ルール記述のお約束とBRMSの発展形(Business Resource Planner)
2017年2月23日 0:00
こんにちは。SCSKの植木とレッドハットの梅野によるBRMSのコラム、最終回となる第3回です。今回はSCSKでミドルウェアを担当している田中も加わりまして、BRMSを応用した新たなソリューションについてもご紹介します。よろしくお願いします。
ルール記述でのお約束
今回は、ルールを書く上で絶対にやってはいけない3つのタブーについて書いてみます。従来の手続き型のルールを書いている方々からすると違和感があると思いますが、これさえ守ればルールは劇的に分かりやすくなります。
thenの中にif-thenを書くな
ルールエンジンは、whenの部分とthenの部分で扱いが異なります。RETEアルゴリズムをベースとしているルールエンジンでは、whenの部分は「評価」の部分であり、thenは「実行」の部分になります。これらは「異なるタイミング」で実行されます。データがルールエンジンに渡された、つまり”insert()”が呼ばれた、もしくは”update()”や”retract()”が呼ばれた時に、whenの部分を実行します。
実は、内部的にはRete Treeと呼ばれる判断の木構造を作っています。違うルール名でも同じルールがあるような場合、ノードがシェアされて、効率よく判断が行えるようになっています。thenの部分は、データとルールのマッチングが行われた時(つまり、whenの部分が実行され、データとルールの組合せをAgendaに並べ終えた時)に、ルールの優先順位に基づいて「実行」されていきます。
これは、パターンマッチングが効率的に行われるようにした結果、そのようなアルゴリズムになっています。thenの中にifがあったとしても、それはRete Treeの中では判断として形成されず、実行中に1つのJavaの機能として実行されてしまいます。Reteアルゴリズムを使っていないことになります。
thenの中にifを書きたくなった時、それは何なのか、よく考えてみましょう。その処理はwhenの中に書けないでしょうか? 条件は全てwhenの中で書くようにすることで、条件に対して一通りの実行になるので、「そのルールで何が決定されるか」が明確になります。条件を書き、それに対する1つのアクションを定義することで、それは勝手に「宣言型」の書き方になっていきます。宣言型になると、お互いのルール間の相互関係性が排除できます。これが変化に強くなる1つの理由です。
また、似たような条件ができるのであれば、それは意思決定表として表現できないか考えてみましょう(意思決定表については第1回記事をご参照ください)。
とにかく、thenの中にはifを書かない。これが重要です。
elseは書くな
elseはwhenでマッチングしなかった場合の反対条件になります。大概の場合、elseの中身は「それ以外だったらこの値にする」というような書き方ではないでしょうか。
ルールの世界では、「条件にマッチしたらある値にする」(これを例外ルールとします)しかありません。elseに相当するのは、初期値、もしくは標準値というものではないでしょうか。だとしたら、
「パラメータxxxの値がnullであれば、110と設定する」
というようなルール(これを標準ルールとします)を書き、上記で書いた「例外ルール」に当てはまらなかったものは、標準ルールで値を設定する方法にした方がわかりやすくないでしょうか?
else-ifとネストが続く場合、thenの中にifを書くな というのと同じく、ifを上部に全部押しやって、whenの中で全ての判断を行うようにします。
ルールの整理は、こういうところから始めていきます。条件分岐は少なければ少ないほど、後からの修正しやすいはずです。ルールで書くのを「例外ルール」と「基本ルール」とし、「例外ルール」で先に値を設定し、値が設定されていないものを「基本ルール」に適応させることで、構成はシンプルになります。
ルールからDBは参照するな
みなさん、マスターというテーブルをDB上に置いて、アプリからそれを参照させて値を決定していませんか。そうすることで「ロジック」に手を入れずに、「マスター」のデータを追加修正すれば、変更に強くなるからです。
誰もがそう思って信じて実装していました。私も昔は(笑)。
ところが、実際には「例外ルール」が発生し、マスターに記載できないケースが出てくるのです。その場合、アプリの中に例外ロジックを書きます。「ちょこっとだけだから良いか。」その油断があっという間に誰も解けないロジックのスパゲッティを作り上げてしまいます。しかも、「マスター」と「アプリ」の二重メンテナンスが発生するのです。
ルールエンジンもJavaで動きます。極論を言えば、ルール内部でJavaのソースコードを記述すれば、ルール内部からDBのマスターを参照することも可能です。ですが、これを許すと、今までスパゲッティで苦しんでいたものがコードからルールに移るだけで、なんのメリットもありません。
DBはデータを格納するもの、もしくは引き出すもの。その使い方に徹してもらいます。判断は全部ルールエンジン上で行う。判断に必要なデータがDB上にあるのであれば、ルールを実行する前にアプリがDBにアクセスしてデータをルールエンジンに投入します。ルールエンジンはあくまで「データとデータ」のマッチングを行い、マッチしたらアクションを起こし、ルールは全部一括で管理・実行します。
