機械学習の実践
機械学習の実践
これで、機械学習に必要なツールと環境は全て揃いました。ここからはコードレベルで機械学習の開発、検証を進めていきます。
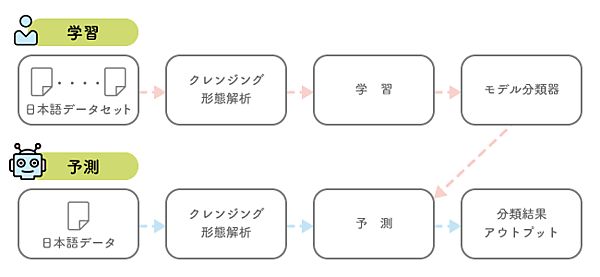
今回のサンプル作成においては、学習データとして前述したようにThinkITの各記事のタイトルとそのカテゴリの情報を使用します。過去にカテゴリ分けされた情報を機械学習することで、新規の記事のタイトルにおいても機械学習で学習した法則・パターンを適用します。機械学習で生成したモデルを使用し、RPAから分類する作業を自動化します。
こちらは、ぜひ皆さんの業務データから、機械学習に適用できそうなものを使用して分類精度を確認してみてください。
形態素解析、クレンジング処理
我々が日本国内で機械学習を実施するとき、障壁の一つとなるのが日本語の扱いです。機械学習で日本語の識別や分類をする際、日本語の文章を品詞単位で仕分けをする必要があります。加えて、今回のケースでは、助詞や助動詞などの品詞は機械学習の分類においては関連性、相関は低いと判断できるので、今回は除外します。従って、名詞、動詞、形容詞といった単語のみを抽出しますが、数値や一部の特定の記号も不要にしたいと思います。このように、機械学習で日本語の識別や分類をする際には、日本語の文章から助詞や助動詞など不要となる要素を省いた情報のみにすることが重要なポイントとなります。
今回のようにタイトルをカテゴリに分類する際、そのタイトルの文章を完全に理解させるより、キーとなる単語を抽出し、その出現頻度や相関をモデル化するべきということです。今回は先程追加でインストールしたJanomeを使用して、日本語を形態素解析します。
from janome.tokenizer import Tokenizer
def parse_text(text, tokenizer):
res=[]
tokens=tokenizer.tokenize(text)
for token in tokens:
ps=token.part_of_speech.split(",")[0]
if not ps in ['名詞', '動詞', '形容詞', '記号']:
continue # 他の品詞は無視
ps=token.part_of_speech.split(",")[1]
if ps in ['数']:
continue # 数以外は無視
w=token.base_form
# 一部の記号は無視
if w==" " or w=="_" or w=="/" or w=="~" : continue
res.append(w)
return(res)
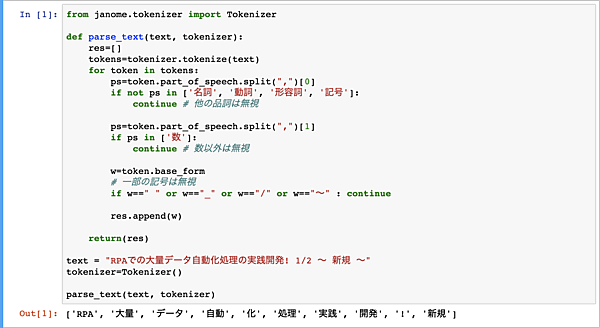
text = "RPAでの大量データ自動化処理の実践開発! 1/2 ~ 新規 ~"
tokenizer=Tokenizer()
parse_text(text, tokenizer)上記のparse_text(text, tokenizer)メソッドでは、入力されたテキストから名詞、動詞、形容詞、記号のみ抽出し、数値や一部の記号は無視するというテキストデータのクレンジング処理を行うものとなります。具体的には、JanomeのTokenizerにて、引数のtextを形態素解析し、その結果から品詞をチェックします。その後、数値であれば無視、特定の記号は無視という処理順序となります。最後にチェック後に残った単語のみをリストで返します。
なお、「classifier.py」のコード内では、こちらのメソッドの実装があり、その中では'名詞'をb'\xe5\x90\x8d\xe8\xa9\x9e'.decode("utf-8")と記載しています。これはUiPath側の仕様で現時点、日本語のUTF-8の文字を取り扱えない為の苦肉の策です。本来記載したかった日本語をあえてUTF-8のバイト文字列で記載しておき、こちらをデコードしUTF-8の日本語の文字として取り扱えるようにしています。
もう一点、UiPathの仕様の制限としては、Pythonのスクリプトを取り込む際、外部でユーザが作成した別のファイルをimportできません。こちらは今後改善されていきます。
分類機の作成
では、機械学習のモデルの作成に取り掛かります。「Jupyter Notebook」へ新たにセルを追加し、以下のコードを貼り付けます。このコードは、次の手順で分類器を作成、検証していきます。
- CSVファイルから日本語タイトルとカテゴリの情報を読み取り、PandasのDataFrameとして保存
- 日本語タイトルの形態素解析、クレンジング
- 日本語タイトルとカテゴリを学習データとテストデータに8:2で分割
- 日本語データを
