サンプルで利用するデータセットとモデルの解説(ハンズオン)
サンプルで利用するデータセットとモデルの解説(ハンズオン)
本稿の冒頭で作成したJupyter notebookを使って、サンプルで利用するデータセットとモデルの解説をします。このハンズオンは「初期の機械学習モデル」の作成を想定して、各ステップの作業を実際に操作しながら解説します。
ハンズオンで解説するステップと流れ
- 前準備:必要なライブラリのインポート、データセットのダウンロードをします
- データ分析:データセットの内容を集計や可視化をしながら確認します
- データ変換:モデル学習で利用するデータを作成する処理を記述します
- データ分割:「学習データ」と「評価データ」に分割し、データ変換処理を実行します
- モデル学習:モデルを学習します
- モデル評価:モデルの精度評価をします
利用するデータセット
「米国国勢調査所得データセット」を利用し解説を進めます。このデータセットは、米国勢調査局が行った1994年国勢調査のサブセットデータとなっていて、米国の就労成人の学歴や職業などの属性情報と年収が5万ドル以上か未満かのラベルが付与されています。
主な項目の説明
| 項目名 | データ型 | 種類 | 説明 |
|---|---|---|---|
| age | 数値 | 連続変数 | 年齢 |
| workclass | 文字列 | カテゴリー変数 | 職業クラス |
| education | 文字列 | カテゴリー変数 | 教育 |
| education-num | 数値 | 連続変数 | 教育年数 |
| marital-status | 文字列 | カテゴリー変数 | 配偶者の有無 |
| occupation | 文字列 | カテゴリー変数 | 職業 |
| relationship | 文字列 | カテゴリー変数 | 続柄 |
| gender | 文字列 | カテゴリー変数 | 性別 |
| capital-gain | 数値 | 連続変数 | 資産益 |
| capital-loss | 数値 | 連続変数 | 資産損 |
| hours-per-week | 数値 | 連続変数 | 週の労働時間 |
| income | 文字列 | カテゴリー変数 | 年収カテゴリー(教師ラベル※予測対象の項目) |
モデルについて
個々の回答者の年収が5万ドル以上か未満かを予測するモデルを作成します。なお、執筆時点でTensorFlow Extended(TFX)の学習で利用するコンポーネント(Trainer)はTensorFlowまたはKerasのモデルが標準となるため、本稿ではKerasのモデルを作成します。
それでは、冒頭で作成したノートブックを開いて進めていきましょう。
前準備
今回の機械学習モデルの開発に必要なライブラリをインポートします。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
import matplotlib.pyplot as plt
import seaborn as sns
データセットをダウンロードし、データセットの内容を確認します。
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data -O adult.data
!head adult.data
図3-1:データセットダウンロード実行結果とその内容
データセットの内容を確認すると、以下のことがわかります。
- データセットにヘッダが存在していない
- 区切り文字(カンマ)のあとにスペースが存在している
これらを踏まえてヘッダを付与しつつ、必要なカラムだけをPandasのDataFrameに読み込みます。
header = [
'age','workclass','id','education','education-num','marital-status',
'occupation','relationship','race','gender','capital-gain','capital-loss',
'hours-per-week','native-country','income'
]
df = pd.read_csv('adult.data', names=header, delimiter=', ', usecols=lambda x: x not in ['id', 'race', 'native-country'])