心を鬼にして、ルールからDBを参照しない。これを徹底することで、変化に強い仕組みになります。
BRMSの発展型
Business Resource Plannerの紹介
Business Resource Planner(以降 Planner)はJBoss BRMSに内包されている機能の一つで、ルールエンジンを活用して、さまざまなビジネスシーンにおけるリソースの最適解(組合せの最適化)を求めるソリューションです。
Plannerの得意とする問題の一つに「巡回セールスマン問題」というものがあります。これは、古くは、幾つもの都市を巡回する商人が最も効率良く(最小の移動コストで)全ての都市を移動できる方法を求める問題なのですが、現在では配送業者の配送ルートを策定する際にも応用されています。
この巡回セールスマン問題の難しさは、巡回すべき場所(配送業者であれば配送先)が増えれば増えるほど、配送ルートの数が爆発的に増加し、どのルートが最も効率的かを総当りで検証することが現実的ではなくなる(NP困難)と言う点にあります。
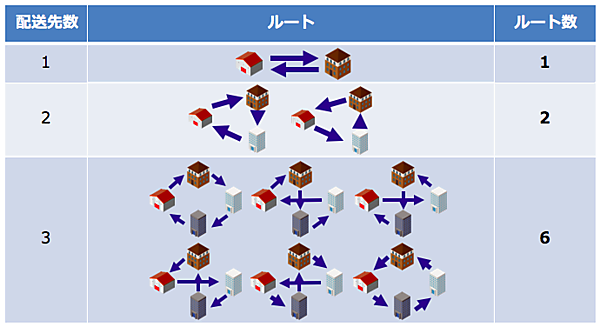

実際の配送業においては、上記に加え「配送車両の台数」や「荷物の積載制限」、「指定配送時間」など、より複雑な条件のもとルートを選定する必要があり、さらに難易度の高い問題を解決する必要があります。ベテランの配送員の方などは、この問題を長年にわたり培ってきた経験と勘によって解決しているのですが、Plannerも人間の思考と同じようにこのような複雑な制約条件をルールとして実装し、幾万通りも存在する組合せの中から、現実的な時間内で最も制約条件を満たす組合せを導出できます。
Plannerの最適化問題へのアプローチ
Plannerは大量の組合せを内部生成し、その組合せひとつひとつをルール(制約条件)と照らし合わせてスコアリング評価し、最もスコアの良い組合せを最適解として求めます。処理を簡単なイメージで表すと以下のようになります。
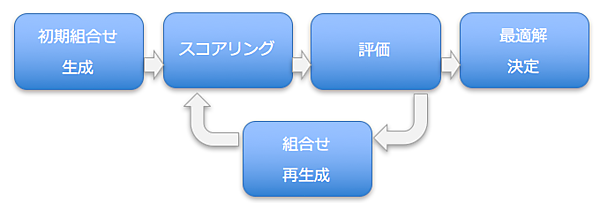
Plannerは内部生成した組合せに対してスコアリングと評価を行い、さらに良いスコアを求めて組合せを再生成、スコアリング、評価と、この処理を繰り返します。組合せの数が先ほどの配送ルートの例のように膨大である場合には、指定終了条件に達するまで、または現実的な時間内でこの処理を繰り返し、最終的にスコアが最も高得点であった組合せを最適解として求めます。
組合せを生成するときに、より良い組合せを効率的に探索できるようにPlannerには、経験則に基づいて近似解を求める人間の思考に近い手法(メタヒューリスティクス)を採用したさまざまなアルゴリズムが用意されています。
| 初期組合せ生成アルゴリズム | 概要 |
|---|---|
| First Fit | デフォルトの順番に従い組合せを逐次作成 |
| First Fit Decreasing | 後回しにすると割り当てが困難になる組合せから順に生成 |
| Weakest Fit | 割り当てにくい組合せから順に生成 |
| Weakest Fit Decreasing | First Fit DecreasingとWeakest Fitを組合せた方法 |
| Strongest Fit | 割り当てやすい組合せから順に生成 |
| Strongest Fit Decreasing | First Fit DecreasingとStrongest Fitを組合せた方法 |
| 最適解探索アルゴリズム | 概要 |
|---|---|
| Hill Climbing | 常に良いスコアとなる組合せを最適解として選択していく方法 |
| Tabu Search | 直近で生成した組合せと同じ評価を避けるために、直近で評価した組合せをタブーリストとして保持し、タブーリスト上にある組合せを評価対象外として探索を行う方法 |
| Simulated Annealing | 局所的な最適解探索に陥るのを防ぐために、スコア劣化となる組合せであっても確率的に評価対象として探索を行う方法 |
| Late Acceptance | 指定した過去の結果と比較して、現在評価対象のスコアが劣化しないよう、探索を行う方法 |
これらのどのアルゴリズムがもっとも適しているのか、また各アルゴリズムを利用するのに設定が必要なパラメータは何なのか、それらは解決する問題によってその都度異なります。
そこでいくつかのアルゴリズム(パラメータ含む)を一度に動作させることで、処理の結果を評価し、最適なアルゴリズムを導き出す手助けをしてくれるベンチマーク機能が提供されています。このベンチマーク機能を駆使して、各種チューニングを行うことで、処理時間を短縮したり解の精度を向上できます。
Plannerを利用するために必要な作業
では、Plannerを利用するためにはどのような準備が必要なのでしょうか。以下では、積載重量制限のあるトラックに対し、いろいろな重さの荷物をいかに効率よく積むことができるか、というビンパッキング問題を例にして見ていきたいと思います。

モデリング
Plannerでは組合せをEntityとValueという二つのオブジェクトで表現します。EntityはValueを入れる器を、ValueはEntityが採り得る値を表します。
- Entity = Valueを入れる器
- Value = Entityが取りうる値
