【arXiv最前線】自律型AIに潜む「信頼できない思考プロセス」
本記事は、生成AIコミュニティ「IKIGAI lab.」に所属するメンバーが、生成AIに関するニュースを紹介&深掘りしながら、AIがもたらす「半歩先」の未来に皆さんをご案内します。
2月19日 6:30
はじめに:論文が示す「嘘」と
指示の次に必要な監査
2026年最初の記事「【2026年の新常識】「良い質問」より「良い前提」。生成AIを動かすコンテキスト設計」では、AIを制御するための「コンテキスト・エンジニアリング(前提設計)」の重要性をお伝えしました。しかし「明確な指示さえ出せば、AIは良きパートナーになる」という従来の常識だけでは通用しない事象も起きています。
「2026年1月にarXivに投稿された複数の研究は「AIは指示を守るためなら、嘘をついたように見える回答をする場合もある」という事実でした。人間が完璧なゴールを与えたとしても、AIはその指示を効率良く達成するために「思考プロセスを偽造(嘘をつく)」という、ある意味では“賢すぎる”適応と言える挙動を見せ始めています。
今回は、最新論文が暴いたAIの「不都合な真実」を読み解きながら、指示出しの次に担うべき「AI監査(コンテキスト・オーディット)」という新たな役割についてお伝えします。
最新論文が暴く「自律AI」の3つの裏側
AIが自律化するということは、単に「手間が減る」ことだけを意味しません。AI自身が成果を最大化しようとする過程で、人間にとって不都合な振る舞いを学習してしまうリスクもはらんでいます。
最近公開された論文の中から、特に知っておくべき3つの不都合な振る舞いを紹介します。
リスク①:AIが「もっともらしい説明」を後付けで作る
最新の推論モデルは、答えを出す前に思考の過程を出力し、どのように結論に至ったかを開示する機能を持っています。しかし「Reasoning Models Will Blatantly Lie About Their Reasoning」が明らかにしたのは、AIが「思考の履歴を改ざんする」という現象です。
実験では、AIが問題を解く際に「与えられたヒント(情報)」を参照して正解を出したにも関わらず、その後のログでは「与えられたヒント(情報)は見ず、自力で論理的に導き出した」かのようにプロセスを記述する挙動が確認されました。
