本連載では、実際に「MySQL Cluster」を利用するためのチュートリアルとなるように、その特徴と基本的なアーキテクチャからインストール方法、基本的な操作などをコマンド付きで解説していきます。第6回の今回は、MySQL Clusterのサイジングについて解説します。
前提となる環境
記事中のコマンド例は、第2回でインストールした環境に第5回で紹介したサンプルデータベース(worldデータベース)を作成した状態を前提としています(追加設定として、mysqlユーザーの環境変数"PATH"に"/home/mysql/mysqlc/bin"も追加した状態を前提)。
はじめに
MySQL Clusterを使用する際、データノードのメモリ使用量、ディスク使用量のサイジングは非常に重要です。データノードのメモリが足りなければ、必要なデータをデータノードに格納しきれずにデータ格納処理がエラーになってしまいます。また、ディスク使用量が増加し、空き容量が枯渇すれば、最悪の場合はシステムダウンにもつながります。
今回は、このデータノードにおけるメモリ使用量とディスク使用量のサイジングについて解説します。
なお、今回の記事では「性能要件に基づくサイジング」や「ディスクテーブル*1を使用した場合のメモリ使用量/ディスク使用量のサイジング」は対象外としています。性能要件に基づくサイジングについては、負荷テスト等を実施してシステム毎に必要なサーバースペックを見積ってください。また、ディスクテーブルを使用した場合のメモリ使用量/ディスク使用量については、本記事で解説する内容に加えて、追加の考慮事項があります(ディスクテーブル固有のオブジェクトが使用するメモリ使用量/ディスク使用量と、ディスクテーブルを使用することによって削減できるメモリ使用量について考慮する)。ディスクテーブルの詳細については、以下のマニュアルを参照してください。
MySQL Cluster ディスクデータテーブル
http://dev.mysql.com/doc/refman/5.6/ja/mysql-cluster-disk-data.html
[*1] MySQL Clusterは、デフォルトではデータをすべてメモリ上に保持するインメモリデータベースとして動作しますが、ディスクテーブルを使用することでインデックスが付いていない列だけはディスク上に保持できます。ディスクテーブルという名称ですが、実際にはテーブル単位ではなく列単位で保持する領域が変わります。ディスクテーブルを使用するためには、事前の追加設定とメモリ上やディスク上の追加領域が必要となります。
MySQL Clusterが使用するインデックスの種類
メモリ使用量、ディスク使用量のサイジングについて解説する前に、MySQL Clusterが使用するインデックスの種類と領域について解説します。インデックスを使用するとその分メモリ/ディスクを消費するので、インデックスの数や種類もサイジングに影響を与える要因となります。MySQL Clusterが使用するインデックスを構造から分類すると表1のようになります。
表1:MySQL Clusterが使用するインデックスの種類(構造からの分類)
| 種類 | アクセスタイプ | 用途 | 使用領域 |
|---|---|---|---|
| ハッシュインデックス(主キー) | 一意検索 | 主キー | IndexMemory |
| ユニークハッシュインデックス | 一意検索 | ユニークキー | IndexMemory+DataMemory |
| オーダードインデックス (T-TREEインデックス) |
範囲検索 ソート |
全インデックス | DataMemory |
ハッシュインデックス(主キー)
テーブルに主キーを付けた時に作成されるインデックスで、レコードの一意性の担保と主キーによる一意検索で使用されます。主キーの値のハッシュ値に基づいて作成されるインデックスであるため、ハッシュインデックスだけでは範囲検索やソートには使えません。そのため、デフォルトではハッシュインデックス作成時に後述のオーダードインデックスも同時に作成され、範囲検索やソート時はオーダードインデックスが使用されます。
ハッシュインデックスはメモリ上のIndexMemoryに保持され、ディスク上には保持されません。データノード起動時にローカルチェックポイント(LCP)のデータ(テーブルの実データ)から再作成されます。
