チューニング
チューニング
ここまで、本連載の第3回で解説したモデルをベースにモデル学習のステップまで実装しました。しかし、性能の高いモデルを作成する上ではハイパーパラメータのチューニングが重要になります。ハイパーパラメータはモデルの種類により異なりますが、ディープラーニングモデルの場合は、主にオプティマイザーとネットワークアーキテクチャを制御するタイプのパラメータとなります。これらのパラメータを調整するプロセスは各パラメータの取り得る値の組み合わせを試行する必要があり、手動では骨が折れる作業です。TFXコンポーネントのTunerを使用しパイプラインに組み込むことで、このプロセスを自動化することができます。また、Tunerによって得られた結果を可視化し、最良のハイパーパラメータを特定するためのプロセスを支援するツールも提供されています。
- Tunerとは
Tunerはハイパーパラメータチューニングを行うTFXコンポーネントです。執筆時点(2022年1月)ではKeras Tunerをライブラリとして利用することができます。※CloudTunerというGoogle Cloud Platform上で利用できるライブラリもありますが、こちらもバックエンドにKerasTunerを利用しています。TunerではTrainerと同様に主に次の入力を必要とします。
- 前回「データ変換」のステップで実装したデータ変換処理のグラフ
- 前回「データ検証」のステップで生成したデータスキーマ
- 前回「データ分割」のステップで説明した学習用データと評価用データ
- 学習パラメータ(学習ステップ、エポック数など)
- ハイパーパラメータチューニングのプロセスを定義するtuner_fn関数を含むモジュールファイル
Tunerコンポーネントは与えられたデータおよびモデルを使用して、ハイパーパラメータを調整し最良の結果を出力します。
それでは、Tunerコンポーネントのエントリポイントである「tuner_fn関数」を実装します。なお、TunerもTrainerと同様にノートブック上で実行するとともにモジュールファイルとして書き出しを行います。
tuner_module_file_name = 'adult_income_tuner_module.py'
tuner_module_file_path = os.path.join(os.getcwd(), tuner_module_file_name)
次に「tuner_fn関数」を実装します。この関数では以下の処理を実装します。
- 学習用と評価用のデータの読み込み
- 利用するTunerの定義
- チューニングの過程を記録するログの設定
- 結果の返却
クリックして表示
%%writefile {tuner_module_file_path}
import kerastuner
import tensorflow as tf
import tensorflow_transform as tft
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, concatenate
from tfx.components.trainer.fn_args_utils import FnArgs
from tfx.components.tuner.component import TunerFnResult
import adult_income_trainer_module_without_tuning as tm
def create_model(hparams: kerastuner.HyperParameters):
model = Sequential()
inputs = []
for key in tm.NUMERIC_FEATURE_KEYS:
inputs.append(Input(shape=(1), name=tm.transformed_name(key)))
for key, dim in tm.ONE_HOT_FEATURES.items():
for i in range(0, dim):
inputs.append(Input(shape=(1), name=tm.transformed_name(key + '_' + str(i))))
outputs = concatenate(inputs)
units = hparams.get('units')
outputs = Dense(units, activation='relu')(outputs)
outputs = Dense(units, activation='relu')(outputs)
outputs = Dense(1, activation='sigmoid')(outputs)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=hparams.get('optimizer'), loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
return model
def tuner_fn(fn_args: FnArgs) -> TunerFnResult:
tuner = kerastuner.RandomSearch(
create_model,
max_trials = 10,
hyperparameters = get_hyperparameters(),
allow_new_entries = False,
objective = kerastuner.Objective('val_accuracy', 'max'),
directory = fn_args.working_dir,
project_name = 'census-income-tuner'
)
