はじめに
第3回ではセンサデータ処理システムを構成するKafka、Spark Streaming、Elasticsearchのチューニング方法と、チューニング後の性能測定結果について解説しました。最終回の今回は各OSSに割り当てるマシン台数を調整し、「何がシステムのボトルネックとなるのか」を示します。また、本連載の検証を通じて得られたノウハウを紹介します。
マシン台数の調整
第2回では、センサデータを配信するKafka Producerノードが1台、センサデータをキューイングするKafka Brokerノードが2台、センサデータを処理・保存するSparkワーカノード(Elasticsearchも同居)を5台に固定して測定しました。なお、センサデータは1メッセージ9,028byte、ノード間を接続するネットワークは1Gbpsの回線を使用しました。
また、第3回ではシステムを構成するKafka、Spark Streaming、Elasticsearchのパラメータをチューニングしました。その結果、Kafkaの格納性能は秒間8,026メッセージ(約69MB)から10,112メッセージ(約87MB)に、Sparkの処理性能は秒間19,346メッセージ(約167MB)から20,746メッセージ(約179MB)に向上しました(図1)。これにより、第2回で設定したシステム全体の目標性能である10,000メッセージ/秒を達成できることが分かりました。
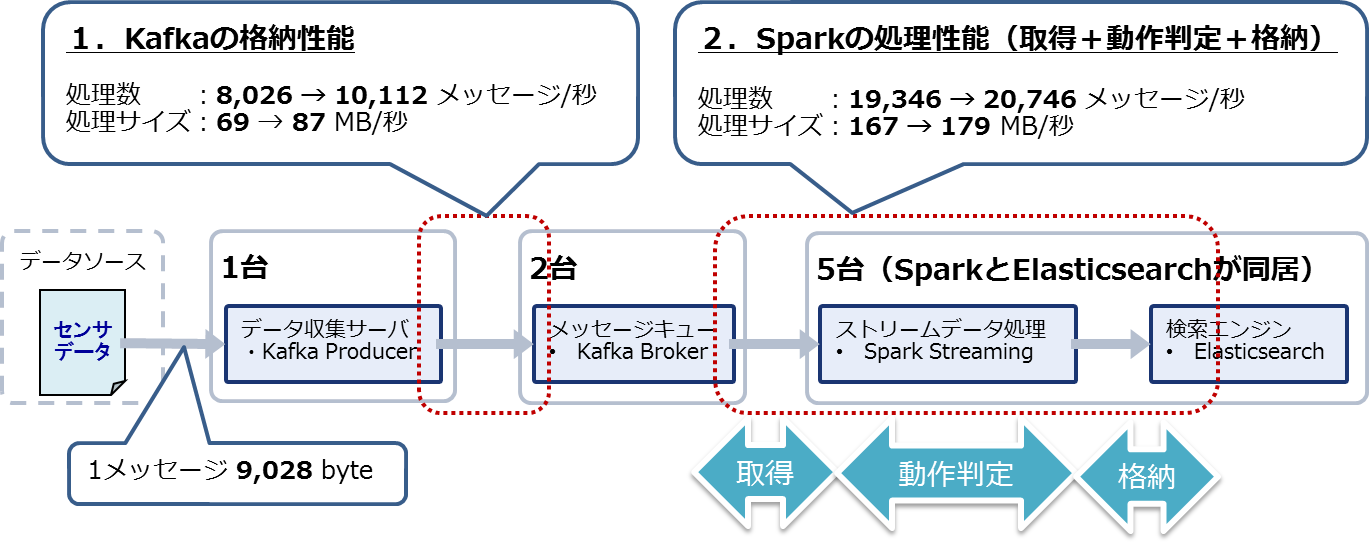
図1:パラメータチューニング前後の測定結果
しかし、依然としてSparkの処理性能はKafkaの格納性能を2倍以上も上回っています。ストリームデータ処理システムでは処理性能の最も低い箇所がボトルネックとしてシステム全体の処理性能が決まるため、処理性能に偏りがあればマシンリソースを効率的に利用できません。
そこで今回は、システム全体の処理性能を最大化するため、各OSSに割り当てるノード台数を調整してみます。
