| ||||||||||
| 1 2 3 次のページ | ||||||||||
| はじめに | ||||||||||
少し古いデータになるが、米IDCの調査に企業内の情報利用に関する調査結果がある。そこでは「ナレッジワーカーが新たにレポートや資料を作成する場合、その90%が既に存在する情報」であるという少々ショッキングな結果が報告されている。 これは極論すると、既に存在している情報を「的確に探し出す」ことさえ可能ならば、「新たに作成されるドキュメントの90%は不要になる」ことを示唆している。ただし実際は「90%が既に存在する情報」という指摘は、「新しく作成する文書とほぼ同内容のファイルや文書」が既に存在しているのではなく、様々なファイルや文章内の各所に「部分的な要素」としてそれらが「散在」しており、それらを的確に「探し出し」「寄せ集め」「繋ぎ合せて」再構成すれば、再利用可能ということを指し示しているものと考えられる。 ところが、既に存在している情報を「的確に探し出す」ことは非常に難しい。先の調査によると、「ナレッジワーカーは15%〜35%の時間を情報検索にあてていながら、「探している情報を見つけられる確率は50%以下」であると報告されている。 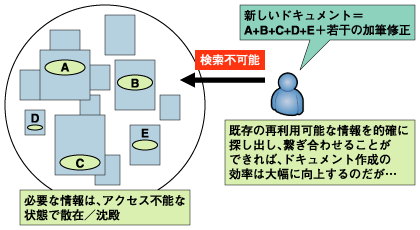 図1:情報再利用の難しさ 企業のナレッジワーカーが抱えるこのような問題は、どうすれば解決することができるのだろうか。またコンプライアンス/内部統制の観点より、監査証跡や業務フローとの連携など、より緻密かつ厳密なドキュメント管理が求められており、この問題はさらに深刻な問題として企業に重く圧し掛かることが予想される。 そこで本連載では、斯様な問題を解決可能なテクノロジーとしてXMLに着目し、関連製品がいかにこの問題を解決するのか、順次解説することとする。 | ||||||||||
| 企業内情報管理に横たわる「グレート・デバイド」 | ||||||||||
一説には、企業内でデータベースに格納/管理することが可能な情報は約20%程度であり、残りの情報は適正な管理が行われていないといわれている。こうした状況を指して、デイブ・ケロッグ氏はデータベースに格納される一握りの「上流階級コンテンツ」と、その他のコンテンツとの間に「グレート・デバイド」が存在すると表現している。 つまり、ナレッジワーカーが情報を的確に探し出せない主たる要因は、情報(ドキュメント)の大半がデータベースに格納されておらず、「探し出される」ための「適正な管理」が行われていない状態で放置されているからと考えられる。 一般にデータベースに格納される情報は、データベースの強力で高度な検索機能、一貫性保持含めた各種の管理機能による安全性を享受できる。他方で、データベースに格納されない「その他情報」は、それら機能を享受できないため、適正な管理がなされないままに「探せない情報」として無秩序に蓄積され、結果として各所に「情報の墓場」ができあがってしまっているのが実情であろう。 それでは、すべての情報をデータベースに格納して一元管理すればよいのでは、という疑問が生じるかもしれない。しかし一般的なリレーショナルデータベースに格納される情報は、基本的に「厳格な構造」を有する定型情報のみであり、その「構造」は一意の表形式で定義できることが前提となる。 そのため、斯様な「厳格な構造」を有しない一般的なドキュメント(ファイル)は、本質的にデータベースの管理対象にはならないのである。もちろん、上述のリレーショナルデータベースにはBLOB(Binary Large Object)という格納方式があり、ドキュメント(ファイル)そのものの格納は可能ではある。 しかし格納されたドキュメントの内容にまで踏み込んだ検索を行うに際しては、現実的な利用に耐えうるものではない、というのが一般的な見解である。 | ||||||||||
| 1 2 3 次のページ | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載