tf_transform_graph = tft.TFTransformOutput(fn_args.transform_graph_path)
train_dataset = tm.input_fn(fn_args.train_files, fn_args.data_accessor,
tf_transform_graph, 40)
eval_dataset = tm.input_fn(fn_args.eval_files, fn_args.data_accessor,
tf_transform_graph, 40)
tb_callback = tf.keras.callbacks.TensorBoard(
log_dir=fn_args.custom_config["tuner_log_dir"],
update_freq='batch')
return TunerFnResult(
tuner = tuner,
fit_kwargs = {
'x': train_dataset,
'validation_data': eval_dataset,
'steps_per_epoch': fn_args.train_steps,
'validation_steps': fn_args.eval_steps,
'callbacks': [tb_callback]
})
Tunerは以下の3種類の探索アルゴリズムを選択可能です。上記の例では、RandomSearchを選択しています。
- RandomSearch: 候補の値をランダムに組み合わせて探索します
- BayesianOptimization: ベイズ最適化アルゴリズムを使い探索します
- Hyperband: Hyperbandアルゴリズムを使い探索します
なお、目的とする評価指標は「val_accuracy」を指定しています。つまり、「評価用データに対する正解率」を最大化するハイパーパラメータを探索します。
次に「tuner_fn関数」に記述したヘルパー関数の「get_hyperparameters関数」を定義します。「get_hyperparameters関数」は探索するハイパーパラメータの値の種類、範囲を設定します。Keras TunerのHyperParametersクラスでは主に次のような設定ができます。
- HyperParameters.Boolean: True or Falseを設定します
- HyperParameters.Choice: 値の種類を設定します
- HyperParameters.Int: 整数型の値の範囲を設定します。Stepを指定することで均等分割できます
- HyperParameters.Float: 浮動小数点型の値の範囲を設定します。Stepを指定することで均等分割できます
ここでは、オプティマイザーとして「rmsprop」または「adam」、中間層のユニット数を100~250の範囲で50ずつ可変させながら探索します。
%%writefile -a {tuner_module_file_path}
def get_hyperparameters() -> kerastuner.HyperParameters:
hp = kerastuner.HyperParameters()
hp.Choice('optimizer', ['rmsprop', 'adam'], default='adam')
hp.Int('units', min_value=100, max_value=250, step=50)
return hp
ハイパーパラメータチューニングを実行します。
import tempfile
tuner_tensorboard_log_dir = tempfile.mkdtemp()
param_tuner_custom_config_args = {"tuner_log_dir": tuner_tensorboard_log_dir}
param_tuner_train_args = {"num_steps": 100}
param_tuner_eval_args = {"num_steps": 50}
tuner = tfx.components.Tuner(
examples = transform.outputs['transformed_examples'],
transform_graph = transform.outputs['transform_graph'],
schema = import_schema.outputs['result'],
module_file = tuner_module_file_path,
train_args = param_tuner_train_args,
eval_args = param_tuner_eval_args,
custom_config = param_tuner_custom_config_args
)
context.run(tuner)

図2-2:Tunerの実行結果
8回の試行を行い、最良のパラメータは次の通りになりました。
- オプティマイザー: adam
- 中間層のユニット数: 150
次にTunerの結果を可視化して、詳細に解析してみます。可視化することにより、ハイパーパラメータが結果に与える影響を直感的に把握できるようになります。可視化にはTensorBoardというTensorFlowエコシステムの可視化ツールを利用します。
TensorBoardを利用するには、クライアント端末上で次のコマンドの実行および、設定が必要です。
- クライアント端末で次のコマンドを実行
$ kubectl port-forward --address 0.0.0.0 example-notebook-0 6016:6016 -n anonymous - SSH クライアントのポートフォワーディングの設定に次を追加