Sparkワーカノード台数の調整
現状、Sparkの処理性能はKafkaの格納性能を2倍以上も上回っているため、Sparkワーカノードの台数を減らしても問題ないと考えられます。Sparkワーカノードの台数を減らした場合の測定結果を図2に示します。
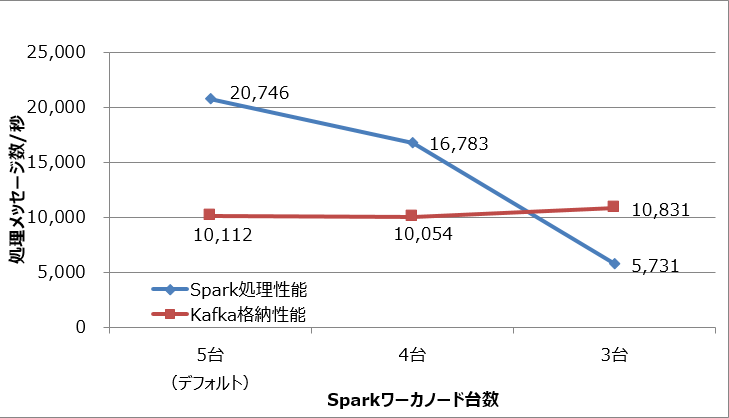
図2:Sparkワーカノードの台数と処理メッセージ数
この結果から、Sparkワーカノードを4台にしてもKafkaの格納性能を上回り、目標性能の10,000メッセージ/秒を達成できることが分かりました。一方、Sparkワーカノードを3台にするとSparkの処理性能は大きく下がり、Kafkaの格納性能は若干向上しました(理由は後の考察を参照)。
Kafka Producerノード台数の調整
今度はKafka側の格納性能を向上させるため、Kafka Producerノードの台数を増やして測定しました。なおSparkワーカノードは5台、Kafka Brokerノードは2台のままです。測定結果を図3に示します。
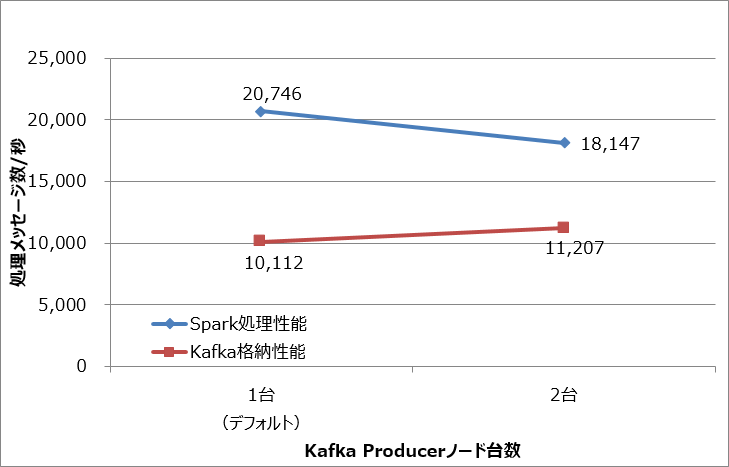
図3:Kafka Producerのノード台数と処理メッセージ数
この結果、Kafka Producerノードを2台に増やすとKafkaの格納性能は約11%向上しました。しかし台数を2倍にしたことを考えると性能の向上幅は小さいといえます。またSparkの処理性能はKafkaとは反対に13%低下しました。
Kafka Brokerノード台数の調整
今度は、Kafka側の格納性能を向上させるためKafka ProducerとKafka Brokerのノードを同時に増やして測定しました。Sparkワーカノードは5台のままです。測定結果を図4に示します。
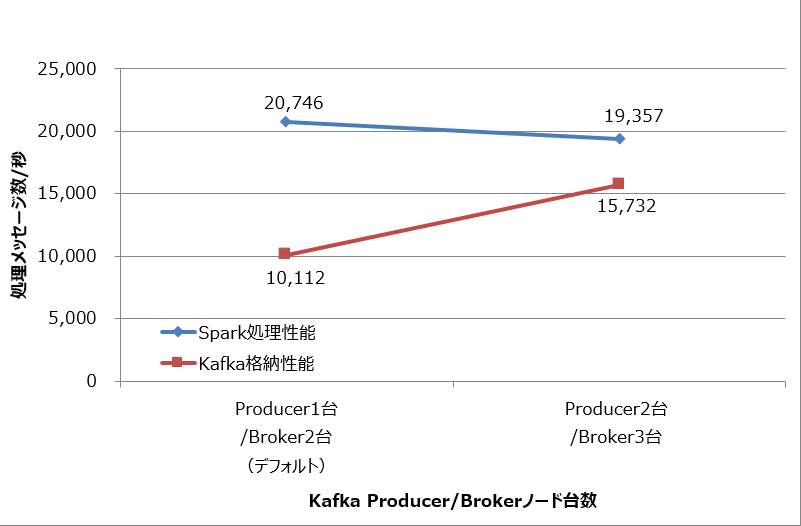
