コマンドを並列実行して効率アップ!「GNU Parallel」を使いこなそう
第26回の今回は、シーケンシャルな処理を並列化してハードウェアのリソースを効率的に使えるようにする「GNU Parallel」について解説します。
2月24日 6:30
はじめに
本連載では、過去にLinuxの基礎コマンド群や現代的なコマンドなど、様々なCLIツールを紹介してきました。WSLを使う大きな動機の1つが、強力なLinuxのコマンドをWindows上でシームレスに動かせることです。CLIツールを使いこなせば、複雑な処理の自動化や大量のデータの一括処理の効率を飛躍的に向上させられます。
しかし、処理をシーケンシャルに行っていると、どうしてもある所で速度は頭打ちになってしまいます。そこで登場するのが「並列化」です。今回はジョブ(コマンドやスクリプト)を並列実行するためのツール「GNU Parallel」の使いこなし方を解説します。
GNU Parallelとは
Linuxのシェルではループ構文を用いて大量のデータ処理を自動化できますが、愚直にループを回すだけだとデータは1つずつ、シーケンシャルに処理されることになります。1度に1つの処理しか行わないのであれば、現代的なマルチコアCPUを活かせず、効率化も早々に頭打ちとなってしまうでしょう。この問題を解決するには、ジョブを適度な粒度で分割し並列実行するしかありません。
冒頭で述べた通り、GNU Parallelは「同じコマンドを複数の入力に対して並列実行するツール」です。その真価は大量に繰り返すタイプの処理を、安全に高速化する場面で発揮されます。forやxargsコマンドをparallelに置き換えることで、CPUコアやI/O帯域を効率良く使って処理を高速化できます。またGNU parallelは並列実行した各ジョブの出力が混ざらないよう制御されるため、逐次実行時と同様に他のコマンドへパイプで渡せます。
GNU Parallelのインストール
UbuntuにGNU Parallelはプリインストールされていません。以下のコマンドでparallelパッケージをインストールしてください。
$ sudo apt install -U -y parallelGNU Parallelの基本的な使い方
GNU Parallelの基本的な使い方を簡単に解説します。
まずファイル名や数値、文字列のリストなど、複数の入力を列挙します。Parallelはこれらにコマンドを適用し、それを複数並列に実行します。一般的なプログラミング言語で言う「イテレータ」が良い感じに処理を並列化してくれるようなものだと考えると良いでしょう。
基本的な構文は以下の通りです。
parallel コマンド ::: 引数1 引数2 引数3 (..略..)例として、以下のコマンドを実行してみましょう。
$ parallel echo ::: A B C実行するコマンドは「echo」で、引数として「A」「B」「C」を取る3パターンを並列実行するという意味になります。そのため、出力は以下の通りとなります。
A
B
Cこれは以下のコマンドを実行したのと同じことですが、3つのechoコマンドが順次実行されているわけではなく、内部的には並列に実行されています。
$ echo A
$ echo B
$ echo CGNU Parallelの具体的な活用シーン
それでは、現実の運用で「これは効く」という利用シーンを具体例とともに紹介していきましょう。
大量ファイルの一括処理
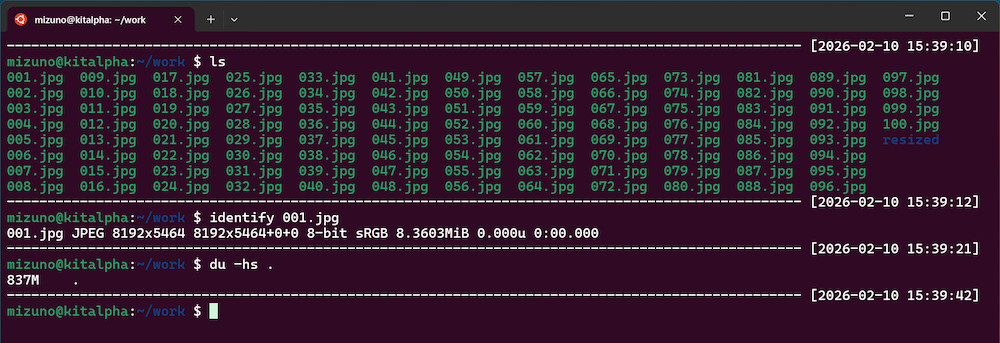
まずは「大量ファイルの一括変換」です。convertコマンドでJPEG画像のリサイズを行ってみましょう。ここでは、例として8Kの写真を100枚用意しました。すべての写真を横幅1920ピクセルに縮小してみます。
普通に変換しようとすると、以下のようにforループを使うことになるでしょう。
$ for file in *.jpg
do
