が保有する設備にかかる負荷をすばやく分析・可視化するために、消費者の電気使用量(以降、消費電力量)を表すデータを分析前に集計します。この集計処理にSparkを活用し、このようなシナリオでどの程度の性能を発揮できるかを検証します。
配電事業の概要と設備構成
配電事業では、変電所から各家庭などへ電気を送ります。このときに使用する設備一式を「配電系統」と呼びます。一般的に配電事業では効率や可用性を考慮して配電系統を構成しますが、本検証では簡単化のため配電系統は1つで変電所から分岐のない配電線が伸びているものと想定します(図1)。
配電系統はいくつかの設備からなり、それぞれ上位の設備があります。スマートメータ(メータ)の上位には変圧器、変圧器の上位には区間、区間の上位には配電線、配電線の上位には変電所があります。配電した電気量は各家庭に設置されたメータから消費電力量として30分おきに収集し、毎月の料金請求に利用します。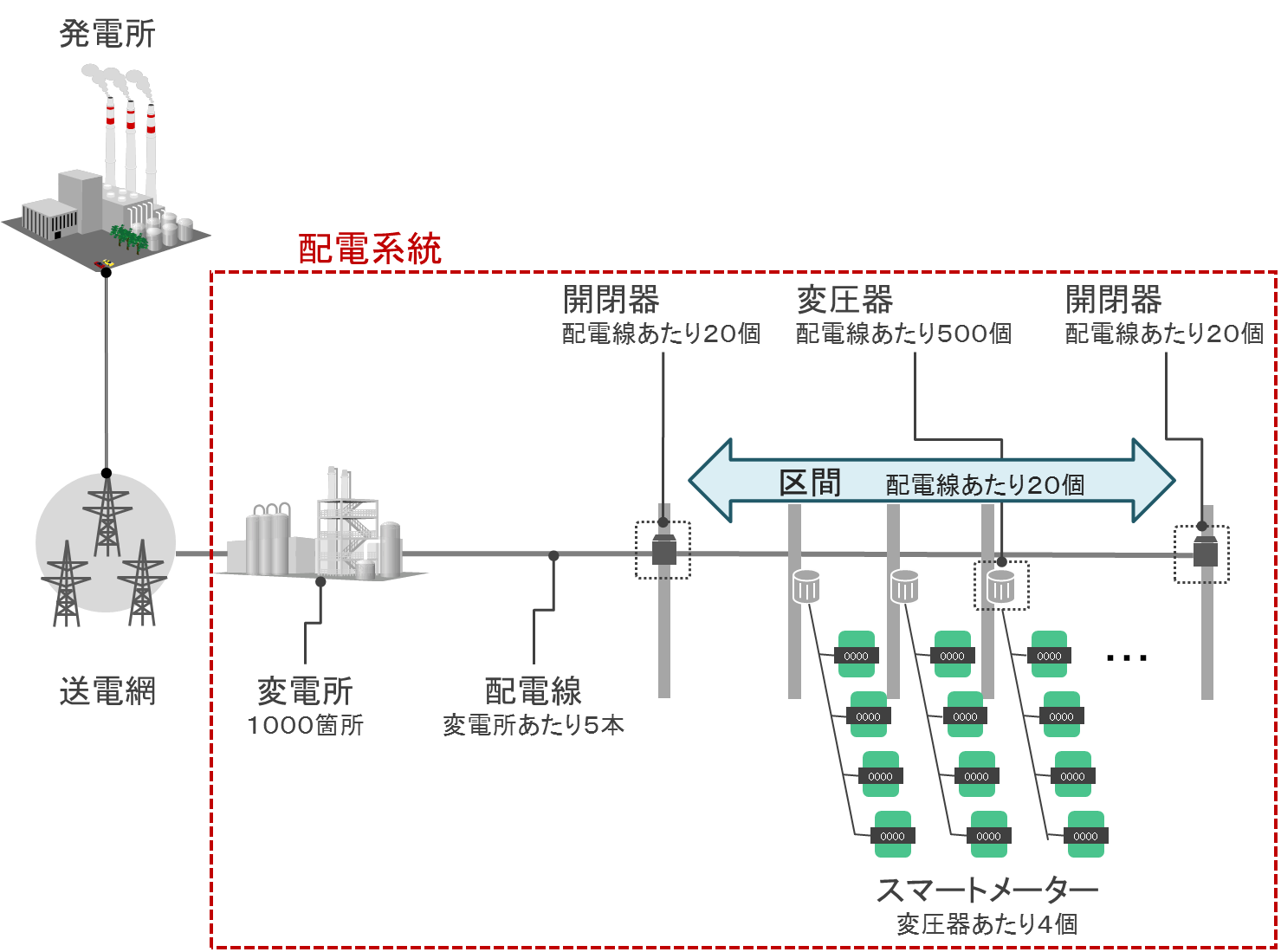
図1:配電事業における配電系統の構成
消費電力量データを電力会社が活用する方法
収集した電力消費量データは、電力会社が設備投資計画に役立てるケースを想定します。1,000万台のメータから消費電力量データを30分おきに収集し、データ分析システムに取り込んで電力会社の担当者が設備にかかる負荷を分析します。その結果を設備投資計画へ活用するという活用方法です。