TF-IDF(TfidfVectorizer)にて、単語の出現頻度と希少性を基にベクトル化(数値化) - SVM(サポート・ベクター・マシーン)にて、機械学習における学習、モデル作成(https://scikit-learn.org/stable/modules/svm.html#classification)
- 学習データ自身に対するモデルの精度検証
- テストデータに対するモデルの精度検証
- テストデータについて、各日本語タイトルに対する検証
import pandas as pd
from janome.tokenizer import Tokenizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.externals import joblib
from sklearn.model_selection import train_test_split
from sklearn import linear_model
file = "./thinkit_category.csv"
#Janomeを使って形態素解析のインスタンスを生成
ja_tokenizer = Tokenizer()
# CSVファイルからの日本語タイトルとカテゴリの情報を読み取り、PandasのDataFrameとして保存
df = pd.read_csv(file, encoding="utf-8")
# 日本語タイトルの形態素解析、クレンジング
parsed_text_list = []
for text in df["title"]:
res = parse_text(text, ja_tokenizer)
parsed_text_list.append(' '.join(res))
X = parsed_text_list
Y = df["category"].values
# 学習データとテストデータを8:2で分割
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.80, test_size=0.20, random_state=0)
# 日本語データを`TF-IDF`(`TfidfVectorizer`)にて、単語の出現頻度と希少性を基にベクトル化(数値化)
vect = TfidfVectorizer()
vect.fit(X_train)
X_train_vect = vect.transform(X_train)
# SVM(サポート・ベクター・マシーン)にて、機械学習における学習、モデル作成
clf = SVC(kernel='linear', probability=True)
clf.fit(X_train_vect, Y_train)
# 学習データ自身に対するモデルの精度検証
print("学習データの精度", clf.score(X_train_vect, Y_train))
# テストデータに対するモデルの精度検証
X_test_vect = vect.transform(X_test)
print("テストデータの精度", clf.score(X_test_vect, Y_test))
# テストデータについて、各日本語タイトルに対する検証
test_size = len(Y_test)
correct_count = 0
for text, expected, predicted in zip(X_test, Y_test, clf.predict(X_test_vect)):
result = "OK" if expected == predicted else "NG"
if result == "OK": correct_count += 1
print(result, "E", expected, "P", predicted, "[", text, "]")
print("{0} / {1} = {2}".format(correct_count, test_size, correct_count / test_size ))「Jupyter Notebook」にて分類器の作成と検証を実行したところ、次の結果が得られました。
「学習データ自身に対するモデルの精度検証」約84%
モデルの作成に使用した「学習データ」を、そのままインプットとして、機械学習の分類精度を検証したところ約84%の精度となりました。「学習データ」と「テストデータ」を同じものとしたので、良い精度が得られることが期待されるものです。
「テストデータに対するモデルの精度検証」約63%
作成したモデルに対して、予め用意しておいた「テストデータ」をインプットとして、機械学習の分類精度を検証したものです。
学習データの精度 0.8369384359400999
テストデータの精度 0.6289517470881864
OK E 業務アプリ P 業務アプリ [ デバイス 不要 完全 没入 型 VR システム 登場 ]