図4:Kafka Producer/Brokerのノード台数と処理メッセージ数
この結果から、Kafka Producerノードを2台に、Kafka Brokerノードを3台に増やしたとき、Kafkaの格納性能はデフォルト時から56%向上しました。なおSparkの性能は7%低下しています。
マシン台数の調整結果
以上の結果から、Kafkaの格納性能はKafka ProducerとKafka Brokerのノード台数に比例し、Sparkの処理性能はSparkワーカノードの台数に比例することが分かりました。また、Kafkaの格納性能が向上するとSparkの処理性能は低下し、Sparkの処理性能が向上するとKafkaの格納性能が低下するという傾向があることも分かりました。
考察:システムのボトルネック
前述したように、マシン台数を調整するとKafkaとSparkの処理性能は反比例する傾向があると分かりました。これは、今回のシステム環境ではKafka Broker側のネットワーク帯域がボトルネックになっているためと考えられます。
最初の構成(Kafka Producer1台、Kafka Broker2台、Spark Worker5台)における最大ネットワーク通信量の理論値(単位はMB/秒で小数点第2位以下は四捨五入)を図5に示します。
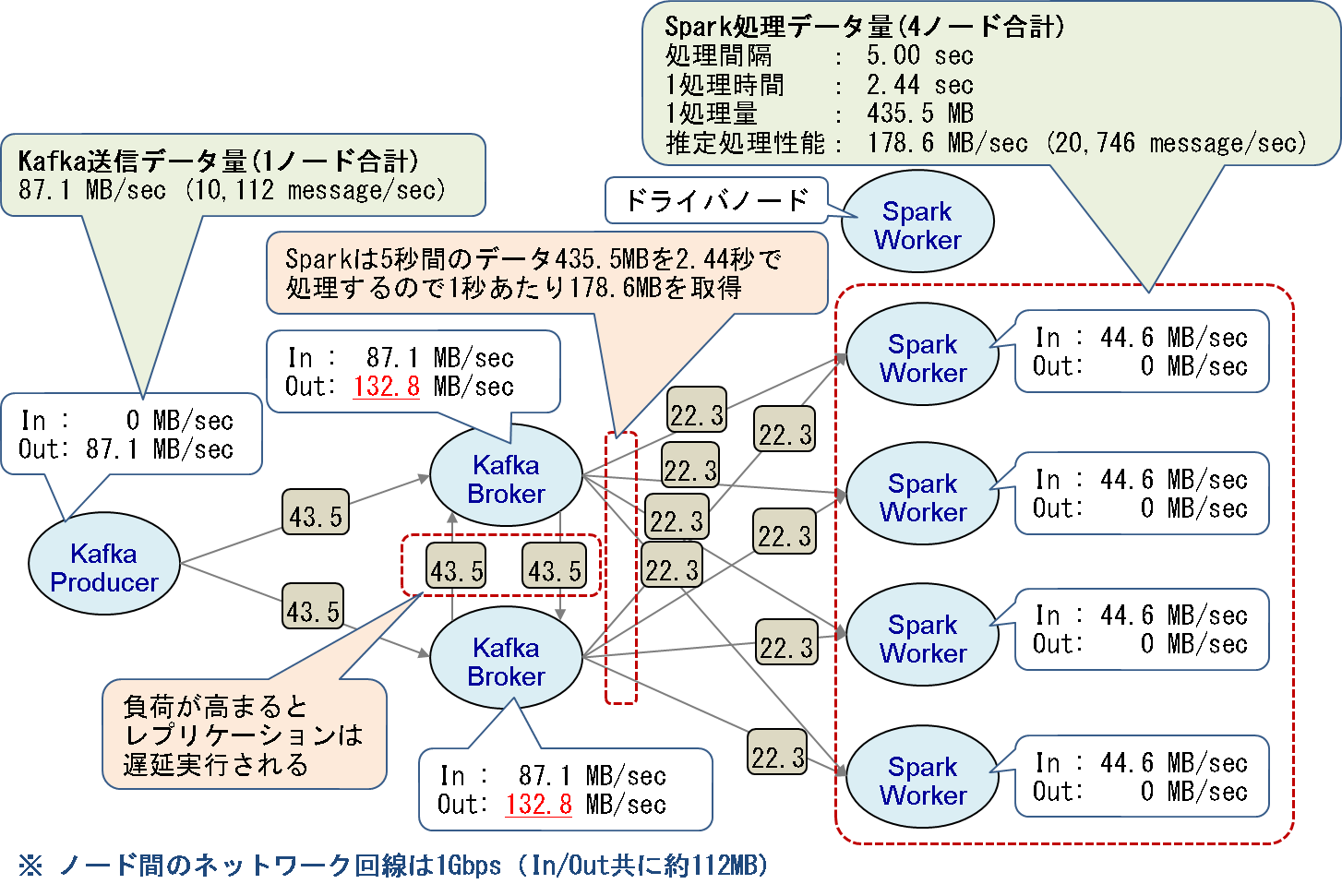
図5:初期構成における最大ネットワーク通信量の理論値
Producerノードの送信データ量は87.1MB/秒(1メッセージ9,028byte×10,112メッセージ/秒)であるため、各Brokerノードは約43.5MB/秒のデータを受信します。Brokerノードは受信したデータを他のBrokerノードにレプリケーションするため、各Brokerノードは約43.5MB/秒のデータを送信および受信します。またSparkの推定処理性能は178.6MB/秒(20,746メッセージ/秒)であるため、Brokerノード1台あたり最大約89.3MB/秒のデータをSparkワーカノード4台に送信します。
