| ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| PostgresForestはどのように動くのか | ||||||||||||
ここからは、ユーザが作ったアプリケーションがPostgresForestにアクセスした際、どのようなことが起きるのかを順を追ってみていきたいと思います。 次のように、ユーザのJavaアプリケーションからJDBCアクセスを開始します。JDBCへの接続方法の詳細に興味のある方は「PostgresForest4.0 開発者ガイド」をご覧ください。 PostgresForest4.0 開発者ガイド http://sourceforge.jp/projects/postgresforest/ document/developers_guide.html/ja/1/developers_guide.html Class.forName("org.postgresforest.Driver");この時、JDBCドライバは最初にGSCに接続し、GSCに格納してあるPostgresForestの構成などに関する情報を取り出します。続いて、実際に接続するユーザデータベースの場所をGSCの情報から取り出し、そのデータベースに接続します。 GSCやユーザデータベースに対するコネクションは、アプリケーションがJDBCへの接続を終了するまでそのまま存在し続け、SQLを発行するたびにこのコネクションを通して処理を行います。 続いてこのコネクションに対してSQLを発行します。 stmt = con.createStatement();この時JDBCドライバが行う処理の概要は次のようになります。 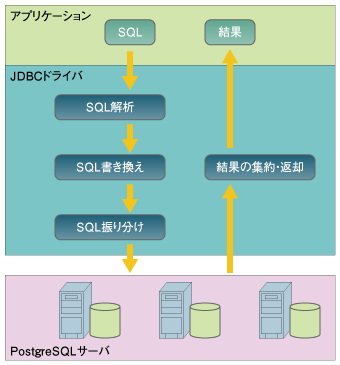 図2:PostgresForestの処理の流れ | ||||||||||||
| 1.与えられたSQLを解析 | ||||||||||||
SQLが参照系なのか更新系なのか、対象となるテーブルがレプリケーション構成なのか、パーティション構成なのか、あるいはwhere句にどんな条件がついているのか、といったことを解析し、この情報を基に以降の処理を行います。 | ||||||||||||
| 2.SQLの書き換え | ||||||||||||
PostgresForestはPostgreSQLサーバに対して、ユーザから与えられたSQLをそのまま発行するとは限りません。これは、高速化や負荷分散のためにユーザ指定とは異なるテーブルにレコードが格納されている場合があるためです。具体的にはパーティションテーブルを使っている場合がこれにあたります。 そのため、必要に応じてユーザから与えられたSQL中のテーブル名を書き換える処理を、この段階で行います。 | ||||||||||||
| 3.SQLの振り分け | ||||||||||||
2で書き換えられたSQLを、どのPostgreSQLサーバに送るべきかを判断して、振り分けを行います。すべてのPostgreSQLサーバに振りわけることもあれば、1つのPostgreSQLサーバのみに振りわけることもあります。 | ||||||||||||
| 4.SQLの結果を収集してユーザアプリケーションに返却 | ||||||||||||
3で問い合わせたSQLの結果を集めて、ユーザアプリケーションに返却します。 すべてのSQLに対してこの一連の処理を繰り返すことで、PostgresForestが動作しているわけです。 | ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30