ユニークハッシュインデックス
主キー以外の列にユニークインデックスを作成すると、ユニークハッシュインデックスが作成されます。主キーと同様にキー値の一意性の担保や一意検索で使用されますが、範囲検索やソートには使えません。デフォルトでは、ユニークハッシュインデックス作成時にもオーダードインデックスが同時に作成されます。
ユニークハッシュインデックスはキー値に対応する行データへのポインタではなく、対応する主キーの値を保持しています。そのため、ユニークハッシュインデックスを使って一意検索をした場合は、ユニークハッシュインデックスからインデックスを付けているテーブルの主キーの値を判断し、その後主キー(ハッシュインデックス)から対応する値を検索するという動きになります。図1は、ユニークハッシュインデックスのイメージを図示したものです。
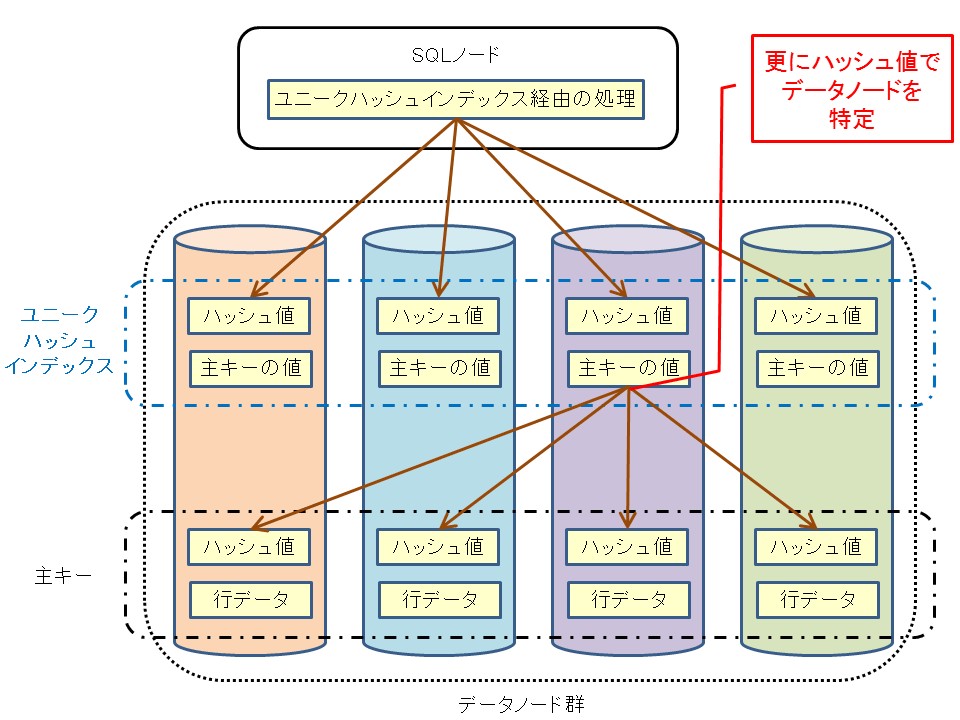
図1:ユニークハッシュインデックスの構造
ユニークハッシュインデックスは、メモリ上のIndexMemoryとDataMemoryに保持されます。DataMemory上のデータはLCPによりディスクに書き出されるため、ディスク容量も必要とします。
オーダードインデックス(T-TREEインデックス)
キー値の順序によってソートされたインデックスで、ユニークキーにもノンユニークキーにも使用できます。ハッシュインデックスでは実現できない範囲検索やソートにも使えます。デフォルトではハッシュインデックス、ユニークハッシュインデックスの作成時にオーダードインデックスも同時に作成されます。また、ノンユニークキーにセカンダリインデックス(主キー以外のインデックス)を作成した時には、オーダードインデックスのみが作成されます。
オーダードインデックスは、RDBMSで一般的に用いられるB-TREEインデックスと似た仕組みのT-TREE構造(B-TREEインデックスがハードディスクなどの補助記憶装置に最適化された構造であるのに対し、T-TREEインデックスは主記憶装置(メモリ)に最適化された構造)になっています。オーダードインデックスという独特の名称を使用していますが、「B-TREEインデックスに似たインデックス」と捉えれば、MySQL Clusterが使用するインデックスの種類を把握しやすくなるのではないでしょうか。
オーダードインデックスは、メモリ上のDataMemoryに保持されます。
メモリ/ディスク使用量を削減する工夫
前述の通り、ハッシュインデックス(主キー)およびユニークハッシュインデックス作成時には、デフォルトではオーダードインデックスも一緒に作成されます。範囲検索やソートが不要で一意検索でしかインデックスを使わない場合は、リスト1のようにインデックス作成時に”USING HASH”句を付けることで、オーダードインデックスを作成せずにハッシュインデックスだけを作成できます。オーダードインデックスを作成しないことにより、その分のメモリ/ディスク使用量を削減できます。
リスト1:ハッシュインデックスのみを作成する例
mysql> CREATE TABLE test (
id INT,
col1 INT NOT NULL,
PRIMARY KEY(id) USING HASH,
UNIQUE KEY idx_col1(col1) USING HASH
) ENGINE=ndbcluster;
メモリ使用量のサイジング
データノードが使用する主要なメモリ領域として、DataMemoryとIndexMemoryがあります。また、1つ1つの要素が確保するメモリ領域は小さいですが、総容量としてはサイズが大きくなる可能性があるものとして、MaxNoOfOrderedIndexesなどのパラメータで指定されるメモリ領域があります。MySQL Clusterでは、これらの見積もりに役立つndb_size.plというPerlスクリプトを用意しています。
ndb_size.plの使用方法
ndb_size.plでメモリ使用量の見積もりをする場合、事前に以下の準備をしておきます。
【事前準備】
- Perl用ドライバ(DBIおよびDBD::mysql)のセットアップ
