| ||||||||||||
| 前のページ 1 2 3 4 | ||||||||||||
| パーティションテーブルに対するSQL処理 | ||||||||||||
SQLの対象テーブルがパーティションテーブルの場合、レプリケーションテーブルに比べて少し処理が複雑になります。パーティションテーブルに対するクエリの処理は、パーティションの構成によって変化します。 次の図5の状況を例として考えてみます。 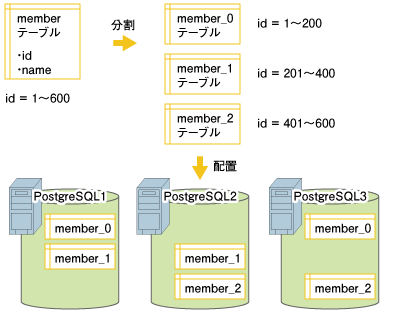 図5:パーティションテーブルの分割と配置 この例では「id」と「name」の2つのカラムを持つ「member」テーブルをパーティション化しています。レコードのidの値によって、3つのパーティションのどれかに格納されるように分割しています。そして分割したパーティションを、PostgreSQLサーバごとに2つずつ配置しています。 なお、PostgresForestとしては「パーティション」という呼び方になりますが、PostgreSQLサーバ内には「テーブル」として記録されます。 | ||||||||||||
| パーティションテーブルを更新する場合は? | ||||||||||||
更新SQLを受け取った場合、SQL中のテーブル名を書き換えた上で、必要あるサーバのみにSQLを振りわけます。 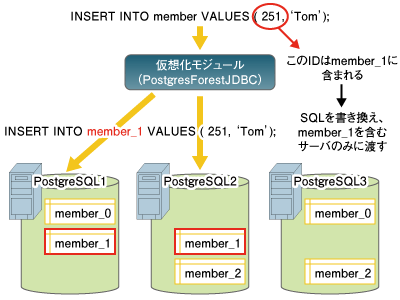 図6:パーティションテーブルを更新する場合の処理 例えば図6のINSERT文を処理する場合、idカラムの値からどのパーティションに対して挿入するべきかがわかります。というのもGSCの中に、このテーブルはidカラムの値によってどういった形に分割されているのか、という情報があるためです。 そこで、SQLのテーブル名を対象となるパーティションの名前に書き換え、なおかつそのパーティションが存在しているPostgreSQLサーバのみにSQLを引き渡します。 | ||||||||||||
| パーティションテーブルを参照する場合は? | ||||||||||||
続いて参照SQLを受け取った時の動きをみてみます。 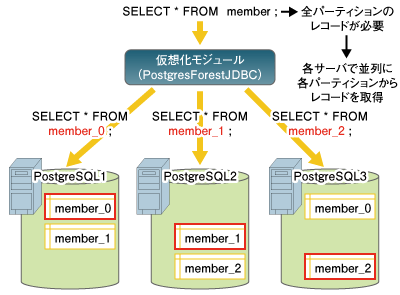 図7:パーティションテーブルを参照する場合の処理 図7の例では、SQLはテーブル中のすべてのレコードを必要とします。テーブルの内容は3つのパーティションに分割されているので、各パーティションそれぞれから全レコードを取得するようにSQLを書き換えます。 そしてこれらのSQLを3つのPostgreSQLサーバに振りわけることで、元々の参照SQLは1つなのにもかかわらず、全PostgreSQLサーバで並列に処理を進めることができ、負荷の分散と応答時間の短縮といった効果を期待することができます。 | ||||||||||||
| 次回は | ||||||||||||
今回はPostgresForestがどのような仕組みで動いているのかを解説しました。 次回は実際にPostgresForestを動かして、負荷分散や障害検出を行うする様子について紹介します。 | ||||||||||||
| 前のページ 1 2 3 4 | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30