データ分析を専門に急速な成長を遂げているDATUM STUDIO株式会社。同社取締役の里 洋平氏は、大量のデータが集まる複数のネット系企業でデータ分析の経験を積んだのち同社を設立。急増するデータ分析業務に対応できる組織と人材育成に注力している。また、里氏は2010年に統計解析用言語であるRのコミュニティ「Tokyo.R」を立ち上げ、R言語によるデータ分析エンジニアの交流をサポートしている。今回はIoTやビッグデータが注目される中で、ますますニーズが高まるデータ分析の現状について里氏に伺った。
― 里さんはこれまで、どのようにデータ分析を経験してきたのでしょうか。
2009年に新卒でYahoo! へ入社し、Webエンジニアとしてデータベース設計などを担当していました。その後データアルゴリズムを扱う業務を担当し、動画のレコメンドエンジン開発や企業の評判上昇と株価の関連などを機械学習で分析したのが始めです。当時はPerlを使用していましたがRに移行しました。
その後DeNAに移り、モバゲープラットフォーム上でのデータマイニングやマーケティング分析を行っていました。
その次のドリコムでは、分析チームの立ち上げとチームの生産性を上げるためのスキルアップ業務を担当しました。新規事業でのデータ活用を支援するためのログ設計やシミュレータの作成も行いました。これらの業務を経て、現在のDATUM STUDIOを設立しました。

DATUM STUDIO株式会社 取締役 里洋平氏
― DATUM STUDIOはどのような分析業務を請け負っていますか。
主な業務は機械学習によるデータ分析です。クライアントは金融、通信、広告、製造など多岐に渡りますが、「所有するデータを有効利用して何か施策が打てないか」と考えている企業がメインのユーザーになります。
分析業務で重要なのは「問題設定」「課題設定」「ゴール設定」です。データ自体はさまざまな方向ややり方で掘り進むことができますが、一番大事なのは「設定したゴールに到達すること」です。
DATUM STUDIOでは標準として「1プロジェクト3か月」で設定していますが、最初のひと月は顧客の業務理解と業界の学習に充てています。その後データを整理して分析を行い、成果物としてレポートとWebツールやシミュレータのような実際に動きを目で確認できるものを提供しています。
プロジェクトは3か月が経過した段階で一度区切って、継続するパターン、増員するパターン、止めるパターンに分かれます。3か月というのは、これらを判断しお互いにリスクを軽減できる適度な期間なのです。長い期間、例えば1年かけて分析したけど成果が得られなかった場合などに不満を持たれるような事態は避けられます。
― ユーザーの企業規模は。また、どのようなセクションからの依頼が多いですか。
最近は大企業の案件が増えています。部署はマーケや企画、R&Dからの依頼が多いですね。データはシステム部門から直でいただくこともあります。私たちがSIと直接やるのは基盤構築などの案件ですね。
― 分析内容はどんなものが多いのですか。
TVCMを含む広告効果分析が多いですね。広告料金は高価ですが、「実際の効果がよく見えない」という状況は少なくありません。弊社では売り上げや購買数などのデータから各広告について分析するアルゴリズムを持っているので、効果的な分析できます。
― 分析の手順をもう少し詳しくお話しいただけますか?
最初のヒアリングでは、このようなフローをお見せしています。
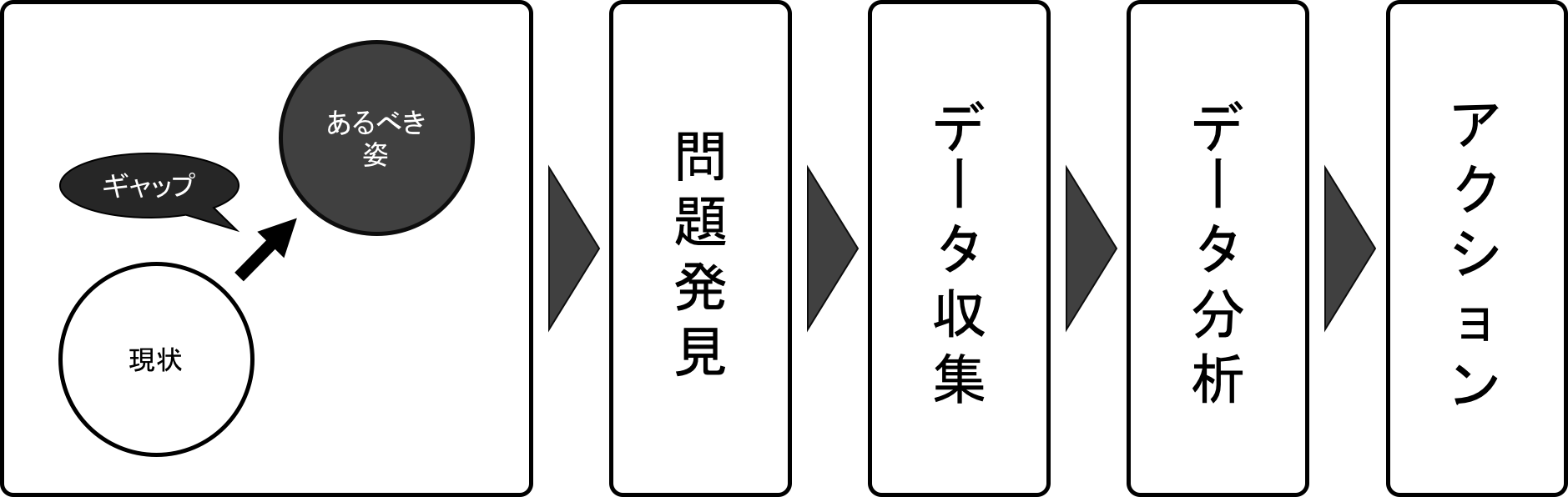
DATUM STUDIOのデータ分析フロー
業務の流れとしては、まず「状況把握」から「問題を発見」し、その問題を解決するための「データ収集」と「データ分析」を行い、最後に「実行」するというサイクルで行っています。1回で結果が出なければこのサイクルを繰り返していきます。
この中で特徴的と言えるのが「状況把握」の段階です。ユーザーの「現状」を把握し、「あるべき姿」としてのゴールを設定します。その「ギャップ」を埋めるための課題を見出し、課題を解決するために分析していくわけです。
― 分析で一番苦労する点はどのようなところですか。