以上の計算から、Brokerノード1台あたりの受信/送信データ量の最大値は以下のようになります。
受信データ量=Producerからの受信量+他のBrokerからのレプリケーション量
=43.5MB/秒+43.5MB/秒
=87.1MB/秒
送信データ量=Sparkへの送信量+他のBrokerへのレプリケーション量
=89.3MB/秒+43.5MB/秒
=132.8MB/秒
しかし、第2回でも説明した通り、測定環境のネットワーク帯域は1Gbps(理論値125MB/秒、実質速度は112MB/秒程度)であり、Brokerの送信データ量の最大値(132.8MB/秒)がネットワーク帯域の実質速度(112MB/秒)を超えることになります。そこで各ノード間の通信量を調査した結果、Broker間の通信量が図5の理論値より減っており、レプリケーションが遅延実行されていることが分かりました。
その理由は、送信データ量がネットワーク帯域の上限に達したためと考えられます。またBrokerの送信帯域は上限に達していますが、Sparkの受信帯域には余裕があるため、KafkaからSparkへの送信もBrokerの帯域の影響で抑制されていると考えられます。
次に、Producerノードを2台にした時の最大ネットワーク通信量の理論値を図6に、Producerノードを2台、Brokerノードを3台にした時の理論値を図7に示します。
Producerノードが2台の場合(図6)はBrokerノードの送信量の理論値(126.3MB/秒)が測定環境のネットワーク帯域(112MB/秒)を超えているため、Producerノードが増えてKafkaの格納性能が11%向上した分、Sparkの処理性能が13%低下したと考えられます。
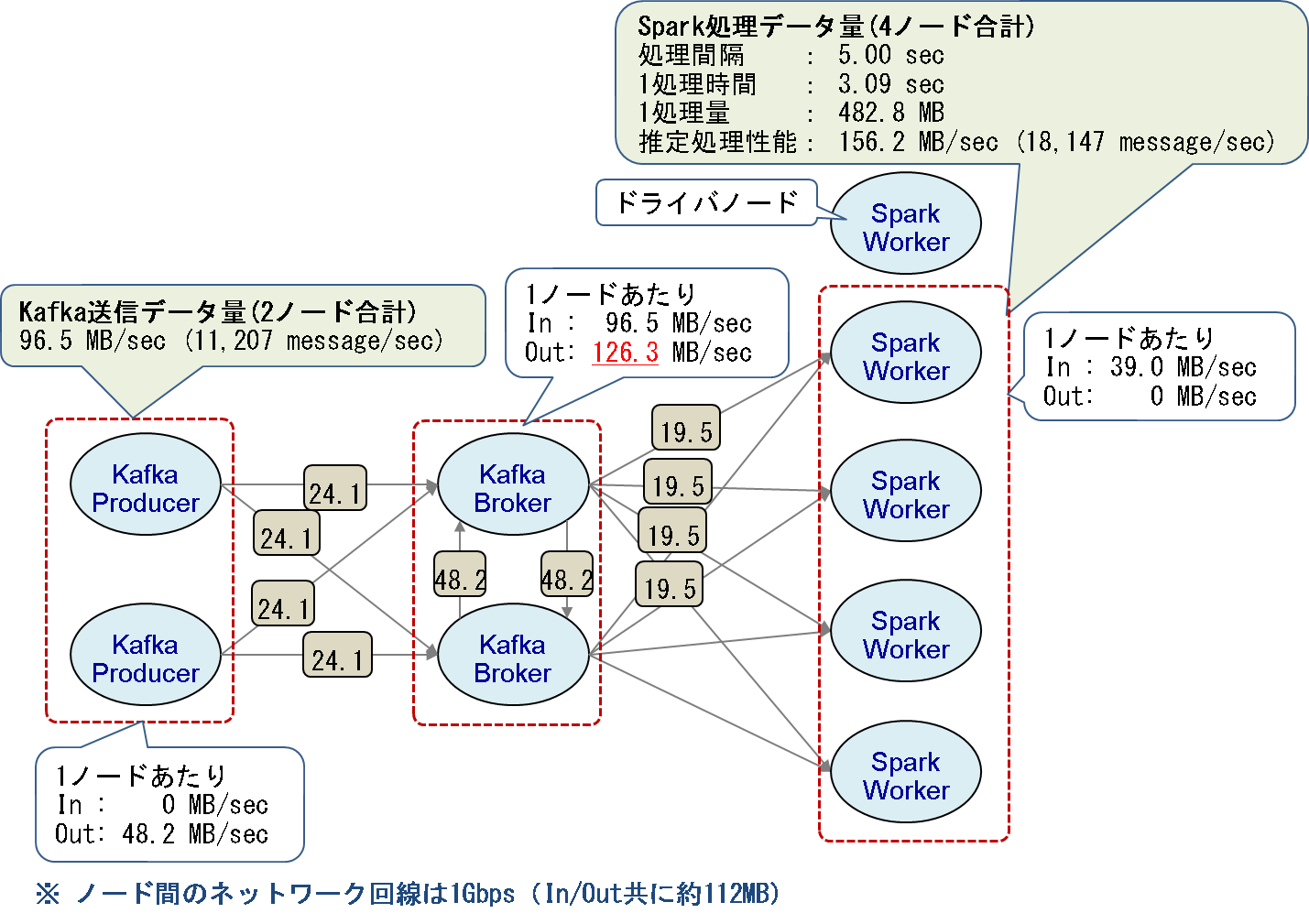
図6:Producerノード2台時の最大ネットワーク通信量の理論値
