| ||||||||||
| 前のページ 1 2 3 | ||||||||||
| 日付処理を高速化する「Date(DATE)」「Date Time(DTTM)」「Time(TIME)」 | ||||||||||
時間・日付専用のインデックスとして、Dateインデックス、DateTimeインデックス、Timeインデックスの3つがあります。これらは、それぞれdate型、datetime型、time型のカラムに設定することにより、高速な範囲検索機能を提供します。また、年、月、日、時、分、秒、曜日、四半期などの日付時間の部分取り出しも高速化します。 | ||||||||||
| 用途別インデックスのメリット | ||||||||||
Sybase IQのビットワイズインデックスは、情報系分析アプリケーションに多用されるジョイン、日付検索、集約処理などに対して専用のインデックスを提供しています。このため、「どのカラムがどのように使わるか」という点さえ押さえておけば、インデックスチューニングが非常に明確で、容易であるというメリットがあります。 また、カラムの使われ方がわかれば、チューニングが容易、ということは、テーブル設計の段階、つまりハードウェアが用意されていない、もちろん、物理的なデータベースも構築されていない段階で、ある程度のパフォーマンス的な見通しを立てやすいことを意味し、システム開発の早い段階でサイジングに対する見通しを立てることも可能となります。 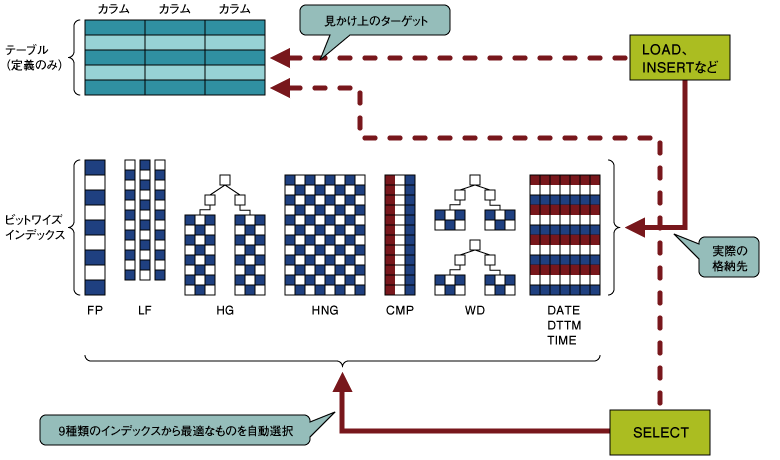 図5:用途別インデックス (画像をクリックすると別ウィンドウに拡大図を表示します) 一方、Sybase IQはインデックスとアクセス方法が独特であるため、使いづらいのではないか、覚えるのが大変なのではないか、といった心配を感じるかもしれません。しかし、Sybase IQを使用する上で、ビットワイズインデックスを意識するのはテーブルを定義するときだけで、あとはすべてIQエンジンが自動的に行ってくれます。 例えば、データを登録するときは、テーブル名を指定するのみで、インデックスを意識する必要はありませんし、データを参照するときは、最適なインデックスをIQエンジンが自動的に選んでくれます。 ビットワイズインデックスがデータの実体であるとすれば、その上にテーブルというビューがあり、登録や検索はこのビューに対してだけ行えばよい、と理解すれば、使い勝手は汎用RDBMSと何ら変わることがないことをご理解いただけると思います。 | ||||||||||
| データ圧縮 | ||||||||||
インデックス化されたデータ(ビットワイズインデックスそのもの)は、複数のブロックに分割された後、すべて圧縮されてからディスク上のデータベース領域に書き込まれます。 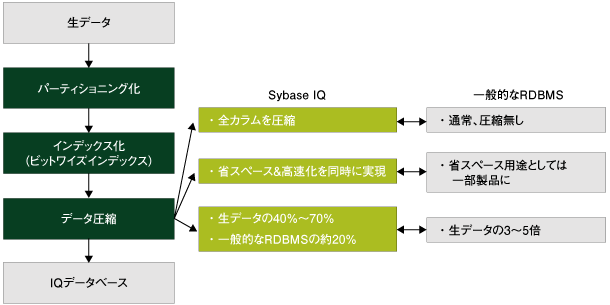 図6:データ圧縮のプロセス (画像をクリックすると別ウィンドウに拡大図を表示します) 通常、データの圧縮はリソース消費を抑えるために行われますが、Sybase IQの場合は処理の高速化のための実装でもあります。 例えば、ネット経由で巨大なファイルをダウンロードする場合、そのままダウンロードするよりも、圧縮ファイルをダウンロードした後にローカルのPCで解凍した方が時間的に早いことは経験上ご理解いただけると思います。これは、低速なネットワークで転送する時間よりも高速なメモリ上で解凍する時間が遥かに短いからです。 同様に、Sybase IQにおいても、大量のデータであればそのままの状態を低速なディスクから読み出すよりも、圧縮によりディスクI/Oを減らして高速なメモリ上で解凍する方が速いわけです。もちろん、領域節約の効果も期待でき、一般的なRDBMSの20%程度の領域で同じデータを格納することができます。 | ||||||||||
| 次回は | ||||||||||
さて最終回の次回は、Sybase IQのロード性能の比較とその他の機能について紹介します。 | ||||||||||
| 前のページ 1 2 3 | ||||||||||
技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」 本連載はサイベースが提供している技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」の転載となります。Sybase IQのより詳細な内容については以下のページを参照してください。 http://www.sybase.jp/products/informationmanagement/sybaseIQ_moreInfo.html | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30