Hadoopに関する最新の技術情報やロードマップ、ユースケースが入手できるHadoop Summit
Hadoop SummitはHadoopエコシステムに関わるデベロッパー、ユーザーが集まる最大規模のイベントのひとつ(もうひとつStrata + Hadoop Worldという大きなイベントがあります)であり、現在では世界中の複数の都市で開催されています。その中でもサンノゼが一番歴史が古く、2007年に第1回が開催されていますから、今年で10週年を迎えるHadoopと同じく歳を取ってきていることになります。なお、今年は東京でも初のHadoop Summitが10月に開催されることになっています。

3日間のキーノートで語られたHadoopのいまと今後
初日のキーノートではHadoopエコシステムがもたらすビジネスの変化が語られました。印象的だったのは自動車保険を提供するProgressive社の事例です。彼らはSnapshotと呼ばれるデバイス経由でリアルタイムに自動車からアップロードされるデータと道路の混雑状況のデータ、そして過去の様々なデータを組み合わせることによりドライバーごとに価格を最適化し、総額にして約5億6千万ドルの保険料割引を実現したと発表しました。
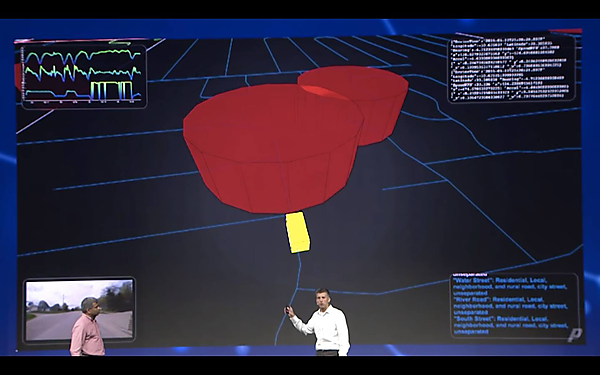
例えば上記の写真のデモは、赤い円筒が、過去のデータから得られた事故多発地帯や犯罪多発地帯を表しており、被保険者の車がこのエリアに侵入したことを自動的に検知する仕組みを可視化したものです。
2日目は実際のHadoopユーザーのユースケースを中心に、GEやMacy'sのような歴史を持つ大きな企業たちがどのようにしてHadoopの導入を行い、データをビジネスに活用するに至ったかが語られました。
そして3日目は技術面の話題が語られました。最近のYahoo! Inc.でのHadoop活用事情、今後のHadoopとクラウドの関係性、Apache NiFiがもたらすデータフローマネジメントが取り上げられました。この記事では特にこのクラウド関連について注目してレポートしたいと思います。
Hadoopとクラウドの関係性
Hortonworksの共同創業者のひとりであるSanjay Radia氏は、セルフサービス化による、よりクイックで価値の高いHadoop活用について語りました。まずクラウドのもたらす即時性、伸縮性、経済合理性をおさらいするところから話を始め、すでにこの分野で事業を展開しているAWS、Google、Microsoftなどに触れつつ、コミュニティとしてこれらのメリットをよりHadoopにとって当たり前のものにしていく活動が必要があることを強調しました。
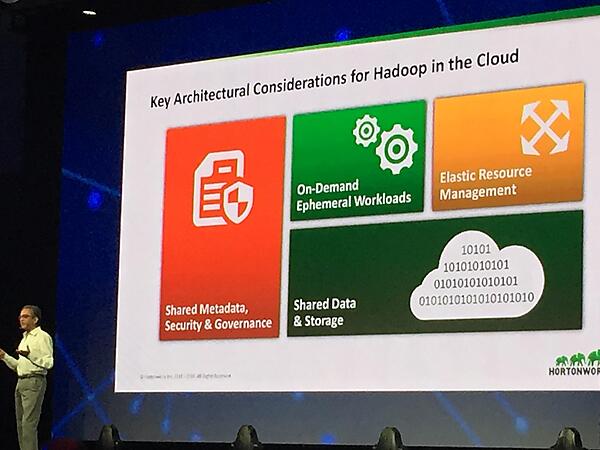
例えばクラウドストレージであるAmazon S3やAzure Blob Storageは素晴らしいデータ耐久性や拡張性、地理的分散性を提供しており、クラウド上でHadoopを利用するのであればHDFSではなくクラウドストレージが間違いなくデータレイクであると語りました。一方、これらのストレージはデータロカーリティを提供してはくれません。これを解決するコミュニティの努力のひとつとして、Hadoopクラスタ内でキャッシュレイヤを提供するLLAPというHiveの新しい機能に言及しました。

LLAPはHive以外にもMapReduceやSparkからもデータソースとして利用でき、これを介すことによりクラウドストレージをデータレイクとして利用しつつ、データローカリティやアクセスコントロールのようなHadoopが本来持つ機能性を損なわずに利用できると語りました。さらにこのあと、クラウド上にクラスタをデプロイ、管理するためのHortonworks Cloudというソリューションのデモが行われました。このキーノートのメッセージとしては、クラウドストレージをシェアードストレージ/データレイクとして利用し、必要に応じてユーザーが自分のクラスタ(コンピューティングリソース)を構築/増築して利用するようなHadoopの使い方が、クラウド事業者の提供するHadoopサービス以外でも当たり前になっていく、と解釈できます。