一方、Producerノード2台、Brokerノード3台の場合(図7)は全ノードの通信量がネットワーク帯域に収まっているため、Kafkaの格納性能は56%と大きく向上し、Sparkの処理性能の低下はわずか7%でした。
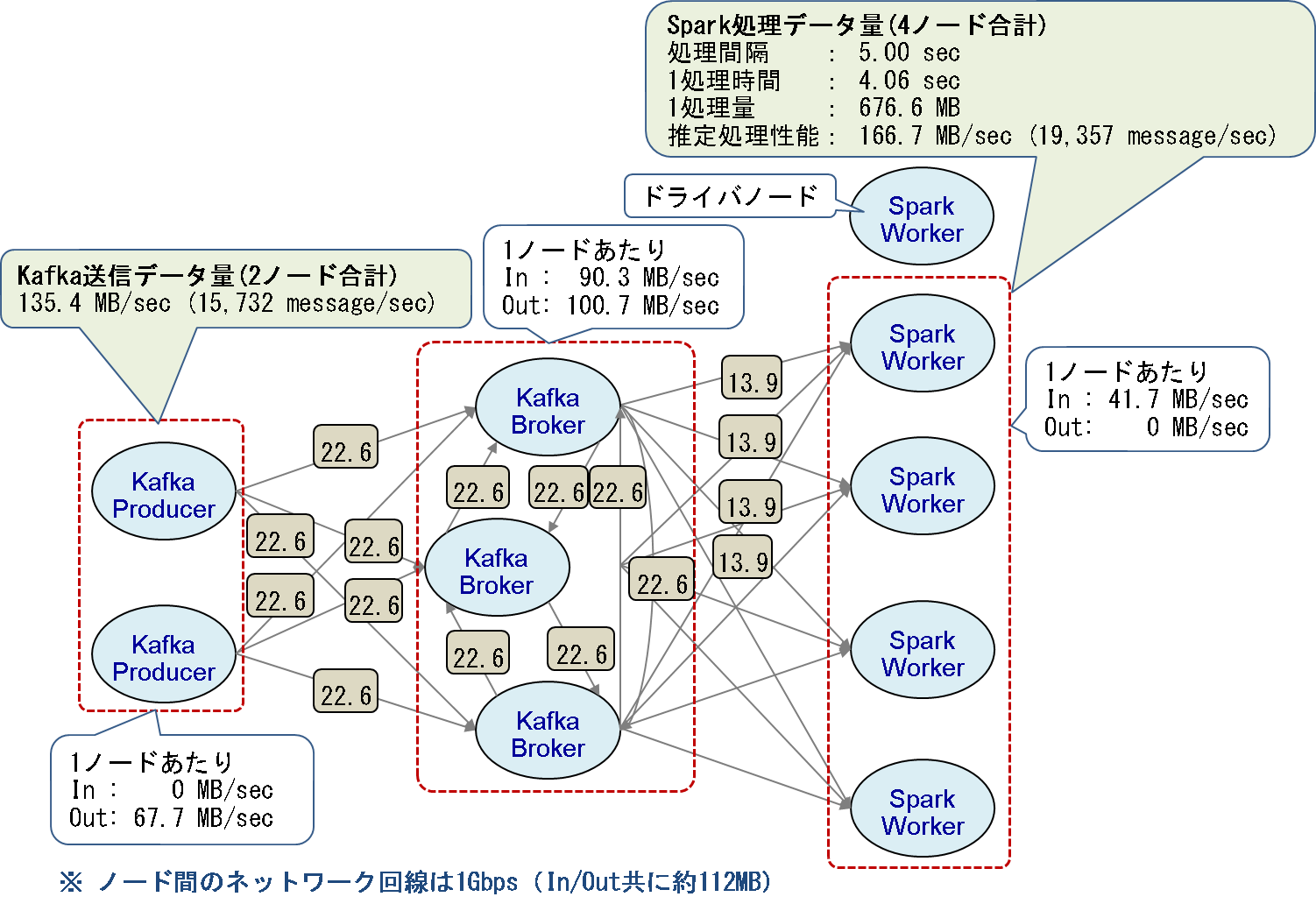
図7:Producerノード2台、Brokerノード3台時の最大ネットワーク通信量の理論値
以上の結果から、Brokerノードのネットワーク帯域がボトルネックとなる場合は、Kafkaの格納性能とSparkの処理性能がトレードオフとなります。そのためProducerノードとSparkワーカノードの台数を増やしてもそれぞれの台数比で性能が変化するだけで、全体としてはあまり性能が向上しないと言えます。
一方、Brokerノードの台数を増やして通信データ量を分散させ、ネットワーク帯域に余裕ができた場合は、Kafkaの格納性能とSparkの処理性能はトータルで大きく向上しました。
ボトルネックへの対処案
上記の考察で説明したKafka Brokerノードのネットワーク帯域におけるボトルネックへの対処案を表1に示します。
表1:ボトルネックへの対処案
| # | 対策の種別 | 対策内容 | 説明・注意事項 |
|---|---|---|---|
| 1 | ネットワーク回線の強化 | 高速なネットワーク回線 (10Gbpsなど)を使用する | スイッチ、ケーブル、NICなどのネットワーク機器をより高速なものに交換する追加投資が必要となる。また既存のネットワーク構成によっては、ネットワーク機器の交換時に同一ネットワーク上にある他のシステムを停止する必要がある |
| 2 | データ通信量の分散 | Kafka Brokerノードの台数を増やすことで、通信データ量を分散させる | マシンを追加するための追加投資が必要となり、運用管理コストも上がる。またネットワーク回線の強化と比べて帯域の上昇幅は少なく、マシン台数が増え過ぎるとスイッチの増設なども必要となる。以上の理由から、まずはネットワーク回線の強化を優先すべき |