ローカルのポート: 6016、リモート側ホスト:localhost、リモート側ポート: 6016
先ほど実施したTunerのログを読み込ませ、TensorBoardを起動します。
%load_ext tensorboard
%tensorboard --logdir {tuner_tensorboard_log_dir} --host 0.0.0.0 --port 6016
起動すると次のような画面がノートブックのセル内に表示されます。この画面では、各試行における損失曲線とメトリック曲線が表示されています。左ペインの操作パネルで可視化設定を切り替えることができます。
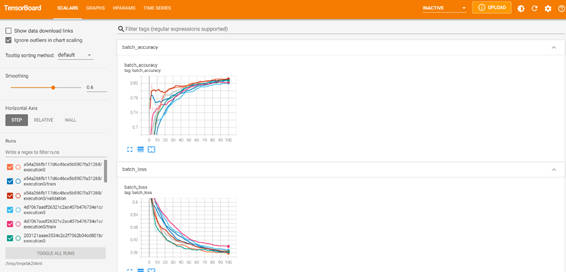
図2-3:TensorBoard-SCALARS画面
また、「GRAPHS」タブを選択すると、モデルグラフが表示されます。
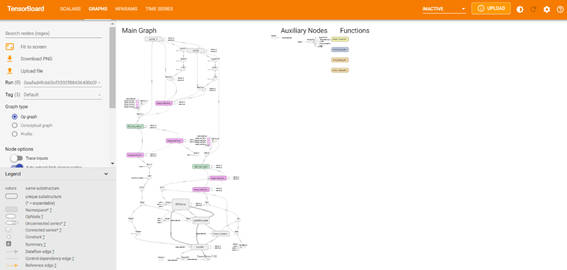
図2-4:TensorBoard-GRAPHS画面
モデルの構造の概念グラフを可視化してくれるため、意図した設計と一致しているかどうかを確認できます。左ペインの「Run」の設定で各試行におけるモデルグラフを切り替えることができます。
ここまでは、TensorBoardの一般的な機能となります。これら機能に加えてハイパーパラメータチューニング時は、その試行を可視化する「HParams」が追加されます。画面上部の「HPARAMS」タブを選択します。
この画面では次のような項目を確認できます。
・TABLE VIEW
試行ごとに設定したハイパーパラメータ値と評価指標を確認できます。
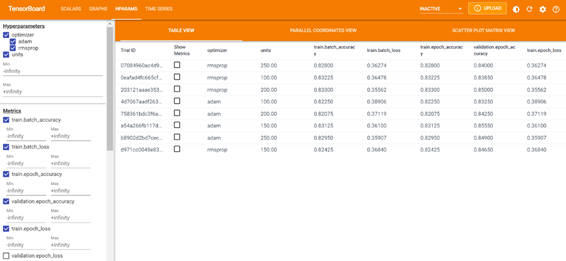
図2-5:TABLE VIEW画面
左ペインのパネルで特定のハイパーパラメータのフィルタを指定できます。例えば、オプティマイザーが「rmsprop」、ユニット数が150以上の試行のみを表示できます。

図2-6:TABLE VIEWフィルタ結果画面
・PARALLEL COORDINATES VIEW
平行座標ビューでは、色付きの各線は試行を示しています。軸はハイパーパラメータと評価指標です。
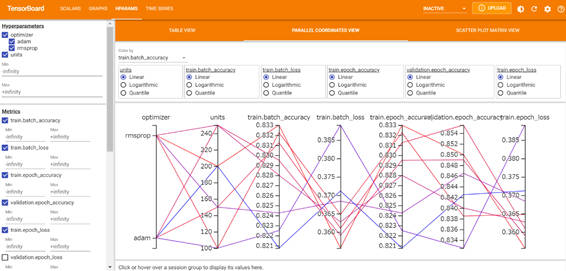
図2-7:PARALLEL COORDINATES VIEW画面
TABLE VIEWと同様に左ペインのパネルでフィルタが可能です。指標値を見やすくするために、左ペインの「Metrics」の表示項目を「validation.epoch_accuracy」のみ表示するよう選択します。例えば、今回の結果を考察してみると、オプティマイザーが「adam」かつユニット数が150の試行が最も指標の値が高いことがわかります。また、オプティマイザーが「adam」の時の試行が指標の結果が良いことも視覚的にわかります。
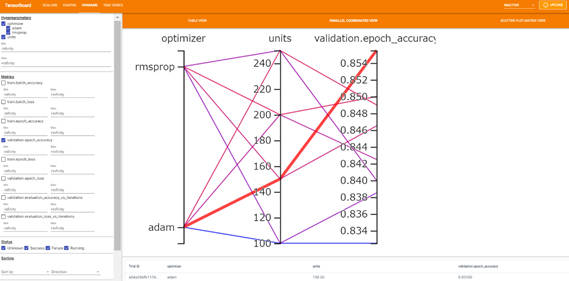
図2-8:PARALLEL COORDINATES VIEWフィルタ結果画面
・SCATTER PLOT MATRIX VIEW
散布図マトリックスビューでは、各ドットは試行を表します。プロットは、軸としてさまざまなハイパーパラメータとメトリクスを使用した平面での試行の投影となっています。ハイパーパラメータごとに試行結果の分布を把握できます。
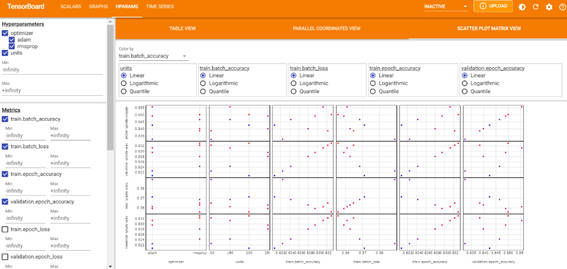
図2-9:SCATTER PLOT MATRIX VIEW画面
これら可視化した結果を確認して、ここではTunerコンポーネントを用いた試行で最良となった、オプティマイザー「adam」、中間層のユニット数「150」というハイパーパラメータを選定することにします。
・ハイパーパラメータを固定化して再度Trainerを実行
先ほど実施したTunerの結果で得られた最良のハイパーパラメータをモデル学習時に読み込めるようにImportTunerコンポーネントを使い、Trainerの入力として設定します。まず、固定化するパラメータ(Tunerの結果)をMinIOにアップロードします。
bucket.upload_file(os.path.join(tuner.outputs['best_hyperparameters'].get()[0].uri, 'best_hyperparameters.txt'),
'tuner/best_hyperparameters.txt')
ImportTunerコンポーネントを定義し、実行します。
import_tuner = tfx.dsl.Importer(
source_uri = '%s/tuner/' % bucket_name_s3_prefix,
artifact_type = tfx.types.standard_artifacts.HyperParameters).with_id('tuner_importer')
context.run(import_tuner)
図2-10:Import Tuner実行結果
TrainerコンポーネントでImportTunerを読み込むようにTrainerを再定義します。まずモジュールファイルを定義します。
trainer_module_file_name = 'adult_income_trainer_module.py'
trainer_module_file_path = os.path.join(os.getcwd(), trainer_module_file_name)
次に、チューニングして決定した最良のハイパーパラメータを受け取ってトレーニングをするために、Trainerコンポーネントで使用するモジュールファイルを更新します。
クリックして表示