convert -resize 1920 $file resized/$file
done実行し、かかった時間を計測してみました。筆者の環境では約43秒でした。

これをGNU Parallelで並列化すると以下のように書き換えられます。lsコマンドでファイルのリストを作成し、パイプを使ってparallelに渡しています。「-j」オプションは並列数です。8コアのCPUを搭載した環境のため8を指定しています。「{}」は特殊な置換記号で、入力値そのもの(ここではパイプで渡されたファイル名)に置き換わります。また「{/}」はファイル名からディレクトリ名を取り除いたもの(basename)に置き換わります。
$ ls *jpg | parallel -j 8 'convert -resize 1920 {} resized/{/}'実行してみた結果は下図の通りです。かかった時間は約18秒で、forループに比べて2倍以上も高速化できました。

大量データ生成
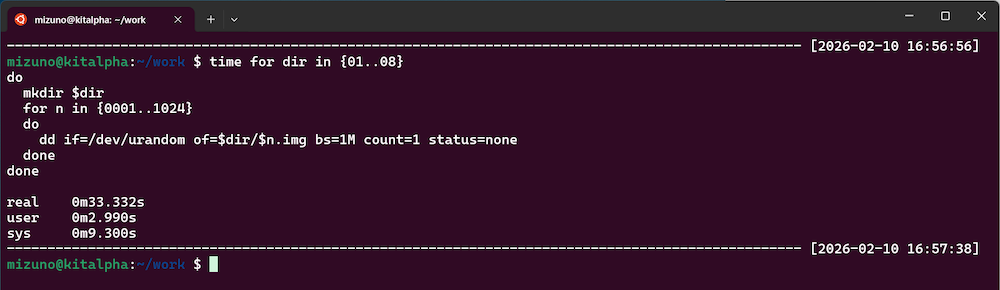
テスト目的などで大量のダミーデータを生成したいことがあります。例として01〜08まで8個のディレクトリを作成し、それぞれの中に1MBのランダムなダミーファイルを1,024個作成してみましょう。つまり合計で8,192個、8GiBのダミーデータを生成します。
forループで作ろうとすると、ディレクトリ8個とファイル1,024個の二重ループになるでしょう。
$ for dir in {01..08}
do
mkdir $dir
for n in {0001..1024}
do
dd if=/dev/urandom of=$dir/$n.img bs=1M count=1 status=none
done
done実行結果としては約33秒かかりました。
これもGNU Parallelで並列化してみましょう。ファイルを生成する1,024回のループはそのままに、外側のディレクトリごとのループ単位で8並列化します。
$ parallel 'mkdir {}; for n in {0001..1024}; do dd if=/dev/urandom of={}/$n.img bs=1M count=1 status=none; done' ::: {01..08}結果は4秒で単純に8倍に高速化できました。このように適した粒度で並列化でき、かつリソースに余力があれば、ほぼリニアに性能は向上します。

複数サーバーへのコマンド同時投入
サーバーの管理を行っていると、複数のサーバーに同じ処理を行いたいことがあります。こういう作業のときは並列化の出番です。まず、対象サーバーのIPアドレスを1行ごとに列挙した「hosts」というファイルを用意しました。ここではLAN内にある3台のサーバーを対象とします。
192.168.1.160
192.168.1.244
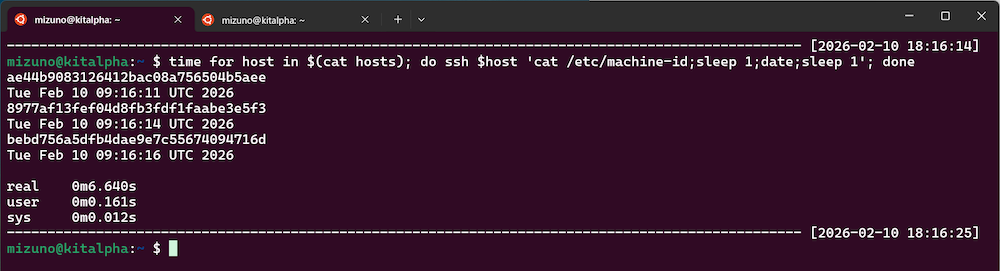
192.168.1.248forループを使って各サーバーにコマンドを投入する例が以下になります。ここでは「各サーバーのマシンIDを出力」→「1秒スリープ」→「現在時刻を出力」→「1秒スリープ」というコマンドを投入しています。
$ for host in $(cat hosts)
do
ssh $host 'cat /etc/machine-id;sleep 1;date;sleep 1'
done実行結果は下図の通りです。
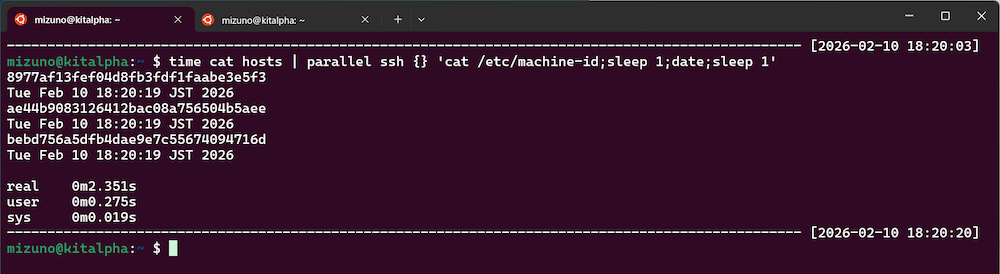
これも以下のように並列化しました。3台のサーバーに同時にSSHセッションを張り、コマンドを投入しています。
$ cat hosts | parallel ssh {} 'cat /etc/machine-id;sleep 1;date;sleep 1'当然ながら並列実行されるため、実行時間は2秒に短縮されました。