読み込んだDataFrameの内容を確認します。
df.info()

図3-2:DataFrameの要約情報
これにより、5つの数値カラム(Dtypeがint64のもの)と7つのオブジェクトカラム(Dtypeがobjectのもの)が混在していることがわかります。また、このDataFrameには欠損値が存在していないこともわかります。
DataFrameの実際の内容も表示して正しく読み込めているかを確認します。
df.head()

図3-3:DataFrameの内容
データ分析
次に、データセットの各項目を見渡してみます。
・データセットの統計量を確認
df.describe()

図3-4:連続変数項目の統計量
統計量を確認することで、以下のようなことがわかります。
- age(年齢)の範囲は17歳~90歳
- education-num(教育年数)の範囲は1~16
- capital-gain(資産益)の範囲は0~99999
- capital-loss(資産損)の範囲は0~4356
- hours-per-week(週の労働時間)の範囲は1~99
- capital-gainとcapital-lossは75%の値が0なので外れ値が予想できる
・カテゴリー変数の分布の確認
カテゴリー変数の項目に存在している値の分布をグラフ化します。
categorical_features = df.drop('income', axis= 'columns').select_dtypes(include=[np.object]).columns.values
plt.figure(figsize=(30, 30))
plt.subplots_adjust(hspace=0.8)
for i, col in enumerate(categorical_features):
ax = plt.subplot2grid((5, 3), (i//3, i%3))
sns.histplot(df[col], ax=ax)
locs, labels = plt.xticks()
plt.setp(labels, rotation=90)
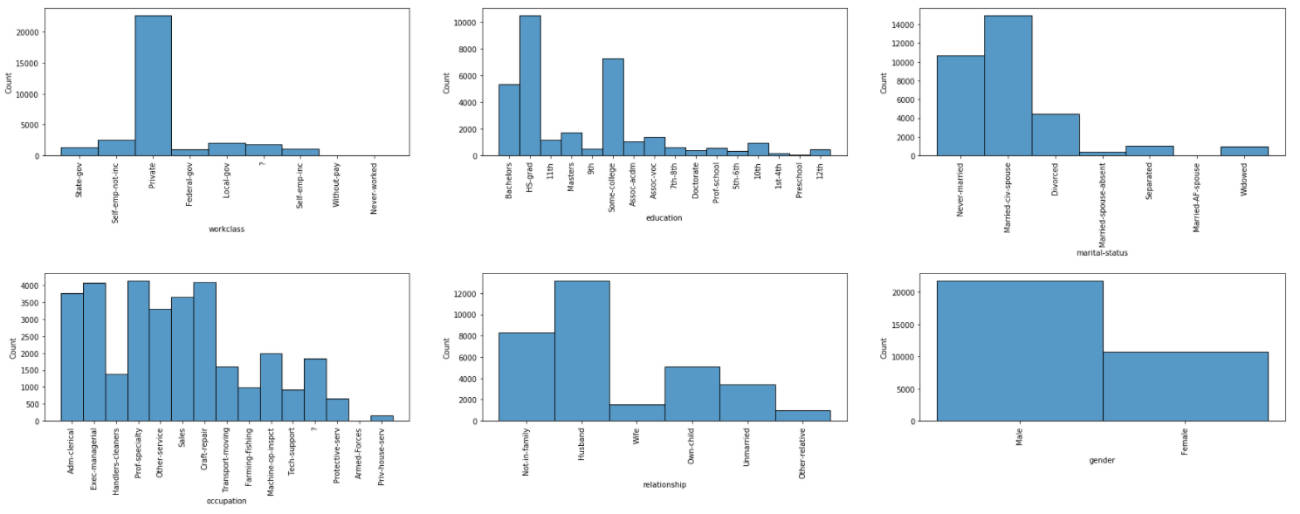
図3-5:カテゴリー変数項目の分布
これらのグラフより、各項目について下記のようなことがわかります。
| 項目名 | 分析内容 |
|---|---|
| workclass | ・8種類のカテゴリーが存在している ・大多数が「Private」(民間企業)となっている ・欠損値を意味する「?」が存在している |
| education | ・16種類のカテゴリーが存在している ・「HS-grad」(高卒)が最も多く、次いで「Some-college」(大学学科履修)、「Bachelors」(学士号)となっている |
| marital-status | ・7種類のカテゴリーが存在している ・「Married-civ-spouse」(一般市民と結婚)が最も多く、「Married-AF-spouse」(軍人と結婚)が最も少ない |
| occupation | ・14種類のカテゴリーが存在している ・欠損値を意味する「?」が存在している |
| relationship | ・6種類のカテゴリーが存在している ・「Husband」(夫)が最も多く、「Other-relative」(その他の続柄)が最も少ない |
| gender | ・このデータセットの回答者には2種類のカテゴリーが存在している ・割合は「Male」(男性)が「Female」(女性)の2倍ほど存在している |
また、予測対象の項目についても値の分布をグラフ化します。
sns.countplot(x = df['income'])
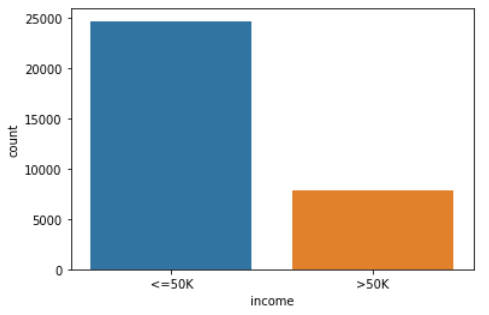
図3-6:予測対象の項目の分布
予測対象の項目には「<=50K」と「>50K」の2つの値が存在していることがわかります。そして、5万ドル以上の収入を持つ人が少ないことが確認できます。これにより、このデータセット自体にデータの偏りがある(不均衡なデータセット)ということがわかります。
・連続変数の統計量を箱ひげ図で確認
連続変数の項目の統計量を箱ひげ図で可視化して確認します。これにより、各項目の値の範囲や外れ値の有無などを確認します。
