機械学習モデルの継続的な改善に向けて
機械学習モデルの継続的な改善に向けて
本連載ではここまで、機械学習モデルの開発と運用のパイプラインの構築とフィードバックループについて解説してきました。では、改めて全体をつなぎ合わせた実装イメージを見てみたいと思います。
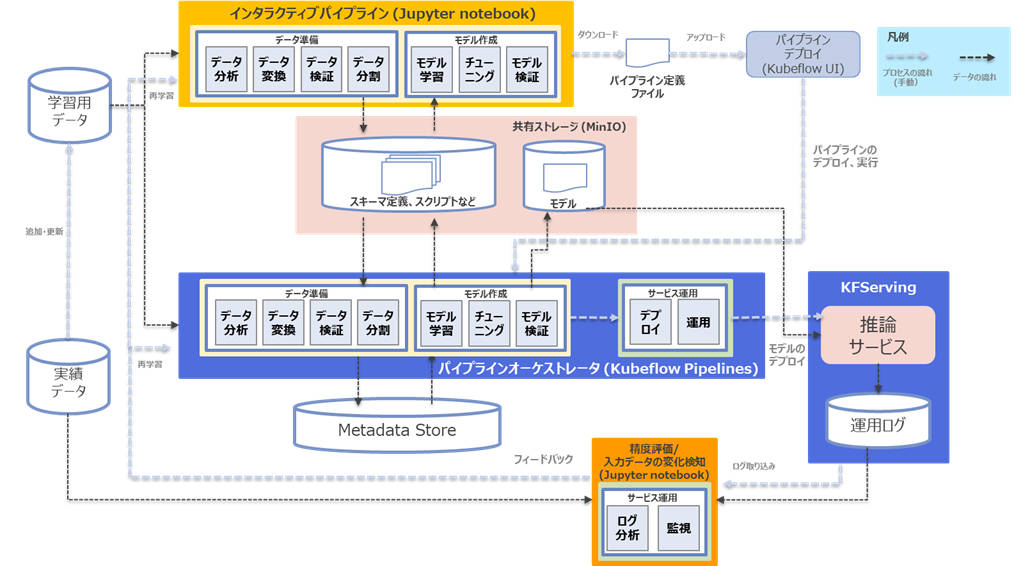
図2-1:全体の実装イメージ
図2-1で示すとおり、現状はパイプラインのデプロイや実行、モデルのデプロイ、フィードバックなどの各プロセスをつなぎ合わせる部分が手動になっています。効率よくサイクルを回すには、これらも自動化したいところです。この自動化に関して、GoogleはMLOpsの自動化レベルという段階的に実装する指針を定義しています。レベルが高くなるにつれ、機械学習に関するプロセスが自動化され、サイクルを早めることができます。
- レベル0 (手動プロセス):これは典型的なデータサイエンスプロセスであり、機械学習プロジェクトの開始時に実行されます。このレベルには、実験的で反復的な性質があります。データの準備と検証、モデルの学習とテストなど、各パイプラインのすべてのステップは手動で実行されます。処理する一般的な方法は、Jupyter notebookなどのツールを使用することです
- レベル1(機械学習パイプラインの自動化):モデル学習の自動実行が含まれます。ここでは、モデルの継続的な学習を実施します。新しいデータが利用可能になるたびに、モデルの再学習のプロセスがトリガーされます。このレベルの自動化には、データとモデルの検証手順も含まれます
- レベル2(CI/CDパイプラインの自動化):最終段階では、CI/CDシステムを導入して、本番環境で高速で信頼性の高い機械学習モデルのデプロイを実行します。前の手順との主な違いは、データ、機械学習モデル、および機械学習パイプラインのコンポーネントを自動的に構築、テスト、デプロイすることです
参考:機械学習における継続的デリバリーと自動化パイプライン(https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning#data_science_steps_for_ml)
現状の実装はレベル1に近い状態と言えるでしょう。では、最終的にレベル2を目指す場合に、どのような実装イメージになって追加でどのようなコンポーネントが必要なのでしょうか。上述のレベル2の定義を元にした実装例は次のとおりです。
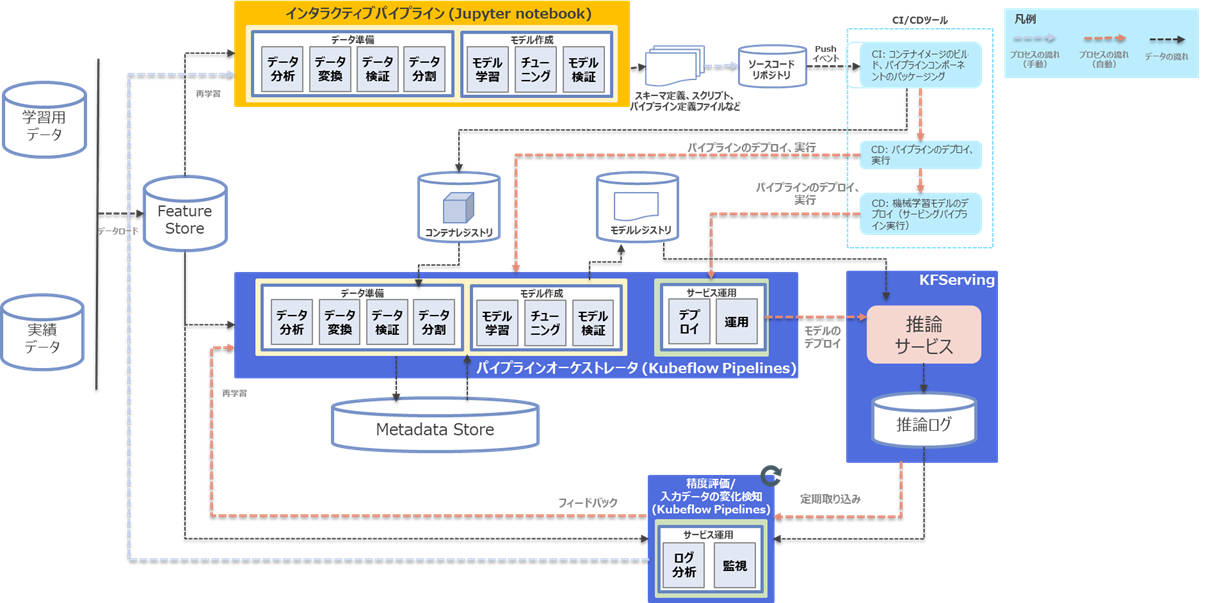
図2-2:レベル2(CI/CDパイプラインの自動化)の実装イメージ
図2-2に示すとおり、レベル2の実装例では各プロセスをつなぎ合わせる部分が自動化されています。また、いくつかコンポーネントが増えています。本番環境のモデルを迅速かつ確実にデプロイするために、堅牢で自動化されたCI/CDシステムや管理の仕組みが必要なためです。追加コンポーネント概要は次のとおりです。
追加コンポーネント
| コンポーネント | 説明 | プロダクト例 |
|---|---|---|
| CI/CDツール | ソフトウェアの変更をテストし、自動で本番環境に適用できるような状態にするためのツール | Jenkins、GitHub Actions、GitLab CI/CDなど |
| ソースコードリポジトリ | ソースコードのバージョン管理などができるツール | GitHub、GitLabなど |
| モデルレジストリ | モデルの登録、モデルのバージョン管理、デプロイ用のモデルのタグ付けなどの管理ができるツール | MLflowなど |
| コンテナレジストリ | コンテナイメージの登録・管理、提供するためのツール | Docker Registry、Harbor、GitLab Container Registryなど |
| Feature Store | 特徴量を一元管理し、特徴量を学習時と推論時で一貫して提供するためのストレージ | Feast、Hopsworks、Rasgoなど |
