AIは実社会でどのように活用されているのか①ー音声認識(Speech to Text)
2021年12月8日 8:59
はじめに
これまで、ハイプ・サイクルをもとに最近のAI技術について解説してきました。今回からは、AIが社会でどのように実用化されているかを一緒に見ていきましょう。どの技術が実用化され、どの技術はまだまだという実態がわかると思います。
AIを適用した技術
図1はAIを適用した主な技術をまとめたものです。ここでは、要素技術とそれを利用した応用技術に分けていますが、実際はこんなにスパッと分類できるものでなく入り組んでいます。また、ここに挙げた技術以外にも多種多様なものが次々と生まれているので、1つの目安としてご覧ください。
今回と次回で、この中から最も実用化が進んでいる「音声認識」と「音声合成」を説明します。この2つは身近に溢れているので「知っているよ」という方も多いと思いますが、あらためて学習することで今後の可能性が見えてきます。まずは音声認識(Speech to Text)から見ていきましょう。
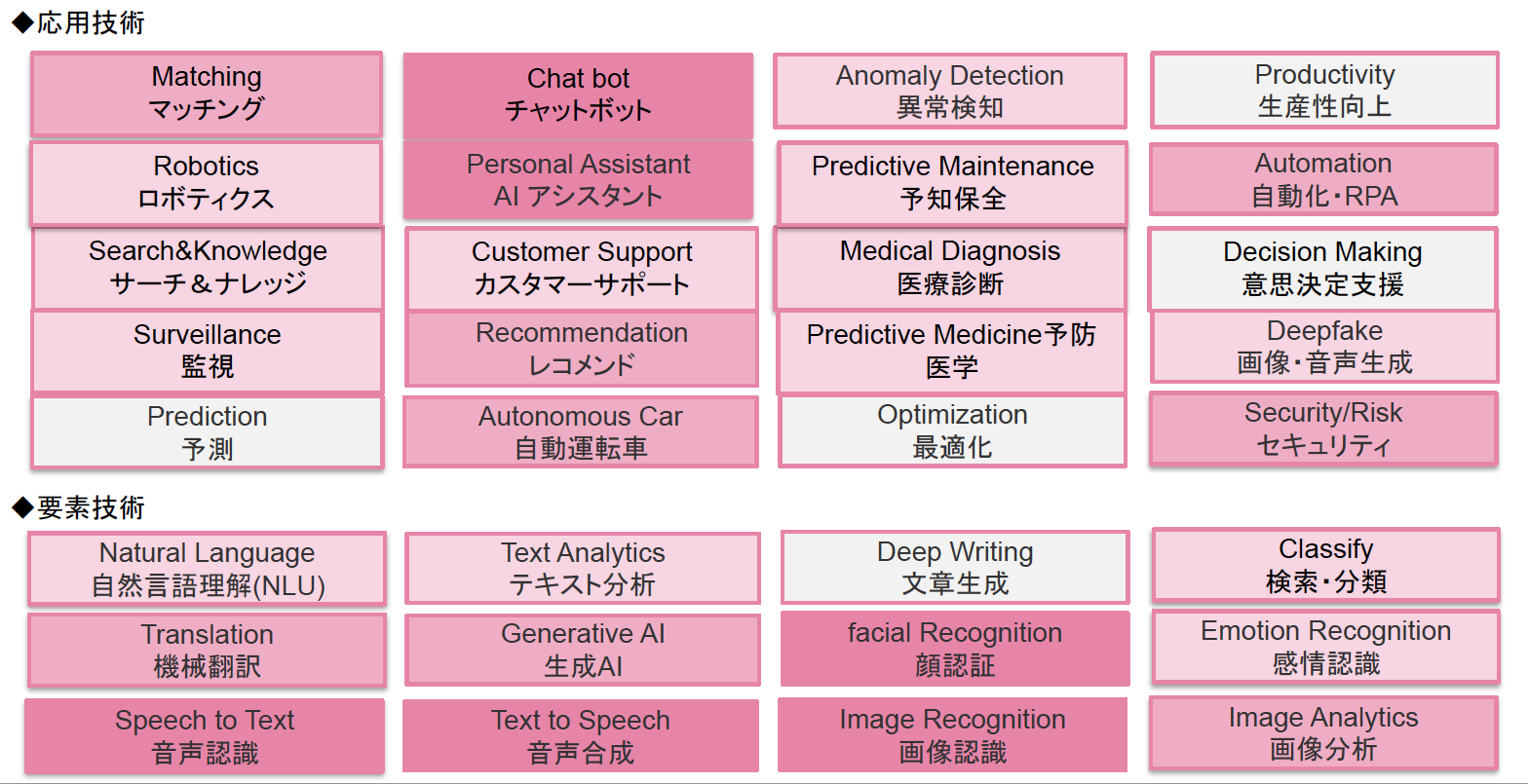
図1:AIを適用した主な技術
文章作成
音声認識の代表的な使い方は文字起こしや文章作成です。私は自宅ではChromebookを使っていて、ときどきGoogleドキュメントの音声入力を使って原稿を書いています。 音声認識の精度はこの数年でみるみる上がっており、ほとんど認識ミスがなく入力できます。
エンジニアは何ごとも試してみることが肝要なので、実際にGoogleドキュメントの音声入力の実力を試してみましょう。 ここではPCを使いますが、スマホのGoogleドキュメントでもOKです。またGoogleドキュメントは同時編集できるので、スマホで音声を入力し、PCでキー入力するという合わせ技も便利です。
- Googleドキュメント起動する
ChromeブラウザでGoogleドキュメントを起動してください。 - ツールから音声入力を起動する
上のメニューからツールを開いて音声入力を起動し、マイクへのアクセスを許可してください。 - 音声で文章を作成する
マイクをクリックしてオンにして、何かしゃべって文章を入力してください。
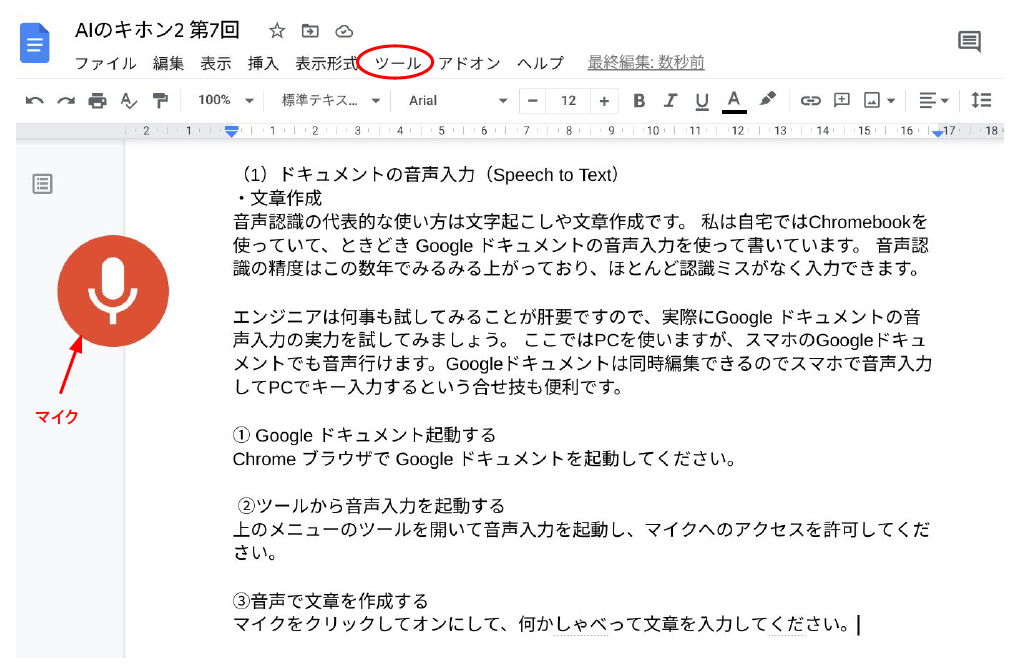
図2:Googleドキュメントの音声入力
図2の文章は実際に音声で入力したものです。数年前までは日本語で句読点が打てなかったのですが、今は「テン」や「マル」と言えば句読点も打ってくれます。ただし、テンをときどき10と変換してしまうので、句読点入力はもう少し待った方が良いかもしれません。また、英語ではVoice Commands(音声コマンド)でテキスト選択や編集など通常メニューにある処理をサポートしていますが、日本語はまだ対応していないため、現状では日本語の音声入力は、次のような使い方が効率的だと思います。