その分析手法は、可視化ツールやBIソフトウェアで配電系統の負荷をドリルダウン分析することを想定します。ドリルダウンはデータ集計や分析で用いる手法の1つで、広い範囲の集計結果から集計範囲を一段階ずつ掘り下げていき、より詳細な集計を行う操作のことです。
今回の検証では「どの設備に負荷が集中しているのか」を調べるために、系統全体の負荷⇒変電所の負荷⇒配電線の負荷⇒区間の負荷⇒変圧器の負荷⇒メータの負荷、という手順で分析するものとします。図2は、ある変圧器の配下にあるメータ(SM-0、SM-7、SM-8)にかかる配電時の負荷の推移を可視化した時系列チャートです。
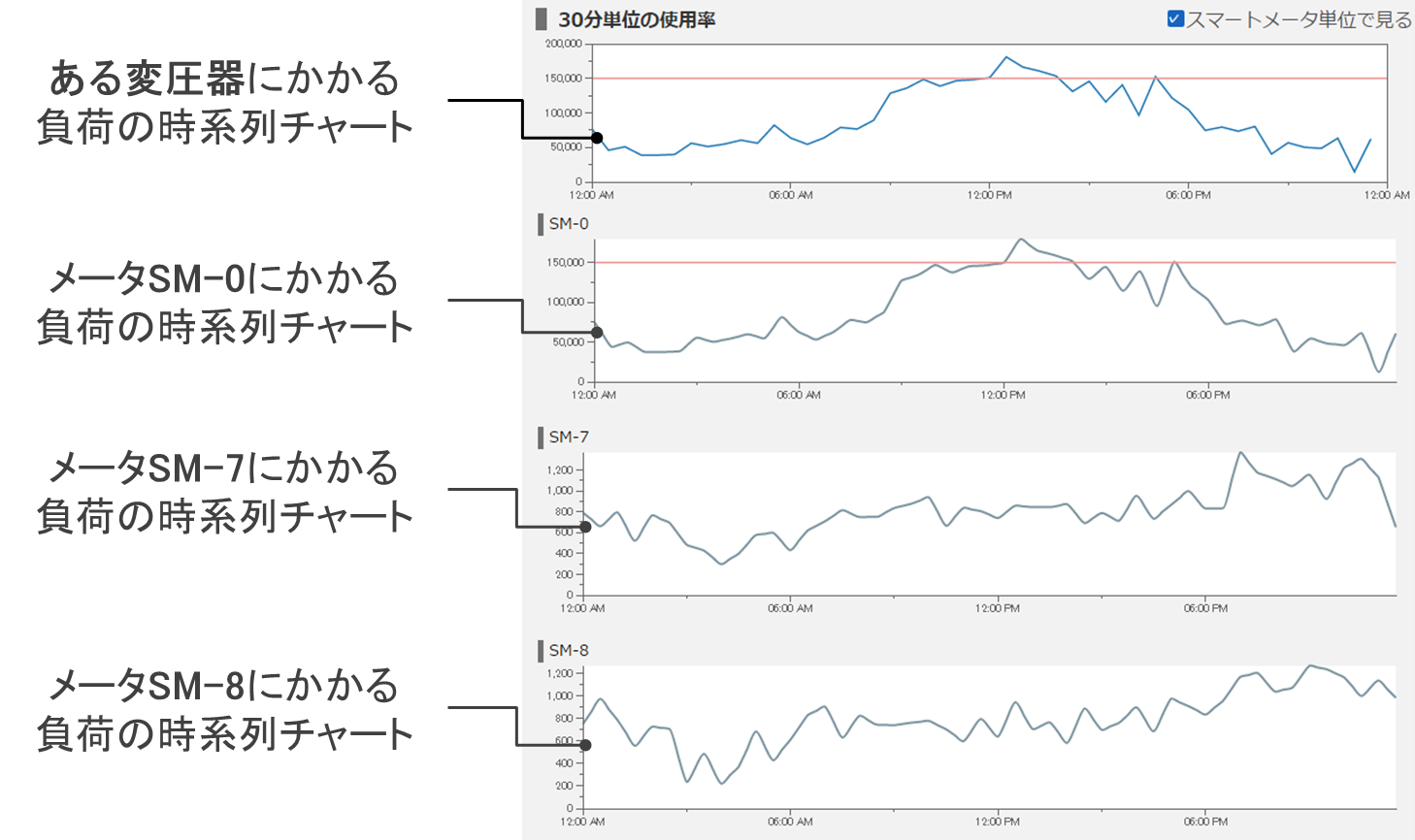
図2:負荷を時系列に可視化したイメージ
消費電力量データをデータ分析システム内部で処理する内容
ドリルダウン分析では何度も上位設備から下位設備への掘り下げが行われるため、その度に結果を可視化する必要があります。しかし扱うデータは1日あたり1,000万件と多いため、可視化時に集計も行うには時間がかかり、すばやく分析することが難しいと予想されます。そこで本検証では、データ分析システム内部で配電系統の設備ごとの負荷を分析・可視化する前にSparkによるバッチ処理で集計するものとします。これにより分析時に実行される演算処理量を低減します。
各設備の負荷は、その設備の下位設備の負荷(消費電力量)の合計値で計算します(図3)。例えば、変圧器の負荷はその変圧器に属するメータすべての負荷を合計すると求めることができます。図2の場合ではメータSM-0、SM-7、SM-8が出す値の合計値がある変圧器にかかる負荷になります。つまり、ある設備の負荷を求めるためにはメータから得た消費電力量データを設備ごとに順番に足し合わせて集約する必要があります。