OK E ITインフラ P ITインフラ [ Cloud Foundry Summit エコ システム 拡がり 感じる カンファレンス ]
OK E 業務アプリ P 業務アプリ [ バンナム VR アーケード 機 専門 子会社 設立 「 リアルエンタメ 」 展開 加速 ]
OK E 業務アプリ P 業務アプリ [ DWH プライベート ・ クラ ウド 化 ]
OK E システム開発 P システム開発 [ 半日 業務 アプリケーション 開発 できる ! ( 後編 ) ]
NG E システム開発 P 運用管理 [ ユーザビリティ 判断 基準 何 ? ]
OK E ITインフラ P ITインフラ [ サーバー 仮想 化 重要 技術 ]
OK E ITインフラ P ITインフラ [ 現代 PC 基礎 知識 ( ): ストレージ つながる ホストインタフェース ]
NG E 業務アプリ P ITインフラ [ 選択肢 広がる BI 製品 ]
---省略---
378 / 601 = 0.6289517470881864機械学習としてはテストデータの予測精度において、80%、90%の結果を得たいところです。5クラス分類では適当に分類して20%の確率であり、それよりは高い精度を得られたため、今回はこれでよしとして、RPAとの連携に進みたいと思います。なお機械学習の精度を高める、また、モデルである分類器の精度を検証するという点においては、次のような手法があります。
- 使用するモデル(分類器)で、他の手法を試す
- モデル(分類器)のパラメーターを調整する
- データ数に応じて、Hold-Out、k-Fold、Leave One Outといったバリデーション手法で精度検証を行う
学習(Training)
モデルである分類機の作成、検証が一通りできました。ここからは、RPAとの連携を踏まえて、学習(Training)と予測(Predicting)にメソッドを分け、RPAとの融合を進めます。
以下のコードは、training(file, vect_path, clf_path)メソッド内にて、機械学習における学習からモデルの保存までを処理するものです。
- CSVファイルからの日本語タイトルとカテゴリの情報を読み取り
- 日本語タイトルの形態素解析、クレンジング
- 日本語データを
TF-IDF(TfidfVectorizer)にて、単語の出現頻度と希少性を基にベクトル化(数値化) - SVM(サポート・ベクター・マシーン)にて、機械学習における学習、モデル作成(https://scikit-learn.org/stable/modules/svm.html#classification)
- モデルの保存
def training(file, vect_path, clf_path):
#Janomeを使って形態素解析のインスタンスを生成
ja_tokenizer = Tokenizer()
# PandasにてCSVファイルの読み取りDataFrameの形式で保存
df = pd.read_csv(file, encoding="utf-8")
# DataFrameのtitleのカラムをループし、日本語タイトルのクレンジング
train_list = []
for text in df["title"]:
res = parse_text(text, ja_tokenizer)
train_list.append(' '.join(res))
# 日本語データのベクトル化
vect = TfidfVectorizer()
vect.fit(train_list)
X = vect.transform(train_list)
Y = df["category"].values
# SVMでのフィッティング、モデル作成
clf = SVC(kernel='linear', probability=True)
clf.fit(X, Y)
# モデルの保存
pkl_save(vect, vect_path)
pkl_save(clf, clf_path)
# 検証用として、DataFrameへクレンジング後のものを追加
df["mod title"] = train_list
return df
こちらはclassifier.py内に記載した、同じメソッドを呼び出す為のコードです。Jupyter Notebookから実行できます。
import classifier
file = "./thinkit_category.csv"
vect_path = "classifier_vect.pkl"
clf_path = "classifier_clf.pkl"
classifier.training(file, vect_path, clf_path)実行すると、プロジェクトフォルダにモデルのファイルが作成されます。