numeric_features = df.drop('income', axis= 'columns').select_dtypes(include=[np.int64]).columns.values
plt.figure(figsize=(30, 30))
plt.subplots_adjust(hspace=0.8)
for i, col in enumerate(numeric_features):
ax = plt.subplot2grid((5, 3), (i//3, i%3))
sns.boxplot(x=df[col], ax=ax)
locs, labels = plt.xticks()
plt.setp(labels, rotation=90)
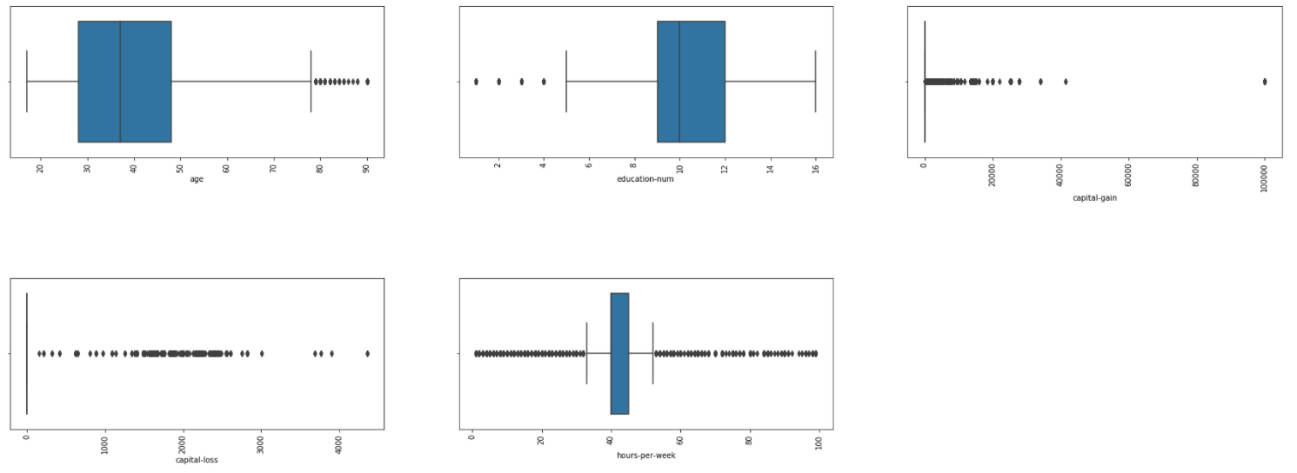
図3-7:連続変数項目の箱ひげ図
この結果から、各項目で取りうる値の範囲が異なることや外れ値が存在していることがわかります。
データ変換
データ分析によって確認できたことをもとに、データを変換することで特徴ベクトルを作成していきます。このステップでは、以下のデータ変換処理を行います。
・欠損値の補完
「?」の値が存在する項目「workclass」「occupation」に対して、値の置換処理を行います。今回は、最も数の多いカテゴリー(最頻値)で置き換えます。
def replace_missing_value(df):
df.loc[df['workclass']=='?', 'workclass'] = 'Private'
df.loc[df['occupation']=='?', 'occupation'] = 'Prof-specialty'
・標準化
「データ分析」のステップで連続変数の項目の値は、取りうる値の範囲が異なることや外れ値が存在していることがわかっています。今回は各項目に対して、標準化(平均:0、標準偏差:1に変換)を行います。
numeric_transformer = StandardScaler()
・カテゴリー変数のエンコード
カテゴリー変数を特徴ベクトルとして扱うために、数値化します。今回は、One-Hotエンコーディングでダミー変数に変換します。
categorical_transformer = OneHotEncoder(handle_unknown='ignore')
データ分割
このステップでは「学習データ」と「評価データ」に分割します。データセットには予測対象の項目が含まれるため、特徴ベクトルとして利用するデータと教師ラベルのデータに分割を行います。
df['income'] = np.where(df['income'] == '>50K', 1, 0)
x = df.drop('income', axis= 'columns')
y = df['income']
「学習データ」と「評価データ」に分割します。
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=0)
「学習データ」:X_train、「評価データ」:X_test、「学習データの正解ラベル」:y_train、「評価データの正解ラベル」:y_testに分割されました。
分割した「学習データ」と「評価データ」に対して、データ変換の処理を行います。まずは「学習データ」のデータ変換を行い、変換した結果を確認します。
replace_missing_value(X_train)
X_nt_fit = numeric_transformer.fit(X_train[numeric_features])
X_ct_fit = categorical_transformer.fit(X_train[categorical_features])
X_train_nt_df = pd.DataFrame(X_nt_fit.transform(X_train[numeric_features]),
columns=numeric_features,
index=X_train.index)
X_train_ct_df = pd.DataFrame(X_ct_fit.transform(X_train[categorical_features]).toarray(),
columns=X_ct_fit.get_feature_names(categorical_features),
index=X_train.index)
X_train_transformed = X_train_nt_df.join(X_train_ct_df)