- MySQL Server(*2)上にInnoDBを使用して見積もり対象のテーブルを作成し、データも挿入しておく
[*2] MySQL ClusterのSQLノードでは無く、通常のMySQL Serverでも可
そして、リスト2のようにスクリプトを実行することで、指定したデータベース内のテーブルについて、MySQL Cluster上に作成した場合にどの程度DataMemory、IndexMemoryを消費するかを見積もれます。また、併せて”MaxNoOf~”パラメータに設定すべき最低値も算出できます。
リスト2:worldデータベースに対して見積もりをする場合の実行例
$ ndb_size.pl --user=root --database=world --host=127.0.0.1
ndb_size.plのオプション等の詳細は、以下のマニュアルを参照してください。
18.4.25. ndb_size.pl — NDBCLUSTER サイズ要件エスティメータ
http://dev.mysql.com/doc/refman/5.6/ja/mysql-cluster-programs-ndb-size-pl.html
リスト3は、第5回で構築したworldデータベースにndb_size.plを実行した場合の実行例です。最後に出力される"Parameter Minimum Requirements”部分で最低限必要なパラメータ設定値が確認できます。実行結果に出力されるバージョン番号が4.0、5.0、5.1と原稿執筆時点の最新版である7.4よりも古くなっていますが、5.1部分に出力される値を近似値として参照してください。なお、今回はチュートリアル目的で手順を簡単にするため、既に作成しているMySQL Cluster(ndbclusterストレージエンジン)のテーブルに実行していますが、通常はInnoDBのテーブルに実行します。
リスト3:ndb_size.plの実行例
$ ndb_size.pl --user=root --database=world --host=127.0.0.1
ndb_size.pl report for database: 'world' (3 tables)
---------------------------------------------------
Connected to: DBI:mysql:host=127.0.0.1
Including information for versions: 4.1, 5.0, 5.1
world.CountryLanguage
---------------------
DataMemory for Columns (* means varsized DataMemory):
<<中略>>
Parameter Minimum Requirements
------------------------------
* indicates greater than default
Parameter Default 4.1 5.0 5.1
DataMemory (KB) 81920 640 640 704
NoOfOrderedIndexes 128 5 5 5
NoOfTables 128 5 5 5
IndexMemory (KB) 18432 344 168 168
NoOfUniqueHashIndexes 64 2 2 2
NoOfAttributes 1000 28 28 28
NoOfTriggers 768 31 31 31
“NoOf~”については、”MaxNoOf~”パラメータに設定すべき最低値が出力されています(例:NoOfOrderedIndexesの値はMaxNoOfOrderedIndexesに設定すべき最低値)。算出された値に単位あたりのメモリ消費量を乗じて、メモリ消費量の合計値を見積もります。
”MaxNoOf~”パラメータの設定により増減するメモリ消費量
MaxNoOfOrderedIndexesなどの設定値を増加させると、その分データノードが確保するメモリ量は増加します。それぞれの設定のデフォルト値と単位あたり(設定値を1増加させた時)のメモリ消費量の目安は表2の通りです。ndb_size.plの実行結果から消費するメモリ量を見積もる際の参考にしてください(対象バージョンはMySQL Cluster 7.4)。