予測(Predicting)
予測のためのコードは以下の通りです。予測する新たなタイトルはリストで受け取り、学習時に作成したモデルのファイルも引数でそのパスを受け取ります。
- モデルの読み込み
- 日本語タイトルのクレンジング
- 日本語データのベクトル化(数値化)
- SVM(サポート・ベクター・マシーン)での予測
- スコア(0〜1でモデルにより出力されるスコア。1に近いほど精度は高いとみなす)の取得(オプション)
def predicting(predict_list, vect_path, clf_path):
#Janomeを使って形態素解析のインスタンスを生成
ja_tokenizer = Tokenizer()
# モデルの読み込み
vect = pkl_load(vect_path)
clf = pkl_load(clf_path)
# インプットがテキスト(String)の場合、リストへ変更
if isinstance(predict_list, str):
predict_list = [predict_list]
# 予測する日本語タイトルのクレンジング
alt_predict_list=[]
for text in predict_list:
res = parse_text(text, ja_tokenizer)
alt_predict_list.append(' '.join(res))
# 日本語データのベクトル化
X = vect.transform(alt_predict_list)
# SVMでの予測
result_list = clf.predict(X)
# スコアの取得
predict_proba_test_scores = clf.predict_proba(X)
score_list = list(map(lambda x: max(x), predict_proba_test_scores))
# 検証用にDataFrameの作成
df = pd.DataFrame(predict_list, columns=['title'])
df['mod title'] = alt_predict_list
df['result'] = result_list
df['score'] = score_list
return dfこちらが「classifier.py」内に記載した、同じメソッドを呼び出すためのコードです。スコアはオプションとして算出しているもので、必須ではありません。なお、predict_probaでスコアの取得をしていますが、予測にてすでにpredictで分類作業をしおり、処理が冗長しています。Jupyter Notebookから実行・検証ができます。
import classifier
predict_list = [
"デバイス不要の完全没入型VRシステムが登場", # 業務アプリ
"Cloud Foundry Summitはエコシステムの拡がりを感じるカンファレンス", # ITインフラ
"ユーザビリティの判断基準って何?", # システム開発
"選択肢が広がるBI製品", # 業務アプリ
"3種類のノードをセットアップ!" # 運用管理
]
classifier.predicting(predict_list, vect_path, clf_path)Jupyter Notebookでの実行結果は次の通りとなりました。
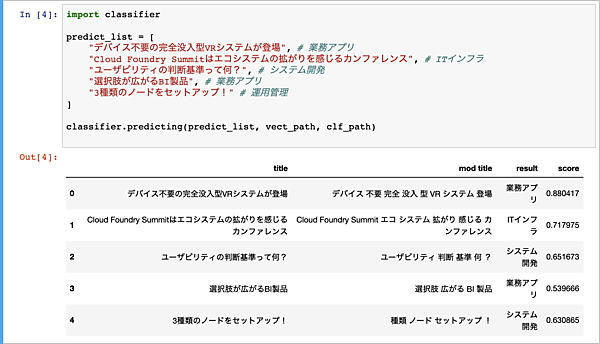
UiPathのロボットから呼び出す際は、引数に一つのタイトルを受け取り、結果としてカテゴリとスコアを返す為に専用のメソッドpredicting_for_uipath(predict_text, vect_path, clf_path)を用意しています。
def predicting_for_uipath(predict_text, vect_path, clf_path):
df = predicting(predict_text, vect_path, clf_path)
return [df['result'].iloc[0], str(df['score'].iloc[0])]呼び出し用のコードはこちらです。
import classifier
predict_text = "デバイス不要の完全没入型VRシステムが登場"
classifier.predicting_for_uipath(predict_text, vect_path, clf_path)次のように、1件の日本語テキストも期待通りに処理されています。

UiPathでのPython連携
Pythonスコープ
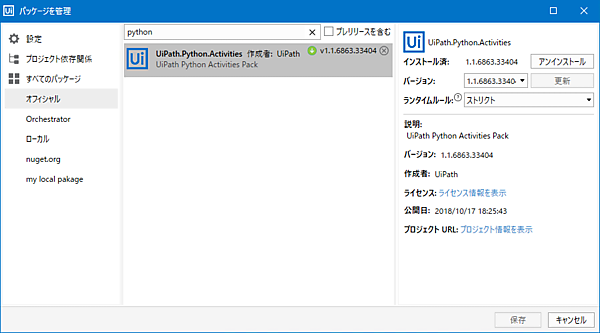