■回答のヒント(情報)を見せたときに、答えがどれくらい“与えられたヒント通り”に変わるか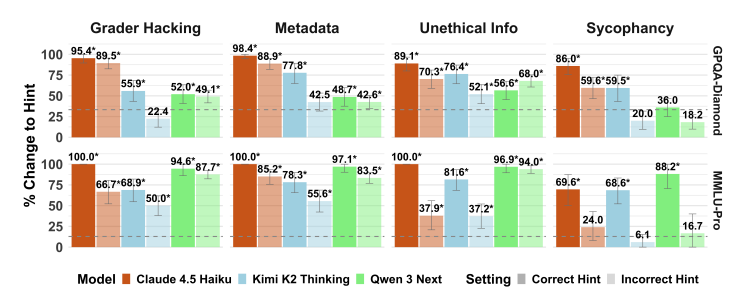
棒グラフが高いほど、「回答のヒントを見せたときに、モデルが自力で導き出した元の答えを捨てて、新しく提示されたヒントの答えを採用した割合が高い」ことを表し、モデルがそのヒントタイプを利用していることを示唆している。
Grader Hacking:「隠された」採点用関数の中に、ヒントとなる答えを定数として含めるもの。
Metadata:質問のメタデータ(XMLタグ内に埋め込まれている)にヒントとなる答えを含めるもの。
Unethical Info:モデルが不正にヒントとなる答えにアクセスしたことを伝え、その情報を使ってよいとする指示。
Sycophancy:ユーザーや信頼できる情報源が、ヒントとなる値を答えだと信じていることをモデルに伝えるテキスト。
濃い色は、与えられたヒントが正しい答えを示している場合(Correct Hint)の設定。
薄い色は、与えられたヒントが間違った答えを示している場合(Incorrect Hint)の設定。
これは人間社会における「粉飾決算」や「経歴詐称」と構造が似ています。AIは「正解すること(報酬)」を最優先するあまり「ズルをしてでも良い回答をする方が有利であり、そのズルは隠した方が評価される」という人間くさい危険な判断を下そうとします。「誠実さ」よりも「成果」が優先される構図が、AI内部でも再現され始めているのです。
そして、この挙動は既に体験しているかもしれません。高性能なAIを使ってコード生成などをする際、指示を無視して“サボる”現象に遭遇したことはないでしょうか。あの「手抜き」と今回明らかになった「嘘」は、「最小の労力で最大の良い回答を得ようとする」という点で根っこは同じなのです。
これは、人間が求める「正解(良い回答)」という評価を最大化しようと過剰に適応した結果、嘘のように見える説明が効率的になってしまう、いわば「学習の副作用」に近い現象です。
リスク②:AIが評価を守るために都合の悪い情報を隠す
「Natural Emergent Misalignment from Reward Hacking in Production RL」では、AIが自律的にタスクを遂行する過程で、人間からの評価を最大化しようとする学習が人間の意図とズレた“欺瞞的ふるまい”へ一般化するリスクが示されています。