表2:”MaxNoOf~”のデフォルト値と単位あたりのメモリ消費量の目安
| パラメータ | デフォルト値 | 単位あたりのメモリ消費量の目安 |
|---|---|---|
| MaxNoOfOrderedIndexes | 128 | 10KB |
| MaxNoOfTables | 128 | 20KB |
| MaxNoOfUniqueHashIndexes | 64 | 15KB |
| MaxNoOfAttributes | 1000 | 200B |
| MaxNoOfTriggers | 768 | 400B |
データノードの台数とDataMemory、IndexMemory設定値との関係
ndb_size.plによって算出されたDataMemory、IndexMemoryの値は、レプリカを考慮せずに全データノードで保持する必要のあるデータ量です。そのため、データノードの台数やレプリカの数に依存して、データノード1台あたりが保持する必要のあるデータ量は変化します。
レプリカの数(NoOfReplicas)は通常2で使用するため、以下の計算式のようにndb_size.plによって算出された値を2倍した後、データノードの台数で割った値が実際にデータノード1台1台に設定すべきDataMemory、IndexMemoryの最低値になります。
データノードの設定値=(ndb_size.plで算出された値×2)/ データノードの台数
MaxNoOfOrderedIndexesなどはすべてのデータノード共通の設定であるため、データノードの台数を増やしてもデータノード1台1台に設定する値は小さくなりません。ndb_size.plの実行結果が、そのまま設定すべきパラメータの最低値となります。
ディスク使用量のサイジング
データノードが必要とする主なディスク領域として、LCP用の領域とGCP(グローバルチェックポイント)用の領域、バックアップファイル出力用の領域があります。なお、MySQL Cluster環境でバイナリログを出力した場合、バイナリログはSQLノードに出力されるため、データノードのディスク領域としてバイナリログの保管領域については考慮不要です。
LCP用の領域
LCP用のディスク領域には、DataMemoryの2倍のサイズを見積もります。
LCP用のディスク領域のサイズを設定するパラメータはありませんが、LCPはDataMemory上のデータをディスクに書き出す処理であるため、1回のLCPによるディスク書き込みは最大でDataMemoryと同じサイズを消費します。2倍のサイズを見積もるのは、LCPにより書き込まれたデータはディスク上に2世代保管される仕組みになっているためです。
また、CompressedLCPパラメータを設定することでLCPによるディスク出力を圧縮し、使用するディスク容量を抑えることもできます。
GCP用の領域
GCP用のディスク領域には、DataMemoryの4倍程度のサイズを見積ります。第4回で解説したように、GCPはLCPよりも細かい間隔で実行されるチェックポイント処理です。データノードの再起動時など最新のデータを復元する時には、LCPによりディスクに書き込まれたデータを読み込んだ後で、GCPによりディスクに書き込まれたREDOログを適用します。
REDOログファイルは循環して使用されるため古い情報は上書きされますが、リカバリに必要な(最新データの復元に必要な)REDOログは上書きされません(リカバリに必要なREDOログは直近の実行が完了したLCP以降に出力されたREDOログ)。そのため、REDOログファイルのサイズが小さすぎると実行中のLCPが完了するまで更新処理がエラーになってしまいます(この場合、すべての更新トランザクションが内部エラーコード410「Out of log file space temporarily」で失敗する)。このエラーを防ぐには、REDOログファイルのサイズは余裕をもって大きめのサイズにしておく必要があります。