- 基本的に音声だけでなく、キーボードも併用して入力する。
- 句読点や改行、記号は、キーボードで入力する。
- 修正する場合は、キーボードで行う。
あとは、マイクのオン・オフが煩わしいのでタッチパネルだと便利です。我々エンジニアは高速に入力できるので、音声入力のありがたみは薄いかもしれませんが、キーボードに不慣れな人にはなかなか便利だと思います。ドキュメントエディタヘルプをみると、現在どこまで日本語をサポートしているかわかります。
音声UI
(1)スマートスピーカー
私が最初に音声UI(VUI)に触れたのはスマートスピーカーでした。Amazon Echoが日本で発売された際に購入し、続いて 発売されたGoogle Homeは別の部屋で使っています。日本語でも割とスムーズに音声認識や音声合成ができていて、音声ユーザーインターフェースの可能性を感じました。CUIからGUI、そしてVUIの時代が来たことに本当にわくわくしたのを覚えています。ただ、よく考えてみるとCUIとGUIが共存しているようにUIが多様化したということなんですね(図3)。
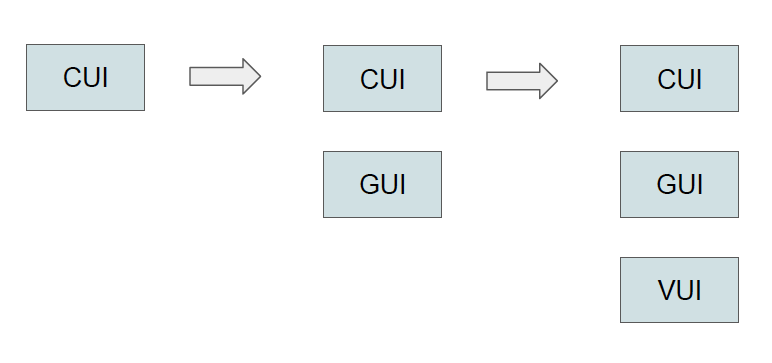
図3:UIの多様化
音声UIは、手が離せない、手が届かない、歩きながら、目を使えない、などの場面でとても便利です。寝ながら電気を消す、暗い部屋で電気を点ける、座ったままエアコンの温度を上げる、運転中にカーナビに呼びかける、歩きながらGoogleマップに行き先を告げるなど、音声UIの利点が活かせる場面で幅広く使われるようになりました。
ただ、テレビや冷蔵庫、掃除機、洗濯機など家電製品全般に対応が広がった中には、個人的に音声UIが本当に必要なのかと首を傾げるものもあります。リモコンとどちらが便利か競う局面なのでしょう。
(2)AIアシスタント
家電操作以外にも、音声UIは至るところで使われています。製造現場や医療現場の機器操作、カルテの入力、ホテルやオフィスの受付ロボット、家庭内のペットロボット、オフィスのAI秘書など、世界中でいろいろな応用がなされています。これらは技術的にみると、単なるチャットボットと自然言語処理を組み合わせたAIアシスタント/コミュニケーションAIに分けられます(図4)。

図4:音声UIの応用例
Amazon EchoはAlexa、Google HomeはGoogleアシスタントというAIアシスタントが入っています。iPhoneなどに搭載されているSiriも有名ですね。表に主なAIアシスタントを5つ示しましたが、このほかにもNTT docomoのmy daiz(マイデイズ)や、Yahoo!音声アシスト、SHARPのエモパーなどさまざまなアシスタントがあります。