UiPath Studioにて、Pythonを設定していきます。まず、Pythonアクティビティの使用にあたり、「パッケージを管理」より「UiPath.Python.Activities」を追加でインストールします。「パッケージを管理」に関しては、前回の記事(チャットアプリとRPAとの連携)に詳細を解説しています。
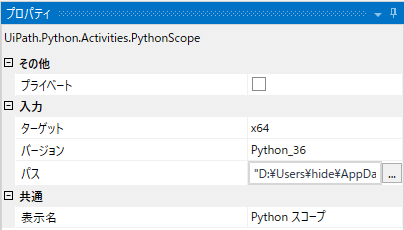
それでは、「Python スコープ」アクティビティをワークフローに配備し、そのプロパティにて下記の要領でインストール形態に合わせて指定していきます。Python 3.6 64bitに合わせて設定を行い、パスは「Just Me」でインストールした場合のものです。パス中のユーザ名(<user name>)は適宜変更してください。
- ターゲット: x64(Python 64bit)
- バージョン: Python_36(Python 3.6)
- パス: “D:\Users\
\AppData\Local\Continuum\anaconda3”
RPAでの実装
- 入力ダイアログにて、新たなタイトルをユーザからインタラクティブに取得
- Pythonスクリプトをロード後、Pythonのスクリプトを指定し、Pythonオブジェクトを生成
- Pythonオブジェクトを生成し、新たなタイトルを引数として、予測のメソッドを呼び出し
- 呼び出し結果の文字列の配列を、UiPathの.Netの型へ変換
- 結果をメッセージボックスとして表示

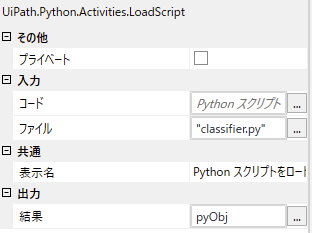
「Python スコープ」では、各種パラメータを前述した通りに設定しておきます。「Python スクリプトをロード」アクティビティでは、ファイルへPythonの今回のスクリプトである「classifier.py」を指定し、結果にpyObjというPythonのオブジェクトを格納する変数を設定します。
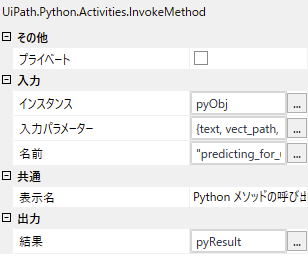
「Python メソッドの呼び出し」アクティビティでは、インスタンスに先ほどのpyObj、名前にpython側のメソッド名であるpredicting_for_uipath、その引数を入力パラメーターに配列{text, vect_path, clf_path}として設定します。また出力には、pyResultという結果を格納する変数を設定します。
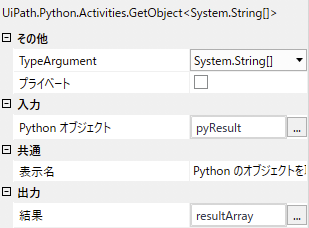
「Python のオブジェクトを取得」では、先ほどのpyResultをUiPathの.NetのresultArrayという変数へ変換します。なお、この型は、TypeArgumentに指定したSystem.String[]となります。
最後に「メッセージボックス」アクティビティにて、結果を表示します。以下のように、分類結果とスコアを画面に表示するワークフローとしました。
“分類結果:” + resultArray(0).ToString + Environment.NewLine + “スコア:” + resultArray(1).ToString
動作検証
UiPath Studioにて検証を行います。自動化処理を実行すると、入力ダイアログボックスが表示されます。Jupyter Notebookでの予測と同じく「デバイス不要の完全没入型VRシステムが登場」という文字列を入れてみます。
Jupyter Notebookでの結果と同じになれば成功です。

サンプルのダウンロード
ここで使用したサンプルは、以下からダウンロードできます。
まとめ
機械学習がPythonで実装できたことを確認し、またそのモデルをUiPathから利用できれば、今回の目標は達成です。私自身は、AIとRPAを連携させる際に、学習データの取り込みをPython側で行うか、UiPath側で行うかで悩んだりしました。色々と試行錯誤した結果、学習データの取り込みからモデル作成まではPython側で行い、業務においてはUiPathのロボットを用いたAIによる分類がユーザ側で実施可能となる実装としました。
今回、UiPath側はPythonの呼び出しに終始していますが、様々な応用が考えられます。簡単なところでは、入力データを変更したり、機械学習のモデルを変更したりすることで、その他の業務への応用が可能です。また、実際の運用においては、機械学習の予測精度に問題がある場合、再学習でモデルを強化する必要があります。UiPathを活用することで、利用者にとってもより便利なワークフローを作成できるかと思います。例えば、RPAで予測結果を人間に評価させたり、予測精度を高める為に再学習のフローをRPAで組み込むといったものです。
ぜひ、自動化の次の一歩としてご活用下さい。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