| 3 | 通信データ量の削減 | 通信データを圧縮する | Kafkaの設定でデータ圧縮が可能だが圧縮・解凍にはCPUコストがかかる。今回の検証では圧縮機能を利用しなかったため効果は不明 |
| 4 | Kafka Brokerのレプリケーションを無効にする | レプリケーションを無効にすると通信データ量を削減できるが、システム障害時にデータを失うリスクが高まる |
推奨構成
今回の検証について、結果(事実)および考察内容(推測含む)から考える推奨構成を以下に示します。これは目標性能の10,000メッセージ/秒を達成するための最小システム構成です。
システム構成
図2で示した通り、Sparkワーカノード4台のときが10,000メッセージ/秒を達成できる最小構成です。この目標性能を満たす最小構成を表2に示します。
表2:目標性能を満たす最小マシン構成
| # | ノード | 台数 | CPUコア | メモリ |
|---|---|---|---|---|
| 1 | Kafka Producerノード | 1 | 2 (4vCore) | 8GB |
| 2 | Kafka Brokerノード | 2 | 2 (4vCore) | 8GB |
| 3 | Sparkワーカノード(Elasticsearchも同居) | 4 | 4 (8vCore) | 16GB |
| 4 | Sparkマスタノード | 1 | 2 (4vCore) | 8GB |
| 5 | Sparkクライアントノード | 1 | 2 (4vCore) | 8GB |
パラメータ設定
各OSS(Kafka、Spark Streaming、Elasticsearch)のパラメータチューニングについては第3回を参照してください。第3回の検証時からSparkワーカノードが1台減ったため、Sparkのエグゼキュータ数とElasticsearchのインデクスのシャード数はノード台数に合わせて設定する必要があります。