しかし、iPhoneならSiri、Android端末ならGoogleアシスタントがキャリアに依存せずにデフォルトで使えるので、スマホではCortanaやBixbyも含めてこれらの独自AIアシスタントは苦戦している状況です。その中でAlexaだけはEchoやEchoを使った家電コントロールなどで健闘しています。
表:主なAIアシスタント
| AIアシスタント | 主な搭載機器 | 提供ベンダ |
|---|---|---|
| Alexa(アレクサ) | Amazon Echo | Amazon |
| Googleアシスタント | Google HomeやAndroid端末 | |
| Siri(シリ) | iPhoneやiPad、mac | Apple |
| Cortana(コルタナ) | Windows10、Microsoft365 | Microsoft |
| Bixby(ビクスビー) | Galaxyモバイルなど | Samsung |
(3)コミュニケーションAI
ロボット受付、ロボット執事、ペットロボットなどのコミュニケーションロボットは、基本的にはAIアシスタントにボディを付けた形です。スピーカーや携帯電話だけでなく、いろいろな場面で人間的な接客・コミュニケーションを行ってくれる存在として期待されています。ロボットやアバターなどを使うことによって親しみやすさを感じるだけでなく、聴覚だけでなく視覚や触覚などマルチモーダル技術で高度なコミュニケーションができる期待が高まっています。
ただし、ロボットはボディがあるぶん高価となり、話題性で導入されることは多いですが、まだそれほど普及しているとは言えない状況です。まだ自然言語理解が弱く、シナリオベースの会話となるので飽きられてしまうのでしょうか。誰もが知っているPepperも生産停止(販売は継続)しています。一方、ボディが必要なく特定の目的に特化したAI秘書、AIコンシェルジュ、AIオペレーターなどは、企業(総務)やホテル、コールセンター、電話案内などいろいろなところで使われ始めています。
最近、マルチモーダルAIという言葉をよく耳にします。あれ、モーダルという言葉、どこかで聞いたことありますね。モーダル(modal)は「モードの」という意味の形容詞です。エンジニアなら親ウィンドウの上に強制的に表示されるモーダルウィンドウを思い浮かべるでしょう。実は、これは「待ちモードのウィンドウ」という意味で、これを閉じないと親ウィンドウの操作ができないタイプですよってことだったのです。
マルチモーダルAIは、複数(マルチ)のデータを統合的に処理するAIのことです。人間はもともとマルチに情報を得て判断します。例えば卓球は相手の打った「球を見る」だけでなく、ラケットにあたった「音も聞いて」、どのコースにどれくらいの強さで来るかを予測してラケットを振ります。前にTVの実験で見たのですが、これ、音をずらすと一流選手でさえ空振りしてしまうのにびっくりしました。