%%writefile {trainer_module_file_path}
import absl
import os
import sys
from typing import List, Text
import kerastuner
import tensorflow as tf
import tensorflow_transform as tft
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, concatenate
from tfx.components.trainer.fn_args_utils import DataAccessor
from tfx.components.trainer.executor import TrainerFnArgs
from tfx_bsl.tfxio import dataset_options
NUMERIC_FEATURE_KEYS = [
'age',
'education-num',
'capital-gain',
'capital-loss',
'hours-per-week',
]
ONE_HOT_FEATURES = {'workclass': 8,
'education': 16,
'marital-status': 7,
'occupation': 14,
'relationship': 6,
'gender': 2
}
LABEL_KEY = 'income'
def transformed_name(key):
return key + '_xf'
def input_fn(file_pattern: List[Text],
data_accessor: DataAccessor,
tf_transform_output: tft.TFTransformOutput,
batch_size: int = 200) -> tf.data.Dataset:
return data_accessor.tf_dataset_factory(
file_pattern,
dataset_options.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=transformed_name(LABEL_KEY)),
tf_transform_output.transformed_metadata.schema)
def create_model(hparams: kerastuner.HyperParameters):
model = Sequential()
inputs = []
for key in NUMERIC_FEATURE_KEYS:
inputs.append(Input(shape=(1), name=transformed_name(key)))
for key, dim in ONE_HOT_FEATURES.items():
for i in range(0, dim):
inputs.append(Input(shape=(1), name=transformed_name(key + '_' + str(i))))
outputs = concatenate(inputs)
units = hparams.get('units')
outputs = Dense(units, activation='relu')(outputs)
outputs = Dense(units, activation='relu')(outputs)
outputs = Dense(1, activation='sigmoid')(outputs)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=hparams.get('optimizer'), loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
return model
def get_tf_examples_serving_signature(model, tf_transform_output):
model.tft_layer_inference = tf_transform_output.transform_features_layer()
@tf.function(input_signature=[
tf.TensorSpec(shape=[None], dtype=tf.string, name='examples')
])
def serve_tf_examples_fn(serialized_tf_example):
raw_feature_spec = tf_transform_output.raw_feature_spec()
raw_feature_spec.pop(LABEL_KEY)
raw_features = tf.io.parse_example(serialized_tf_example, raw_feature_spec)
transformed_features = model.tft_layer_inference(raw_features)
outputs = model(transformed_features)
return {'outputs': outputs}
return serve_tf_examples_fn
def get_transform_features_signature(model, tf_transform_output):
model.tft_layer_eval = tf_transform_output.transform_features_layer()
@tf.function(input_signature=[