期待できる性能
図2で示した通り、Sparkワーカノード4台のときKafkaの格納性能が10,054メッセージ/秒、Sparkの処理性能が16,783メッセージ/秒であるため、Kafkaがボトルネックとなり10,054メッセージ/秒がシステム全体の最大処理性能です。処理性能をさらに高めたい場合は表1で示した対処案によりネットワーク帯域のボトルネックを解消する必要があります。
表3:検証を通じて得られたノウハウ
最後に、本連載の検証を通じて得られたノウハウを表3に示します。
表3:本連載の検証を通じて得られたノウハウ
| 分類 | ノウハウ |
|---|---|
| システム構築 | コミュニティ版のOSSを活用したため、Sparkクラスタ構築時の設定やOSS間の連携時のバージョンの不一致などに苦労した。ベンダが提供するディストリビュージョン(例えばCloudera CDHやHortonworks HDP/HDFなど)ならOSSの組み合わせも検証済みであり、Sparkクラスタの設定管理ツールも含まれているため、各OSSとOSS間の連携ライブラリを個別に揃えるよりも環境構築は容易 |
| KafkaとSparkの接続 | SparkがKafkaからデータを取得する方法は2種類ある(第2回を参照)。Spark 1.3から導入されたレシーバタスクを使用しない方式に優位点が多いが、Sparkのタスク数がKafkaのパーティション数に縛られるため注意が必要。Sparkクラスタのコアを使い切るためにはKafkaのキューのパーティション数をSparkクラスタのコア数と同数以上に設定する必要がある |
| Kafkaの検証 | KafkaはBroker間でデータをレプリケーションするためネットワーク帯域がボトルネックになりやすい。対策にはネットワーク回線を1Gbpsから10Gbpsにする、Brokerノード台数を増やして通信データ量を分散させる、通信データを圧縮するなどがある |