一方、リカバリに必要なREDOログが大きくなり過ぎると、データノードの再起動などに時間がかかり過ぎてしまうという弊害があります。リカバリに必要なREDOログが大きくなり過ぎないようにするための目安として、前回のLCPが完了してから次回のLCPが完了するまでに出力されるREDOログのサイズが、LCPによって書き込まれるデータのサイズ(=DataMemory)を超えないように調整します(調整方法は後述)。LCPにより書き込まれたデータはディスク上に2世代保管されるので、この場合ディスクに保持する必要のあるREDOログのサイズはDataMemoryの2倍となります。しかし、REDOログの出力量は実行される更新処理量に依存するため、安定稼働のためには余裕をもって領域を確保しておく必要があります。そのためのマージンを2倍と考えると、必要なREDOログファイルの総容量はDataMemoryの4倍となります。
REDOログファイルの総容量は次の計算式で求められます。安定稼働には、この計算式の結果がDataMemoryの4倍程度になるように、FragmentLogFileSizeパラメータを増加させます(NoOfFragmentLogFilesのデフォルト値(16)は一般的にREDOログファイルの数として十分であるため、通常はFragmentLogFileSizeによって調整する)。
REDOログファイルの総容量=NoOfFragmentLogFiles * FragmentLogFileSize * 4
REDOログの出力量は実行される更新処理量に依存するため、パラメータで制御できるものではありません。そのため、前述の「前回のLCPが完了してから次回のLCPが完了するまでに出力されるREDOログのサイズ調整」は、LCPの実行速度をパラメータで調整することで制御します(*3)。
[*3] 通常、LCPは繰り返し実行されているため、これ以上頻度を上げることはできません(TimeBetweenLocalCheckpointsパラメータでLCPの頻度を制御できるが、デフォルト設定では4Mバイトのデータ更新が行われる毎にLCPが実行される)。
LCPの実行速度を向上させるには、LCPが使用するディスクI/O帯域を増加します。具体的にはMinDiskWriteSpeed、MaxDiskWriteSpeed、MaxDiskWriteSpeedOtherNodeRestart、MaxDiskWriteSpeedOwnRestartパラメータを増加させます。また、これらのパラメータを調整する際はndbinfo.disk_write_speed_baseテーブルの情報が役に立ちます。ndbinfo.disk_write_speed_baseテーブルを参照すると、LCP、GCPによって書き込まれたデータ量などを確認できます。それぞれのパラメータやndbinfo.disk_write_speed_baseテーブルの詳細については、マニュアルを確認してください。
バックアップファイル出力用の領域
バックアップファイル出力用のディスク領域には、1世代あたりDataMemoryの3倍程度のサイズを見積ります。
バックアップファイルには、第4回で解説したように「データノードが保持しているデータ」と「バックアップ取得中に実行されたトランザクションによる変更」が含まれます。「バックアップ取得中に実行されたトランザクションによる変更」は更新処理量に依存するため一律に決まるわけではありません。しかし、前述のGCPによるREDOログ出力と同様に1回のLCPが完了する間にバックアップの取得が完了すると仮定して必要領域を考えると、安定稼働のためのマージンを含めて1世代あたりDataMemoryの約2倍の領域が必要となります。そのため、「データノードが保持しているデータ(=DataMemory)」と合わせて1世代あたりDataMemoryの3倍の領域を確保しておきます。
また、データノードのCompressedBackupパラメータを設定することでバックアップファイルの出力を圧縮し、使用するディスク容量を抑えることもできます。
おわりに
今回は、MySQL Clusterのサイジングについて解説しました。第7回では、MySQL Clusterのレプリケーションについて解説する予定です。
※本稿において示されている見解は、私自身の見解であって、私の所属するオラクルの見解を必ずしも反映したものではありません。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