物理的に異なるサーバーが複数並んでいるなら、こうした処理を1台ずつ順番に行うのは時間の無駄です。複数サーバーの管理は、まさに並列化が一番輝くシーンの1つだと言えるでしょう。
GNU Parallelが効かない例
リモートサーバーへ大量のファイルをコピーする際によく使われるコマンドが「rsync」ですが、回線が十分に高速な場合に単発のrsyncではウィンドウサイズや輻輳制御の都合上、どこかで頭打ちとなってしまい、回線の帯域幅を十分に使い切れないケースがあります。また暗号化処理がCPUの1コアに寄ってしまうため、マルチコアCPUの恩恵も受けられません。rsyncの特徴は差分転送ですが、その差分計算処理がシングルスレッド寄りなこともパフォーマンスを十分に出せない理由となります。そこで送信するデータを適宜分割し、並列処理することでパフォーマンスが向上するか確認してみましょう。
先ほど作成した8GiBのダミーデータをLAN内の別のサーバーへコピーしてみると、単発のrsyncの場合、以下のようになります(作成した01..08のディレクトリがカレントディレクトリにある想定です)。
$ rsync -a . (送信先のIPアドレス):(送信先のディレクトリ)結果としては約30秒かかりました。

続いて、こちらも並列化します。先ほどと同様にディレクトリ単位で8並列化してみましょう。
$ parallel 'rsync -a ./{} (送信先のIPアドレス):(送信先のディレクトリ)' ::: {01..08}
8倍に高速化できるかと思いきや、なんと29秒で結果はほぼ同一でした。これは一体どういうことでしょうか。
そもそもParallelで性能が向上するのは、「シングルスレッドでは性能を使い切れない状況でも並列化すればリソースを効率良く使える」からです。実はこの環境では、単発のrsyncの時点でネットワークの帯域をほぼ100%使い切ってしまっている状態でした。そのため、どれだけ並列化してもハードウェアの限界に突き当たってしまっている以上、性能は向上しないというわけです。
なお誤解しないでいただきたいのは「rsyncの並列化は意味がない」というわけではありません。100Gbpsの超高速回線で繋がったサーバー間で同様のテストを行ってみたところ、単体のrsyncが500Mbps程度で頭打ちとなり、帯域を有効活用できていませんでした。そのため、このケースでは並列化により大幅にスピードアップできました。大切なのは、使い切れていないリソースがあるのか、それを並列化で解消できるのかを判断することです。
おわりに
GNU Parallelを使えば、いままでシーケンシャルに実行していた処理を並列化し、ハードウェアのリソースをより効率的に使えるようになります。今まで単純にコマンドを羅列したり、シンプルなforループだけしか使っていなかったという方は、ぜひGNU Parallelを活用してみてください。ちょっとした工夫で作業効率が大幅な向上も期待できます。
ただし、何でもかんでも並列化すれば良いというものでもありません。リソースの使用状況を把握し、並列化する意味があるかを見極めることも大切です。
この記事をシェアしてください
関連記事
コマンド1行で作業を劇的に効率化! 今日から使える「ワンライナー」集
4月7日 6:30
現代的なLinuxコマンドを活用して、WSL環境をもっと快適にしてみよう
2025年9月9日 6:47
Ansible:さらにPlaybookをきわめる
2016年7月12日 11:00
ターミナルマルチプレクサの「Byobu」を導入して、WSLのターミナル生活をさらに快適にしよう
2025年6月17日 6:30
WSLでUbuntuの最新LTSリリース「Ubuntu 26.04 LTS」を動かしてみよう
5月14日 6:30
「WSL」を使って、話題の生成AI「Ollama」をWindowsで簡単に動かしてみよう
2025年7月8日 6:30
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