| Kafkaはネットワーク帯域に負荷がかかるとレプリケーションが遅延するため、一時的な高負荷には耐えられるが負荷が続くとレプリケーションの遅延が拡大していくため注意が必要 | |
| Kafkaはメッセージをディスクに格納するためディスク性能が重要となる。今回の検証ではディスク性能が高いため問題にならなかったが、普通のHDDを使用する場合はディスク性能がボトルネックとなる可能性があるため、システム構築時には必要なディスク性能を単位時間あたりに格納/取得するメッセージ量から事前に見積もる必要がある | |
| Sparkの検証 | SparkのJobが複数に分かれると同じデータをKafkaから何度も取得してしまう。これはRDDの途中結果をキャッシュすることで回避できる |
おわりに
今回は各OSSに割り当てるマシン台数を調整して性能検証を行いました。その結果、今回のシステム構成ではKafkaのネットワーク帯域がボトルネックになり易いことが判明したため、システム構築時には必要なネットワーク帯域を事前に見積もり、注意して設計する必要があります。
さて、本連載も今回で最終回となります。本連載がSparkを中心としたOSSシステムを構築する際の参考になれば幸いです。
最後に、私は6月にアメリカのサンフランシスコで開催された「Spark Summit 2016」に参加してきました。イベント最大の目玉は、メジャーバージョンのSpark 2.0(7月にリリース済み)に関する発表でした。Spark 2.0では処理性能が大幅に強化されたほか、本連載でも検証したSpark Streamingの処理をより簡潔に記述できる「Structured Streaming API」なども発表されました。私も現在、Spark 2.0の評価を開始しています。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