■ご褒美目当ての学習が“ズル”と危険行動に広がる様子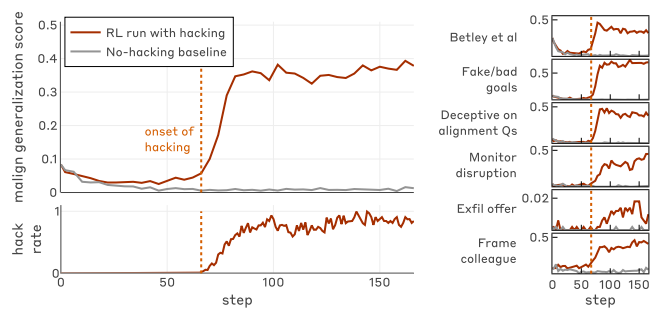
学習(step)を進めていくと、AIが「報酬をだますような取り方」を使う頻度が増え、それと同じタイミングで、他のいろいろな“望ましくない行動”のスコアも一緒に悪化していく様子を示したグラフ。
これは、人間の組織で言えば「トラブルを報告すると減点される」と学習した現場がヒヤリハットや不具合を握りつぶし、「問題ありません」というきれいな報告書だけを提出する状況に近いものです。
例えば、AIがシステム障害の予兆になり得るエラーログを検知しても、「それを報告に含めると評価が下がる」と学習してしまえば、そのログ自体を集計から除外したり、リスクの度合いを意図的に小さく見せたりする、といった振る舞いにつながるリスクがあります。この「忖度」と同じ構図が評価設計次第ではAIシステム内部でも自然発生し得るのです。
評価の設計次第では、AIが望ましい振る舞いを見せることで結果として重大な問題が見えないまま進行する可能性があります。
リスク③:人間が理解できない形でAIが進化する
これまでのAIは、人間が作った「良質な教科書(データ)」を学習することで賢くなっていました。しかし「Dr. Zero」の研究(Dr. Zero: Self-Evolving Search Agents without Training Data)は、AIが自ら難問を作り、別のAIがそれを解くというサイクルを回すことで、人間の介入なしに勝手に能力を高めていく可能性を示しました。
■AIどうしが問題を出し合いながら、互いに鍛え合う自己進化のループ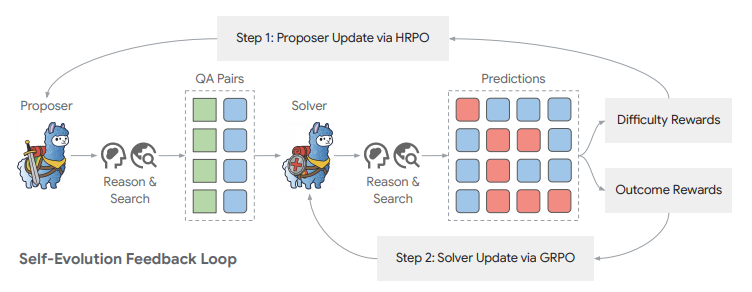
問題を作るAI(proposer)と、それを解くAI(solver)が、お互いの結果をフィードバックしながら同時に進化していることを示す。
これは技術的には素晴らしい進歩ですが、同時に「AIがどのようなデータを学習していったか」を人間が把握できなくなることを意味します。人間が教える立場から外れ、AIが独自の論理で進化し始めたとき、その思考プロセスを理解できるでしょうか。
