| ||||||||||
| 前のページ 1 2 3 | ||||||||||
| クラスタのサポート | ||||||||||
JBoss Enterprise Application Platform(以下、JBoss EAP)に搭載されているJMSサーバを使って、クラスタ環境でHibernate Searchアプリケーションを実行することができる。 Hibernate SearchのノードはMasterとSlaveに分けられる。MasterはJMSキューからインデックス更新処理リクエストを取得し、Masterの検索インデックスを更新する。更新されたインデックスはSlaveノードの検索インデックスにコピーする(cpコマンドやrsyncなどを使ってコピーする)。そしてSlaveはSlaveの検索インデックスを使って検索処理を行う。なお、検索インデックスの更新リクエストはSlaveがJMSキューに投入する。 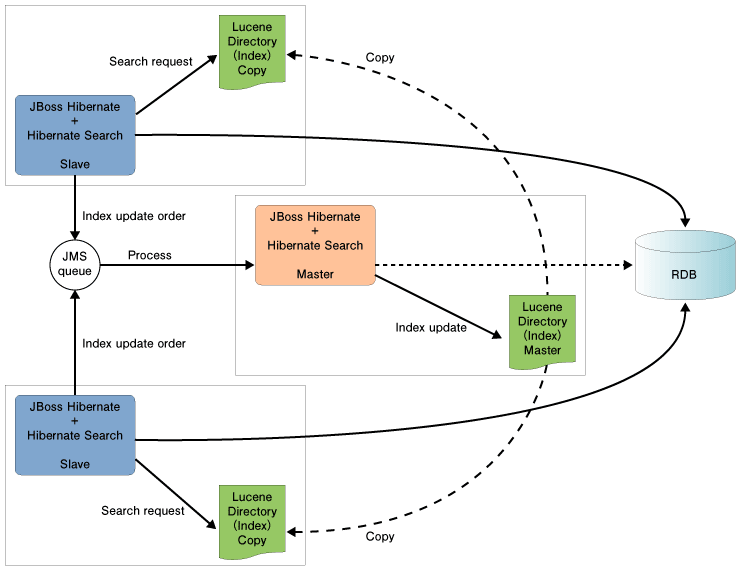 図3:クラスタ環境におけるHibernate Searchの実行 (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||
| IndexReaderの戦略種別 | ||||||||||
検索処理はLuceneのIndexReaderというクラスのインスタンスを使用して行われる。このインスタンスを取得する「戦略(Reader Strategy)」として、Hibernate Searchは「個別(not-shared)」と「共有(shared)」の各方式を用意している。 「個別」戦略では、IndexReaderのインスタンスが検索リクエストごとに毎回作成され、使い終わったら破棄される。この方法は検索性能が落ちるため、筆者としては推奨しない。 「共有」戦略では、Hibernate Search内に検索インデックスに対応した1つのIndexReaderインスタンスを作成し、これですべての検索リクエストを処理する。インデックスが更新された場合は、自動的にIndexReaderの再オープンが実行される。通常はこの戦略を使用する。 | ||||||||||
| 次回は | ||||||||||
以上、今回はHibernate Searchの概略を説明した。次回ではビジネスオブジェクトと全文検索の機能がHibernate Searchによってシームレスにマッピングされる様子を、実際にプログラムを書いて確認していく。 | ||||||||||
| 前のページ 1 2 3 | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載