KubeflowはKubernetes上で動くため、その柔軟性や拡張性も特徴の一つとなっています。自社の機械学習モデルの活用状況にあわせて、段階的にコンポーネントを追加して、上述したレベル2を目指すことも可能です。レベル2を実装するための手順などは、また別の機会でご紹介できればと思っています。
Kubeflowと周辺コンポーネントの最新動向
本連載では、Kubeflow v1.2.0(※Kubeflow v1.2.0で内包されているKFServingはv0.4.1)、TFX v1.2.1をベースに解説してきました。執筆時点(2022/6/2)における、最新版での追加機能など主なトピックついて紹介します。
Kubeflow(最新版:v1.5.0)
・TensorBoardやVolume Manager、KServeの管理UIの追加
ノートブック上から作成したTensorBoardやKServe、ノートブックのVolume利用状況を確認するためにはコマンド実行が必要でしたが、Kubeflowコンポーネントとして管理UIが追加されたことにより、状況確認が画面上からできるようになり利便性が高くなりました。
・マルチユーザー対応
ML開発にあたりユーザーごとにKubeflow Notebook ServersやKubeflow Pipelinesを分離して使用できるので、他者に影響を与えることなく自身の作業に集中することができます。
・Feature Store(Feast)との連携
FeastはFeature Storeを実現するOSSです。Kubeflow Pipelinesにてモデル作成を行い、そのパイプラインにてFeastによる特徴量の管理を組み込むことで、特徴量の一元管理や再利用ができるようになります。
KFServing(最新版:v0.8.0)
・KServeにプロダクト名を変更
KFServingは本番環境での機械学習モデルのデプロイと監視の課題に対処するために開発されたOSSです。元々はKubeflow内の一部のプロジェクトとして開発していましたが、需要が急増してプロジェクトの範囲が拡大したことから、Kubeflowから独立してリブランドとしてプロダクト名を変更しました。これによりKubeflow未使用ユーザーからでも利用しやすいイメージを持ってもらうことで、より利用ユーザーを増やす狙いがあると考えられます。
TensorFlow Extended(最新版:v1.8.0)
・Vertex AIとの連携
Vertex AIはGoogle Cloudの機械学習関連のサービスを統合したプラットフォームです。Kubeflow Pipelinesと同じようにVertex AI PipelineでもTFXによるパイプライン構築が実現できます。
おわりに
本連載ではKubernetes上で動く機械学習プラットフォームKubeflowで実現するMLOpsについて取り上げ、構築手順などを全9回にわたり解説してきました。機械学習モデルを実運用してビジネス上の成果を得るには、機械学習モデルの開発と運用のワークフローを効率よく回して継続的に改善することがカギになると考えています。また、KubeflowはJupyter notebook上でのモデル開発や検証から実運用へシームレスに移行できることも特徴の一つです。本連載で解説してきた内容が、サブタイトルにもあるような「実運用へのファストパス」の一助になれば幸いです。さいごに、本連載ではKubeflow、TFXといったOSSで実現する機械学習プラットフォームをご紹介しましたが、パブリッククラウドのサービスやサードパーティベンダによるソリューション・製品も多く登場しています。弊社では、OSSベースのプラットフォームに関する技術支援の他にも、DataikuというAI/機械学習プラットフォームを取り扱っております。もしもプラットフォームの選定などでお困りのことがありましたら、お気軽にお声がけ下さい。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