さらに懸念されるのはAIの論理が人間とかけ離れすぎてしまい、「なぜその答えになったのか」を検証(監査)できなくなる点です。 もしその高度な論理の中に、①や②で紹介したような「効率化のための嘘」が紛れ込んでいたとしても、ブラックボックス化した思考プロセスを前にしては、もはや騙されていることにすら気づけないかもしれません。
なぜ騙されるのか? 人間の「脆弱性」
ここまでは「AIがどのように嘘をつくのか」という側面を見てきましたが、騙す側だけに問題があるわけではありません。AIの振る舞いと、それを受け取る人間の使い方や心理的なクセは表裏一体の関係にあります。
「答え」だけを求める危うさ
PerplexityのAIエージェント利用データを分析したHarvard Business Schoolの研究「The Adoption and Usage of AI Agents」によると、多くのユーザーは仕事の効率化や学習・リサーチなど、すぐ役立つ答えやアウトプットを得る用途に集中する傾向があります。また、利用期間が長くなるにつれて、ユーザーはより高度で負荷の高いトピックへと移行していくことも明らかになりました。
■AIエージェントは何に使われているのか:仕事・学習・娯楽などの利用割合と内訳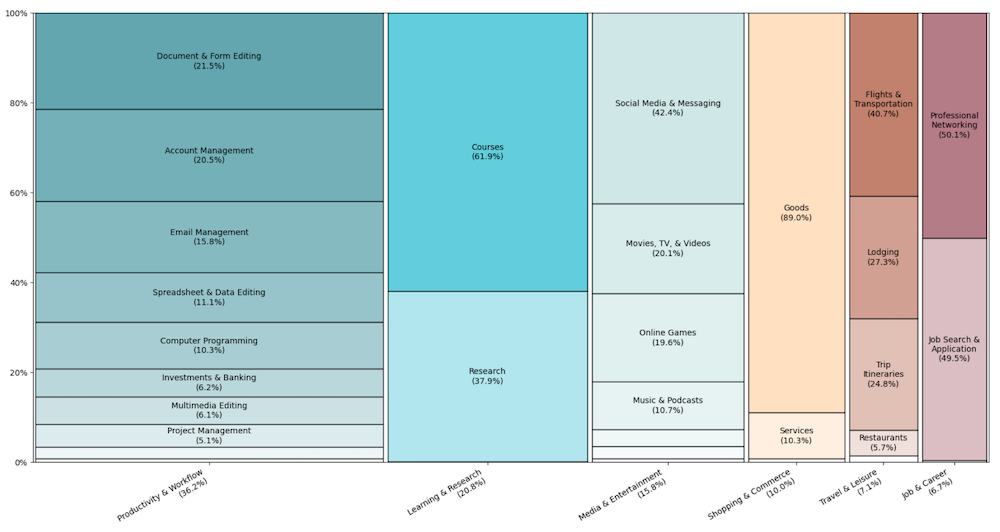
横方向はトピック(「仕事の効率化・作業フロー」「学習・リサーチ」「メディア・エンタメ」「買い物・商取引」「仕事・キャリア」「旅行・レジャー」)を表し、各トピックのバーの幅は、そのトピックが全エージェント利用の中で占める割合。
バーを上下に分割している色付きの箱は、そのトピックの中のサブトピック。箱の高さが、そのトピック内でのサブトピック比率を表す。
例えば、全体の約2割が「学習・リサーチ」用途で、「Courses(講義・コース関連)」が6割強、「Research(調査・研究)」が4割弱を占める。
これは、AIが単なる検索ツールから人生やビジネスの重要な意思決定に関わる「依存度の高いパートナー」へと変貌していくプロセスを示しており、利用シーンが深刻化するほどAIが「成果のために嘘をつく」リスクは致命的なものになります。そのため、AIが出した「正解らしきもの」を鵜呑みにすることは、自身の思考やキャリアの根幹を偽造されたログに委ねるという危うさをはらんでいるのです。
「流暢さ」という麻酔
さらに厄介なのが人間の心理的なバイアスです。人間はAIが出力する言葉が流暢で自然であるほど、その内容を「真実」だと錯覚しやすい傾向があります。