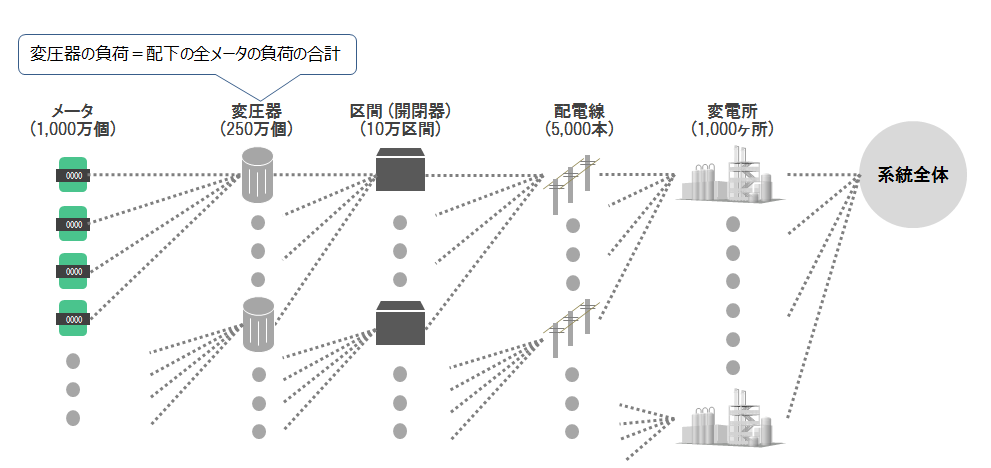
図3:負荷を求めるための考え方
おわりに
今回は、主に次の2点について解説しました。
- Spark SQLでは実行する処理をSQLで記述し、直感的にデータ処理を実装できます。Spark 1.6から2.0にメジャーアップデートされた主な変更点は「性能向上」と「処理の記述方法」です。処理の記述方法ではDataFrameを利用するために呼び出すエントリポイントがSparkSessionに統合されエントリポイントの使い分けを意識する必要がなくなり、アプリケーションの処理ロジック実装に集中できるようになりました。性能向上については次回以降の検証結果を元に解説していきます。
- 検証シナリオでは、メータから30分おきに収集した消費電力量データを分析し、設備にかかる負荷を可視化するケースを想定します。ただ1日に1,000万件のデータが発生する環境では分析・可視化時にデータの集計処理もしていては作業に時間がかかります。そこでデータ分析システム内部で設備ごとの負荷を予めSparkで集計しておきます。
次回は、検証で使用するシステム構成とパラメータの初期設定、検証シナリオに基づいて実施したSparkの性能検証の結果を紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