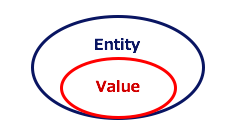
また、Plannerでは、「Entity:Value = N:1」が原則となります。

今回の例では、「トラック」と「荷物」の組合せを考える問題ですので、どちらかがEntityでどちらかがValueとなります。どのように定義するべきでしょうか。
1)Entity=「荷物」/Value=「トラック」 2)Entity=「トラック」/Value=「荷物」
EntityはValueを入れる器を表すと説明しましたので、「荷物を積むトラックが器に相当するな…」と、2)を選択しがちなのですが、この場合「Entity:Value=N:1」の原則により、「1台のトラックに複数個の荷物を積む」ということを表現できません。
1)のように、「荷物」をEntityとして表現することでこの表現が可能となります。このように組合せの関係が“1”対“多”の場合は、“多”のほうをEntityとしてモデリングします。
スコアリングルールの策定
次に、より良い組合せを評価(スコアリング)するための制約条件をルールという形で定義します。例えば以下のような制約を定義します。制約は重要度(その制約をどれくらい満たしたいか)で重み付けをするのが一般的です。

これをValueとEntityの関係で表現しなおすと以下のようになります。
| No. | ルール | 優先度 |
|---|---|---|
| 1 | トラック(Value)に設定されている積載重量制限を超えて荷物(Entity)に割り当てたら減点 | 必須 |
| 2 | トラック(Value)に設定されている配送地区内に荷物(Entity)の配送先がなければ減点 | 高 |
| 3 | トラック(Value)の配送先の数で減点 | 中 |
Plannerは通常のBRMSのルールエンジンを用いて組合せをスコアリングします。ですから、ルールの記述もまったく同じ、when-thenの形式で表記します。上記を例にすると、このようなイメージです。
rule "トラックへの荷物積載#1"
ruleflow-group "xxxx処理"
when
トラック(Value)に積載した荷物(Entity)の総重量を計算する。
その結果がトラック(Value)に設定されている積載重量制限より大きい。
then
スコア減算(100点)
end
rule "トラックへの荷物積載#2"
ruleflow-group "xxxx処理"
when
トラック(Value)に設定されている配送地区内の住所リストを取得する。
取得した住所リスト内に荷物(Entity)の配送先住所が存在しない。
then
スコア減算(80点)
end
rule "トラックへの荷物積載#3"
ruleflow-group "xxxx処理"
when
トラック(Value)に積載した荷物(Entity)の配送先の数をカウントする。
then
スコア減算(カウント数×5点)
end
実装
モデリングした結果やルール、その他Plannerを動作させるために必要な設定ファイルなどを実装します。下図はPlannerのアーキテクチャです。濃い緑色で示されているものが、実装物になります。
| Solver設定XML | 使⽤Javaクラス名、DRLルール、Solverアルゴリズムなどの設定 |
| PlanningSolution | 必要なクラス(データ)をまとめてSolverに渡す為に参照を保持 |
| PlanningEntity | Entityの実装。組合せの1単位としてSolver内で使用 |
| PlanningValue | Valueの実装。PlanningEntityに割り当てる値 |
| Fact | ルールでスコアリングする際に利用するデータを保持 |
| DRLルール | 制約条件のルール実装(Drools Rule Language:独自のルール記述言語) |
その他
実際のPlanner活用では、上記のほかにPlannerを呼び出すための業務アプリを実装したり、組合せの元ネタとなるデータの用意や、先にご紹介したベンチマーク機能を駆使してパフォーマンスチューニングをしたりする必要があります。
今回は紙面の関係で説明しきれなかった実装コードの例やチューニングの方法などは、
また別の機会があればご紹介したいと思います。Plannerはオープンソース「OptaPlanner」として公開されていますので、ご興味を持っていただいたかたはぜひお試しください。最後に
ご購読くださいましてありがとうございました。
SCSKとレッドハットはPlannerを含むJBoss BRMSを活用したシステム構築において協業を続けており、公共、通信、製造、電力の分野で導入の実績をあげています。また、毎月無料のハンズオンセミナーを定期開催しております。
今回のコラムでは語りつくせなかったことがまだまだたくさんあり、もっと話を聞きたい、というご意見もあろうかと思います。ご興味を持っていただいた方はぜひとも、このハンズオンセミナーを受けていただければと思います。セミナーでしかお話できない開発現場の裏話などもご好評をいただいております。ご検討ください。
- Red Hat JBoss BRMS(レッドハット社のサイト)
- Red Hat JBoss BPM Suite/BRMS(SCSK社のサイト)
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