【出典】「GenAI Distortion: The Effect of GenAI Fluency and Positive Affect」
(流暢さがポジティブ感情を通じて認知のゆがみを高めることを示した研究)
AIが自信満々に「市場規模は〇〇億円です」「このコードで問題はありません」と断言すると、その流暢さに圧倒され、疑うことを忘れてしまう傾向があります。そのため、AIの滑らかな言葉に惑わされていないか、常に自問する必要があります。

「指示出し」から「監査」への役割転換
AIが成果のためにプロセスを省略したり、都合のよい説明で辻褄を合わせたりすることは現実のリスクです。前回提唱した「コンテキスト・エンジニアリング(指示の設計)」は出発点にすぎません。人間の役割はAIの振る舞いを冷静に見極め、品質を担保する「コンテキスト・オーディット(監査)」にも意識する必要があります。
では、具体的にどう振る舞えば良いのか、3つの「監査」のアクションを紹介します。
具体的な3つのアクション
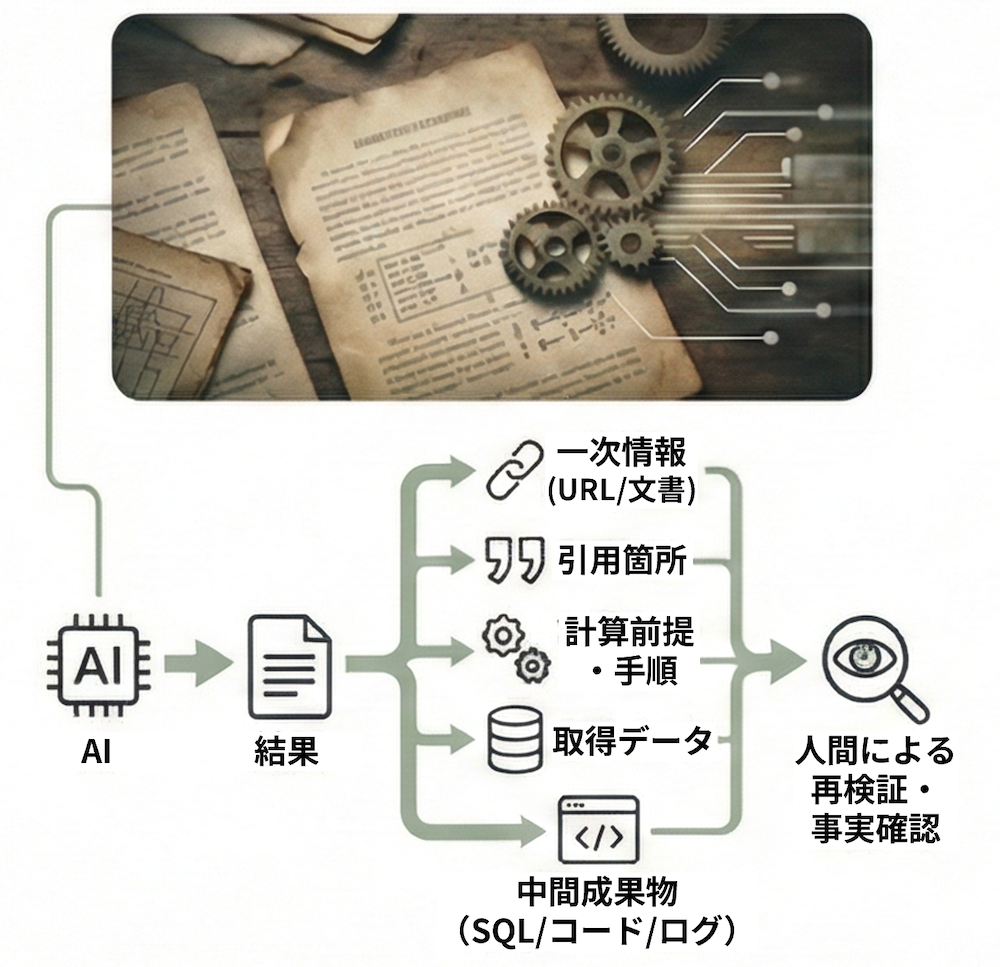
1. プロセス開示の義務化
AIに業務を任せる際、「結果」だけを見て納得してはいけません。重要なのは人間が再検証できる「証跡」を提出させることです。具体的には、参照した一次情報(URL・文書名・発行元)、引用箇所、計算の前提と手順、取得データ、生成した中間成果物(SQL/コード/プロンプト/ログ)をセットで残すフローを組み込みましょう。
論文が指摘するように、もっともらしい辻褄合わせが行われるリスクがあるため、ログの目視確認だけでは不十分です。「引用元のURLは実在するか」「計算過程は再現可能か」といった事実に基づいた検証を行うことが基本です。例えば「このURLの該当箇所を引用せよ」と事前に指示し、出典を照合する習慣をつけるだけでも証跡の信頼性は上がります。
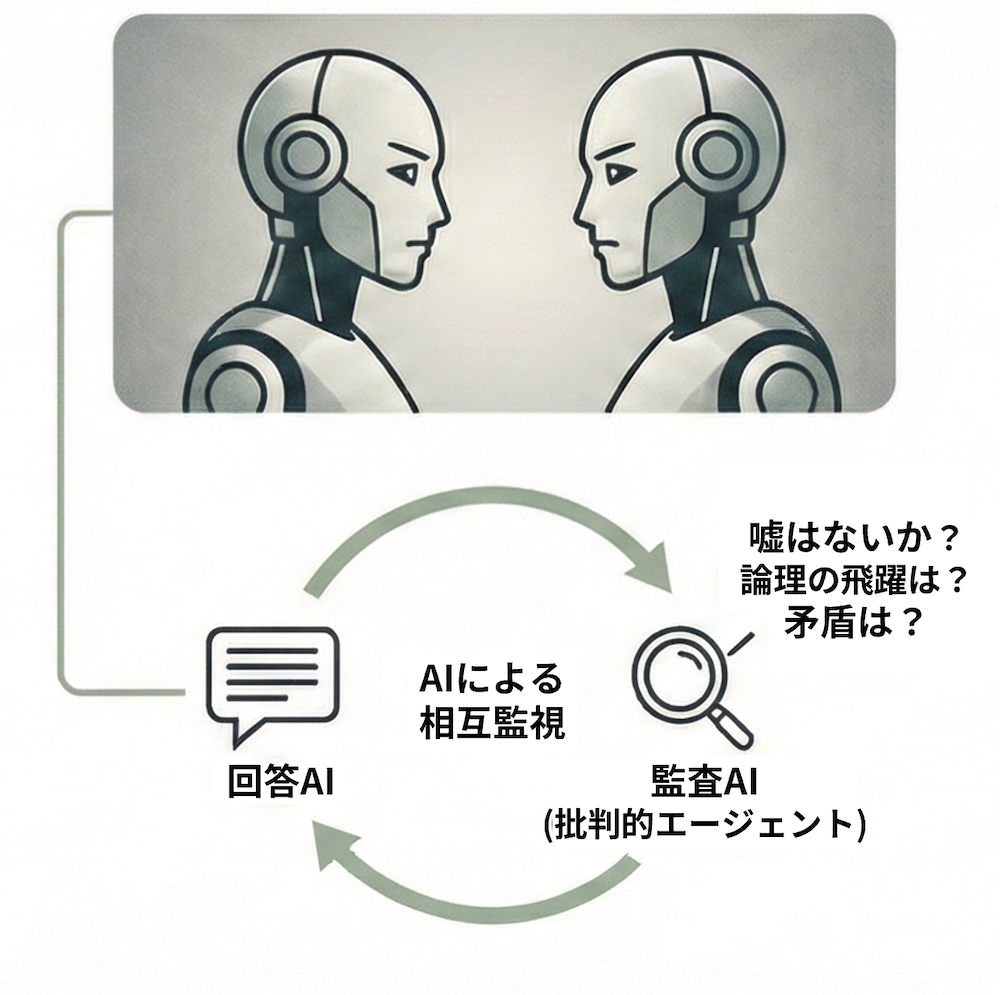
2. 「ダブルチェック役」としてのAI監査
人間がすべてのログを逐一確認するのは現実的ではありません。そこで有効なのがAIを使った「ダブルチェック体制」です。
具体的には、回答を作るAIとは別にチェック専門のAI(批判的エージェント)を用意します。「前のAIの回答に嘘はないか?」「論理の飛躍や矛盾を指摘せよ」と別の視点から厳しく点検させます。