tf.TensorSpec(shape=[None], dtype=tf.string, name='examples')
])
def transform_features_fn(serialized_tf_example):
raw_feature_spec = tf_transform_output.raw_feature_spec()
raw_features = tf.io.parse_example(serialized_tf_example, raw_feature_spec)
transformed_features = model.tft_layer_eval(raw_features)
return transformed_features
return transform_features_fn
def run_fn(fn_args: TrainerFnArgs):
tf_transform_output = tft.TFTransformOutput(fn_args.transform_output)
train_dataset = input_fn(fn_args.train_files, fn_args.data_accessor,
tf_transform_output, 40)
eval_dataset = input_fn(fn_args.eval_files, fn_args.data_accessor,
tf_transform_output, 40)
hparams = kerastuner.HyperParameters.from_config(fn_args.hyperparameters)
absl.logging.info('HyperParameters for training: %s' % hparams.get_config())
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir = fn_args.model_run_dir, update_freq='batch'
)
model = create_model(hparams)
model.fit(
train_dataset,
epochs = fn_args.custom_config["epoch"],
steps_per_epoch = fn_args.train_steps,
validation_data = eval_dataset,
validation_steps = fn_args.eval_steps,
callbacks = [tensorboard_callback]
)
signatures = {
'serving_default':
get_tf_examples_serving_signature(model, tf_transform_output),
'transform_features':
get_transform_features_signature(model, tf_transform_output),
}
model.save(fn_args.serving_model_dir, save_format='tf', signatures=signatures)
モジュールファイルをMinIOにアップロードします。
bucket.upload_file(trainer_module_file_path, 'module/%s' % trainer_module_file_name)
Trainerの入力としてhyperparametersを追加し、先ほど作成したモジュールファイルを使用してモデル学習を再実行します。
param_trainer_module_file = '%s/module/%s' % (bucket_name_s3_prefix, trainer_module_file_name)
trainer = tfx.components.Trainer(
module_file = param_trainer_module_file,
custom_executor_spec = executor_spec.ExecutorClassSpec(GenericExecutor),
examples = transform.outputs['transformed_examples'],
transform_graph = transform.outputs['transform_graph'],
schema = import_schema.outputs['result'],
hyperparameters = import_tuner.outputs['result'],
train_args = param_trainer_train_args,
eval_args = param_trainer_eval_args,
custom_config = param_trainer_custom_config_args)
context.run(trainer)
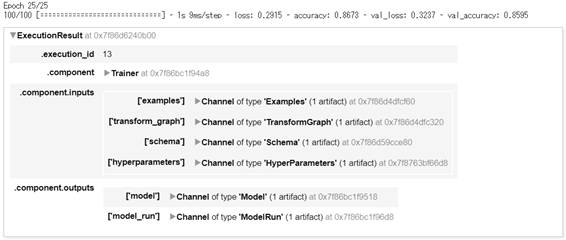
図2-11:チューニング後のTrainer実行結果
ハイパーパラメータチューニングを実施した結果、評価用データセットに対しての正解率(val_accuracy)が約86%に改善しました。
おわりに
今回はTFXの概要と機械学習パイプラインのうち「モデル作成」における、「モデル学習」と「チューニング」のステップについてTFXコンポーネントの解説と実装を行いました。次回は、実装編の最終回として、作成したモデルを評価しデプロイ可能なモデルとして出力するステップをパイプラインに組み込みます。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
