機械学習モデル開発の各ステップの概要
機械学習モデル開発の各ステップの概要
本連載の第1回では、機械学習モデルの開発と運用における全体のワークフローと機械学習パイプラインの必要性を解説しました。今回と次回以降にわたり、その機械学習パイプラインのうち「機械学習モデルの開発」に焦点をあて、各ステップで実施する作業について解説します。
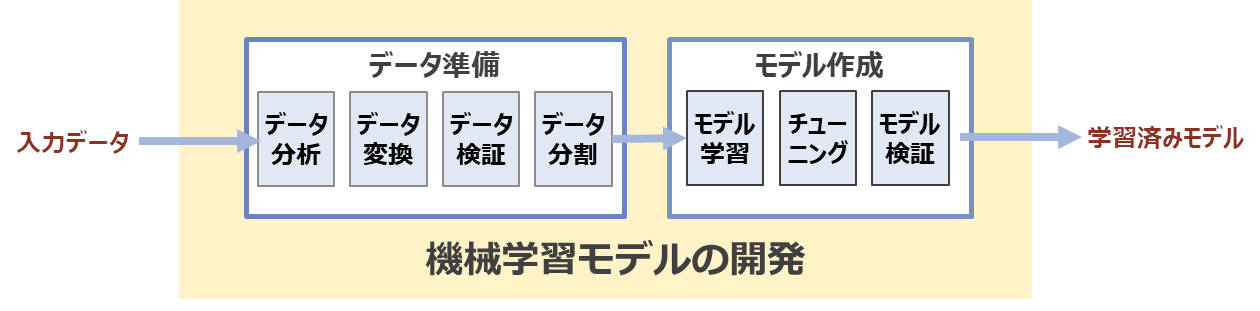
図2:機械学習モデルを作成するまでの流れとステップ
図2は、機械学習パイプラインのうち「機械学習モデルの開発」で実施する流れとそのステップを示しています。要約すると、まず「入力データ」を取り込むところから始まり、「データ準備」でデータを機械学習で使える形に変換し、「モデル作成」でモデル学習や評価を行い「学習済みモデル」を最終的な生成物として出力します。
各ステップの概要
「機械学習モデルの開発」のパイプラインは、主に「データ準備」と「モデル作成」で構成されますが、その中には次のようなステップが含まれています。
◆データ準備
・データ分析
「入力データ」がどのようになっているのかを確認します。このステップでは、データの各項目に対して集計、要約、可視化など行い、後続のデータ変換のステップで行うべきことを明確化します。この作業は探索的データ分析(Exploratory Data Analysis:EDA)と呼ばれ、「入力データ」の理解を深めたり、新しい「入力データ」に対してその変化を把握したりすることにも役に立ちます。
・データ変換
入力データはそのままではモデルの学習に使えません。データに含まれる欠損値・異常値・外れ値に対する処理や名寄せ(表記揺れなどを統一する)処理をしたり、値の取りうる幅の影響を受けないように変換したりといった前処理を行います。また、学習に使うデータは特徴ベクトルという各項目の値を数値化したもの (特徴量) をリスト化する必要があります。カテゴリー変数であれば、ダミー変数(one-hotベクトル、1つだけが「1」でそれ以外は「0」のベクトル)などに変換したり、テキストデータであれば、単語に分割して頻度を数えたりといった処理もこのステップに含まれます。
・データ検証
入力データやデータ変換済みのデータに対して、項目(スキーマ)や各項目の値が期待どおりであるかを確認します。入力データに対して行う検証では、欠損値や異常値の有無や統計量の確認などを実施します。また、新しいデータを取り込んで再学習する際には、前回のデータセットと比較してデータの内容が期待どおりであるかを確認します。データ変換済みのデータに対して行う検証は、スキーマや統計量がモデルを学習する要件を満たしているかを確認します。例えば、データ変換後の項目数やカテゴリー変数の分布、値の幅などで前処理ロジックの不具合がないかを確認することなどが挙げられます。
・データ分割
モデルの学習を行うための「学習データ」と学習済みのモデルに対して精度評価を行うための「検証データ」に分割します。「検証データ」は学習済みのモデルが「学習データ」に過度に適合 (過学習) していないかを計測するために用います。
◆モデル作成
・モデル学習
モデルの学習を行います。モデルの学習で利用するデータは「データ準備」の各ステップの処理を実施済みであることが前提となります。
・チューニング
モデルのハイパーパラメーターなどを調整し、モデル精度の改善を行います。この作業は次の「モデル検証」の精度評価と併せて実施していきます。探索するハイパーパラメーターの範囲や組み合わせが多い場合は、自動化すると効率良く実施できます。
・モデル検証
学習済みのモデルに対して「検証データ」を使ってモデルの検証を行います。検証には、適合率、再現率、AUCなどの指標での評価や、より詳細にモデルの検証を行う場合は、モデル分析を行うツールを利用し、多面的に確認していきます。
このようなステップを経て、ようやく「学習済みモデル」という生成物を出力することができます。
機械学習パイプラインを検討するタイミング
本連載では、機械学習モデルの実運用を行うための機械学習パイプラインの解説に重点を置いているため、上で述べた各ステップの概要はその文脈で解説しました。しかしながら、一般的に機械学習パイプラインを検討するタイミングは実運用を行うベースとなる「初期の機械学習モデル」を作成した後であることが多いでしょう。「初期の機械学習モデル」の開発においても、基本的にワークフロー内のステップは変わりませんが、次のような要素が加わります。※なお、「機械学習で解決する問題設定(ビジネス上の目的設定)」や「モデルの予測精度の目標策定」「データの収集」など、モデル開発に着手する前に必ず実施されるべきタスクは完了していることを前提とします。
- 機械学習モデルのアルゴリズムやモデルアーキテクチャの選定
- モデルの精度向上に効果がある特徴量の設計
- モデルチューニングの手法選定
これらの要素について本稿では取り上げませんが、一般的に「初期の機械学習モデル」の開発は試行錯誤が必要になります。例えば、モデルのアーキテクチャ選定においては実際に学習して評価した結果を確認しながらの検討が必要であったり、特徴量の設計もその特徴量を使って学習して評価した結果を確認し検討したりします。つまり、「初期の機械学習モデルの開発」では繰り返し都度(アドホック)に進めていくことが多いでしょう。したがって、定型化された機械学習パイプラインを構築する作業はその後になります。
次回以降に解説する予定の機械学習パイプラインの構築に関しては、この「初期の機械学習モデル」の開発は完了した前提ではじめます。本稿では、その前提となる「初期の機械学習モデル」の開発を想定して、利用するデータセットとモデルの解説も兼ねて、Jupyter notebook上で実際に操作しながら解説していきます。なお、上で述べた3つの要素については、すでに決まっていることを前提とします。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