X_train_transformed.head()
図3-8:データ変換結果(学習データ)
次に「評価データ」に対してデータ変換処理を行います。
replace_missing_value(X_test)
X_test_nt_df = pd.DataFrame(X_nt_fit.transform(X_test[numeric_features]),
columns=numeric_features,
index=X_test.index)
X_test_ct_df = pd.DataFrame(X_ct_fit.transform(X_test[categorical_features]).toarray(),
columns=X_ct_fit.get_feature_names(categorical_features),
index=X_test.index)
X_test_transformed = X_test_nt_df.join(X_test_ct_df)
X_test_transformed.head()
図3-9:データ変換結果(評価データ)
モデル学習
このステップではモデルの学習を行います。今回は以下に示すモデルアーキテクチャを利用します。なお、本稿ではモデルアーキテクチャやアルゴリズムの詳細は取り上げません。
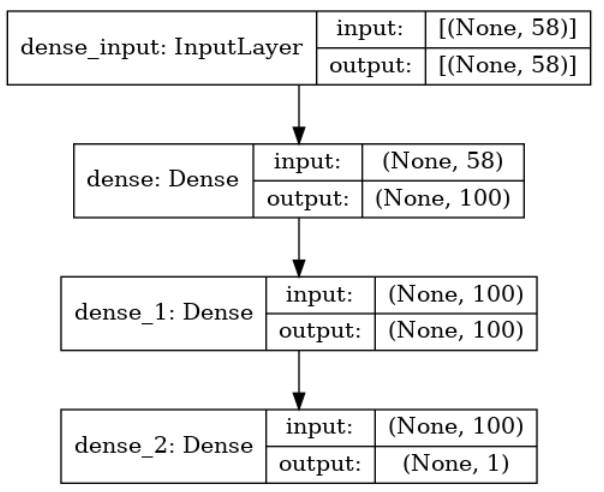
図3-10:モデルアーキテクチャ
モデルをKerasで実装します。次のようにモデルの定義を記述します。
def create_model(optimizer, units):
model = Sequential()
model.add(Dense(units, input_shape=[58], activation='relu'))
model.add(Dense(units, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
return model
データ変換の後続にモデルの学習を追加し、モデルの学習を実行します。学習時は前のステップでデータ変換を実施した「学習データ」を使います。
model = KerasClassifier(build_fn=create_model, optimizer='adam', units=100, epochs=25, batch_size=200, verbose=1)
model.fit(X_train_transformed, y_train)
predictions = model.predict(X_test_transformed)
モデルの学習結果の正解率を確認します。
accuracy_score(y_test, predictions)
(実行結果)
0.8530893010686648
「0.853089…」という数値が表示されたので、今回作成したモデルの正解率は85%ほどということになります。今回は正解率を使ってモデル評価を行いましたが、それ以外にもモデルを評価する指標は複数あり、本番環境でモデルを利用するには詳細な分析が必要です。本連載の次回以降では、このモデル評価に関しても解説を行う予定です。
ひとまず、今回はこのモデルを保存します。
model.model.save('example_model')
以上のように、Jupyter notebookを使うことによりデータの可視化や前処理、モデル学習をインタラクティブに進めていくことができます。このノートブックを上から流していくことでモデルの再学習なども可能ですが、すべてを手作業で実施する必要があり、その手間がかかることやエラーの原因にもなるため実運用には向きません。そこで、次回以降では、今回のハンズオンで解説したデータセットとモデルをベースにTensorFlow Extended(TFX)を使った機械学習パイプラインを構築してきます。
おわりに
今回は「Notebook Servers」を使った、Jupyter notebookの作成や機械学習モデルの開発の各ステップの概要の解説、Jupyter notebook上で機械学習モデルの作成を行いました。次回は、本稿で解説したデータセットとモデルをベースにTFXを使った機械学習パイプラインの構築について解説していきます。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