データが汚い、ノイジーな状態であることはよくあります。そもそも分析用に作られたデータではないので、金額の欄なのに全角で入力されていたり、入るべきデータの位置がずれていたりします。そのため、まず分析できるデータにするための前処理が必要になります。分析の教科書ではデータがきれいな状態なので、すぐに手法から入っていけるのですが、実務ではデータの前処理がスタートですから、そこに乖離があります。
― データ分析で面白いと感じられるのはどのようなところですか。
「パズルを解くような試行錯誤」ですね。どのような分析でも一直線に解答へ行き着けるわけではなくて、何かしらの試行錯誤が必要になります。その過程でパズルがカチリと解けるように分析が上手く行ったときはとても気持ちが良いですね。
― ユーザーが分析結果に不満を持つことはありますか。
求められる精度と実際の分析結果がマッチングしないときです。例えば1万円の基準で9千円~1万1千円の精度で良いのか、もっと10円単位の精度が求められているのかということです。
マッチングの精度は業界によってズレに対する厳しさが違います。金融関係などは特に厳しいですね。プラスマイナスの許容範囲がどの程度あるか、提出されたデータでゴールに到達できるのか、ゴールへの到達は難しそうだけどチャレンジする価値があるか、といったことを最初に検討します。検討結果によっては追加のデータを用意してもらうこともありますが、それも難しければ現状のデータに合わせて分析テーマを変更するケースもあります。
― 最近ではIoTやビッグデータの発展でデータ分析が注目を集めてきています。そこにはどのような背景があるのでしょうか。
データが集まる業界は時代とともに変化しています。2000年くらいまでは通信や鉄道などの社会インフラ系の業界に大きなデータが集まっていました。
しかし、インターネットが大きく発展してきた2005年にはポータルなどに大量のデータが集まり、さらに2010年にはソーシャルゲーム業界に多くのデータが集まるようになりました。このような大きなデータが集まる業界で主にその有効活用が考えられており、データ分析のニーズも強くなっています。
― コミュニティ活動についてお聞きします。里さんは「Tokyo.R」というコミュニティを主宰されていますね。
Yahoo! 時代の2010年当時、業務でR言語を使う機会があったのですが、Rには国内にコミュニティがなく、「それなら作ってしまおう」ということで始めました。月1回程度で会合を催していますが、毎回大よそ100人くらい参加しています。今でこそRのコミュニティはいくつかありますが、そちらがアカデミック中心なのに対してTokyo.RのメンバーはWeb、金融、アカデミック、SIer、コンサル、マーケなどなど……さまざまな業界の方がいます。
Google上の「Tokyo.R」コミュニティページ。積極的に勉強会が開催されていることがわかる
Tokyo.Rで面白いのは、業界ごとに同じ分析手法でも使い方が異なっていたり、こちらの業界では問題になっていた点が別の業界ではすでに解決策が見つかっていたりすることですね。
分析者は企業内にそれほど多くいるわけではありません。1人だけということもザラです。そうなると仕事が煮詰まった時に誰も聞ける人がいないので、その意味でもコミュニティは良い刺激の場になっているのではと思います。
― R言語の特徴とはどのようなところでしょうか。ディープラーニングで人気のPythonとはどのように違うのでしょうか。
Rは統計学者が統計を行うために作った言語なので、「とにかく結果が出せれば良い」という面があります。RもPythonもほぼ同じことができますが、Rはリスト処理が簡単で複雑なことも手をかけずにできてしまいます。分析するには「かゆいところに手が届く」言語と言えるでしょう。文系の人もよく使っていますし、何より多少曖昧に書いてもちゃんと動く点はメリットだと思います。
ただし、覚えなくてはいけない作法がけっこうあるので、そこで苦労する人もいるでしょう。これまで他の言語で開発してきた人もRに抵抗を抱きがちです。Rにはエンジニアの美意識を無視しているところがありますし、Pythonのほうがきれいなコードが書けます。システムへの組み込みもPythonのほうが楽ですからね。
― 里さんはR言語を長くお使いですよね。「CRAN」について簡単に説明していただけますか。