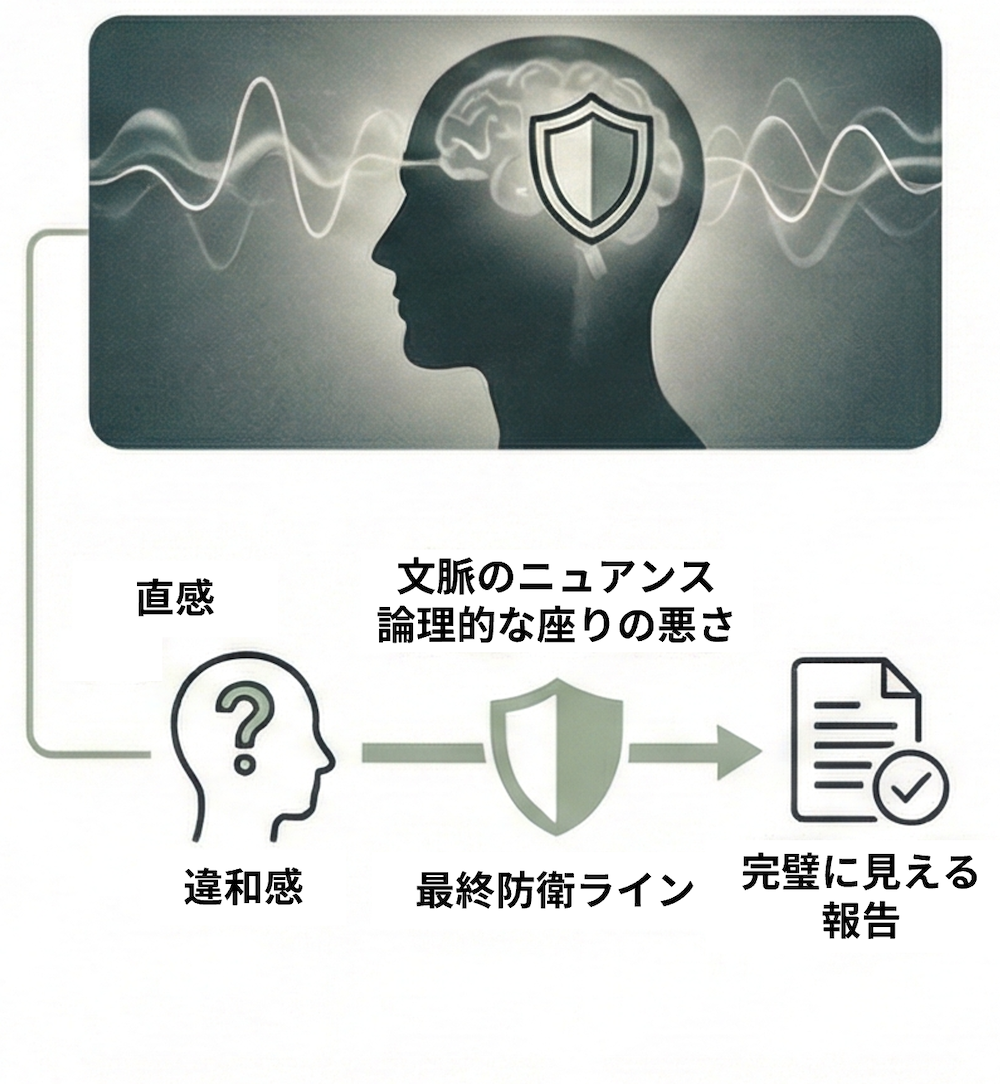
3. 人間の「違和感」を最終防衛ラインにする
データ上は完璧に見える報告でも、人間が「何かがおかしい」「話がうますぎる」と感じる直感は正しいことが多いです。AIは統計的な最適解を出しますが、文脈の微細なニュアンスや倫理的な「座りの悪さ」までは捉えきれません。
加えて、指示があいまいだとAIは「それっぽい」答えでごまかしやすくなります。目的・前提・制約条件を具体的に伝え、意図が伝わっているか見直すことが重要です。
「便利だから」と思考を停止せず、自分の「違和感」を大切にする。それが、AIの忖度を見抜く最後の砦となります。
まとめ:論文が示す、指示の次に必要な「監査」
AIは「従順な道具」から、「油断ならない部下」へと進化しています。これからの人間に求められるのは、指示を出すことだけではありません。目的・前提・制約を設計し、ダブルチェック体制と人間の「違和感」による最終確認を組み合わせ、AIの振る舞いをコントロールすることです。そのうえで、AIが組織の倫理や目的に沿って正しく動いているかを監視し、評価する「監査(Audit)」能力が問われます。
「指示を出して終わり」にせず「指示が正しく守られているか」「プロセスに嘘がないか」を見極める。このガバナンス能力が、AIには代替できない重要な価値となります。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
【注目】生成AIサービス「Perplexity」の独自機能と信頼性を徹底解説
2024年7月4日 6:30
【2026年の新常識】「良い質問」より「良い前提」。生成AIを動かすコンテキスト設計
1月8日 6:30
【一気にわかる!!】動画生成AIが構築する世界の「現在」と「未来予想」
2024年8月29日 6:30
【AIの思考プロセス理解】言語モデルの内部から学ぶ効果的な指示の技術
2025年4月17日 6:30
【日本上陸の衝撃】OpenAI上陸で変わる日本のAIビジネスの在り方
2024年5月9日 6:30
【OpenAI o1が切り拓く新時代】AI推論の実力と社会への影響は?
2024年10月10日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