各所で起こるHadoopのクラウドサービス化
今回のHadoop Summitでは前述のキーノート以外でも各所でHadoopのセルフサービス化やクラウドサービス化が語られました。なお、ここでいうクラウド化というのはAWSのようなクラウドサービスへの移行のことを指すわけではなく、「ユーザーが自分のクラスタ環境を必要に応じてプロビジョニングし、そこにデータをロードして利用できるセルフサービス環境」と捉えて頂ければと思います。私が参加したセッションでは少なくとも、Yahoo! Inc.、eBay、Uberがこのセルフサービス化について語っていました。
Yahoo! Inc.のケース
Yahoo! Inc.では分析ユーザーに対してデータソースそのものと、データマートを構築するための仕組みを提供しているという話がセッションで紹介されました。
Faster, Faster, Faster: The True Story of a Mobile Analytics Data Mart on Hive
データマートはある程度定型化されたフォーマットに則ったETLと、Apache Hive、Apache Druidによって構成されており、ユーザーはそれぞれこれを構築し、自分の分析を行っているようです。
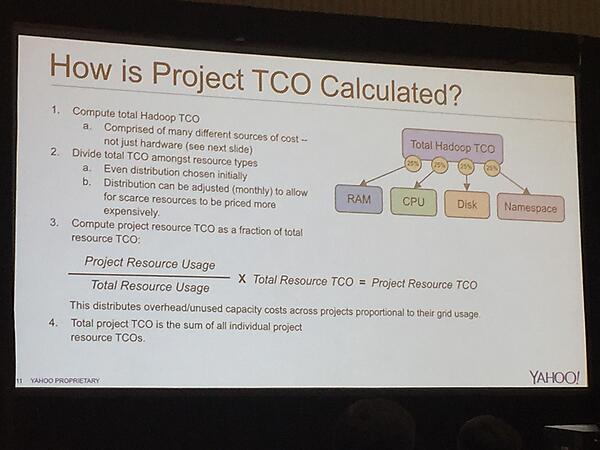
また、この話とは別のセッションで紹介されていた非常にユニークな話として、Hadoopユーザーの各チームは実際にどのくらいのサーバーリソースを利用しているかが計測されており、これをお金に換算してモニタリングをしているという話も紹介されていました。
eBayのケース
eBayでもGoverned Self Service Analysisという名のもとにYahooと同様の取り組みが行われています。
ユニークな点としては、ユーザーがそれぞれ作成できるデータマートは、他のユーザーから共用される仕組みになっており、既存のデータマートを一覧、ブラウズするためのデータマーケットのような仕組みも提供されていると語られました。ユーザーはまずはこのマーケットで必要なデータを検索し、マートが存在しなければ自分自身でマートを作成することになります。この際、データクオリティファイアウォールという概念が取り入れられており、作成しようとするデータマートに対してクオリティチェックの仕組みが入っているようでしたが、残念ながら具体的な指標等については語られませんでした。
Uberのケース
Uberは前の2者とは違ったとてもユニークなアプローチを語りました。
Uberでは規模やリソーススケジューラ、実行方式の異なる4つのSparkクラスタがあり、すべてのデータはスキーマが付与されており、それをカタログ化しているWatch Towerという社内サービスを開発/運用しているとのことです。これによりデータの利用者は自分がほしいデータを迷わずに見つけ利用できるようになっていますが、実際のデータを使ったアプリケーションを開発するデベロッパーにとって、これらを取り扱うのは学習コストが高いというフィードバックが多くあったとのことです。そこでUber Development Kit(以下UDK)と呼ばれるツールをユーザーに対して提供し、メタデータやスキーマを始め、実データへのアクセスを抽象化していると語りました。また前述の4つのクラスタ群をUDKにより隠蔽することにより、ユーザーは自分のジョブをどのクラスタに流せばいいのか、というような悩みもユーザー側から取り除くことに成功しているようです。
まとめ
このように、今回のHadoop Summitでは、Hadoopの提供する機能性を「必要な人が、必要なときに」利用できるようにするための努力を語るトークが目立ったのが印象的でした。Hadoopの機能性はもちろん今後も進化していくと思いますが、こういった「ease of use」やHadoopのセルフサービス化という文脈の話も今後いろいろなところで試行錯誤が繰り返されていくだろうと感じたHadoop Summitでした。
- この記事のキーワード
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