「CRAN」はRのパッケージ管理プラットフォームです。PerlのCPANみたいなものです。パッケージの最新バージョンや登録されているパッケージを入手したりするのに利用します。私もRのパッケージをいくつか開発してCRANに掲載しています。
例えば、クラスタリングで乱数を利用すると毎回結果が変わりますが、ユーザー側は毎回結果が変わると困るケースもあるため100回で平均値を取るようなパッケージや、BIツールの結果をレポートメールにして毎日送信するパッケージなどを開発しました。
― 4月には「データサイエンス基礎講座<Python演習編>」が開催されました。昨年に引き続いて(詳細はこちらを参照)の開催となりましたが、手ごたえはいかがでしたか。
内容としては、昨年12月に開催したセミナーとほぼ同じものを実施しました。違いとしては、前回はデータ分析のツールとしてRとPythonの2つの言語を使用しましたが、今回はPythonにしぼりました。1つの言語に絞ったことで、より深い内容を実践できたのではないかと思います。
一方で、今後の課題として受講者のスキルの差への対応があります。特にプログラミングの経験者と未経験者では、コーディングのスピードが全然違うため、何かしらの工夫をする必要性を感じました。今後の講座では、この辺を改善したいと考えています。
里氏はDATUM STUDIOでの業務やTokyo.Rにおけるコミュニティ活動に携わる傍ら、多くの書籍も執筆している。興味があれば、ぜひ手に取って読んでみてほしい。
- 「データサイエンティスト養成読本」(技術評論社)
- 「ビジネス活用事例で学ぶデータサイエンス入門」(ソフトバンククリエイティブ)
- 「Rではじめるビジ ネス統計分析」(翔泳社)
- 「戦略的データマイニング (シリーズ Useful R 4)」(共立出版)
- 「Rパッケージガイドブック」(東京図書)
DATUM STUDIOは2月13日に事務所を移転。社員は70名ほどだが、「常に社員数より案件数のほうが多い状態」とのことだ。「大企業でもデータ分析のセクションでは人手不足で、外部に頼ることが多い」(里氏)という同社は今後ますますの成長が期待できるだろう。

移転祝いの花に囲まれた中で記念撮影。エントランスは多くの花が醸し出す香りの競演となった
- この記事のキーワード
この記事をシェアしてください
関連記事
DATUM STUDIOが「産学連携」と「AIのビジネス活用」をテーマに「AIアカデミックネットシンポジウム」を初開催!
2017年7月13日 0:00
Deep Learningの習得にはスクラッチでの実装が効果的
2017年3月8日 0:30
ハイプ・サイクルに登場する技術③ー ディープラーニングの基礎技術
2021年9月1日 6:42
「会社すべてがIT企業に」を目指すマネックス証券 基幹システムの内製化により社内意識が大きく変わり始めた
2017年10月12日 6:00
Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
2018年5月15日 16:00
ディープラーニングでビジネスする企業の事例が大集合 ーDeep Learning Labイベント
2017年12月14日 16:00
バックナンバー
この記事の筆者
筆者の人気記事
データセンターは利用から所有する時代へ―520万円コンテナ個人データセンター誕生秘話
2018年1月27日 0:00
「会社すべてがIT企業に」を目指すマネックス証券 基幹システムの内製化により社内意識が大きく変わり始めた
2017年10月12日 6:00
Deep Learningの習得にはスクラッチでの実装が効果的
2017年3月8日 0:30
「DATUM STUDIO Conference 2017(夏)」同社がデータ分析をサポートするユーザー事例を紹介【前編】
2017年8月10日 0:00
データ収集にはオープンソース化よりAPI提供が適している―リクルート「A3RT」無料公開の裏側
2017年5月26日 0:30
急増するデータ分析ニーズに「1プロジェクト3か月」設定で解答を出す
2017年5月11日 0:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