人間のように複数のインプット情報を合わせて判断するのがマルチモーダルAIです。これまでは、視覚(画像)ならCNN(畳み込みニューラルネットワーク)、聴覚(音声認識)ならRNN(再帰型NN)というように個別の処理技術でした。これをマルチモーダルにして複数の情報を重ね合わせて、より高度な判断をするAIに進化させようと試みているのです。
(4)ボイスボット
「チャットボットはAIじゃない」として人工知能を「人工無能」と揶揄する人がいます。まあ、基本技術は「ああ言えば、こう言う」というシナリオタイプなのは事実です。でも、ボイスボットも音声認識は使っているので、全くAIじゃないってこともないでしょう。原理はGoogle検索をイメージするとわかりやすいです。入力された会話の中からキーワードを読み取ったり、何を質問しているかを推定して、蓄えている情報から一番ふさわしいと思われる回答をします。その際に音声合成AIが使われるタイプもあります。
サービスの価値はAIかどうかで変わるものでなく、実用的かどうかです。そういう意味では、ボイスボットはすでに全世界で広く普及している実績NO1の技術と言えます。
なお、図4では分けていましたが、AIアシスタントもボイスボットの一種で、基本技術にシナリオベースを使っているのも同じです。自然言語理解は徐々にチャットボットにも使われており、その垣根はなくなってきています。
アメリカや中国の方がAI技術の先端を進んでいること、英語に比べて日本語の方が処理が難しいこと、などにより会話や自然言語理解系AIの実用化はアメリカの方が進んでいます。例えば、音声入力で“ときどき”と書きたいのに、“時々”と入力されてしまうと、sometimesと言えばそのままsometimesと入力される英語はなんて楽なのだろうと思います。そういう意味では、中国語も漢字だけなので、ときどきを意味する“yǒushí”と発音すれば“有时”と入力されるので処理が楽そうです。
実際、Amazon EchoやGoogle Homeが日本で発売されたのもアメリカでかなり普及したあとですし、2018年に発表されたレストラン予約や映画のチケット購入、美容院の予約などを行ってくれるGoogle Duplexも日本では未発売です。
そんな中、日本語の難しさに敢然と挑んでいる企業もたくさんいて、英語に比べてハンディはありますが着々と後をついて行ってくれている感じがします。
おわりに
今回は音声認識を取り上げました。「キーボード VS 音声認識」「リモコン VS 音声認識」という戦いの構図において、なるほど音声認識の方が楽だと思える利用シーンから社会に浸透している様子がわかったと思います。もう3年、5年と経つうちには、もはやあらためて話題にする必要がないほど当たり前に使われていることでしょう。
次回は、音声認識よりも、さらに実用化が進んでいる「音声合成」を取り上げます。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
