ネットワーク・インフラの構成
ネットワーク・インフラの構成
Hadoopクラスタを構成するサーバー台数が多い場合、1つのスイッチでは収容しきれないため、複数のスイッチを使う構成になります。通常は、図1に示すように、サーバー・ラックごとにスイッチ(サーバー機を直接収容するラック・スイッチ)を設置し、ラック間を接続するスイッチ(コア・スイッチ)に収容する、2層構成になります。
|
|
| 図1: Hadoopクラスタのネットワーク構成(サーバー台数が多い場合) |
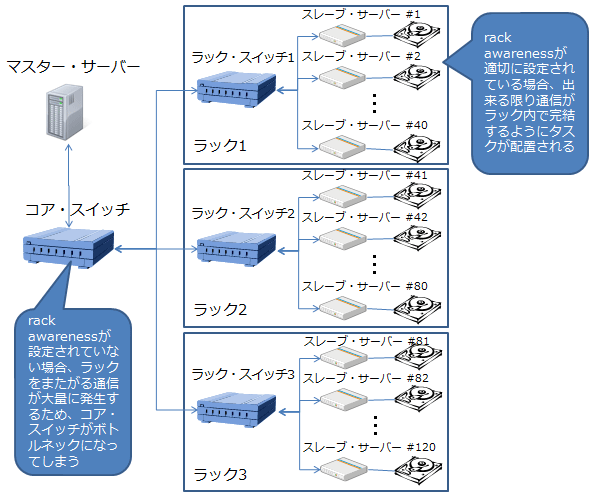
ここで重要なポイントは、コア・スイッチがHadoopクラスタ全体のボトル・ネックにならないようにする必要があるということです。
Hadoopは、MapReduceの実行時にサーバー同士の通信ができる限り同一ラック内で完結するようにタスクを配置する「rack awareness」と呼ぶ機能を持っています。rack awarenessを有効にするためには、あらかじめサーバーのアドレスとラックを対応付けておく必要があります。IPアドレスやホスト名をラックと対応付けておくと便利です。
マスター・サーバーの冗長化
Hadoopの現在の実装では、HDFS(Hadoop Distributed File System)全体を統括するNameNodeデーモンと、MapReduceジョブの実行を管理するJobTrackerデーモンは、Hadoopクラスタ内にただ1つ存在する構成になっています。
これは、もしこれらのデーモンを動かしているマスター・サーバーに障害が発生すると、Hadoopクラスタの機能が停止してしまうことを意味します。将来は複数のマスター・サーバーが協調して動くように拡張する計画もありますが、現時点では何らかの対処が必要です。
マスター・サーバーを冗長化する方法はさまざまですが、ここでは、「DRBD」(Distributed Replicated Block Device)と「Heartbeat」を組み合わせたHA(高可用性)構成を紹介します。DRBDとHeartbeatは、いずれもLinuxで動作するオープンソースです。
DRBDは、指定したパーティションを対象に、ネットワーク経由のミラーリング(RAID1)を実現します。本番系のサーバーに書き込まれるブロック・データの複製を、データが書き込まれるタイミングでリアルタイムに、待機系のサーバーに転送して書き込みます。
一方、Heartbeatは、サービスの冗長性を確保するソフトウエアです。HAクラスタを構成する複数のサーバー機は、1つの仮想IPアドレスを共有します。これらのサーバー同士が相互にサービス稼働状況を監視し、本番系のサーバーに障害が発生した際には、待機サーバーが処理を引き継ぎます。
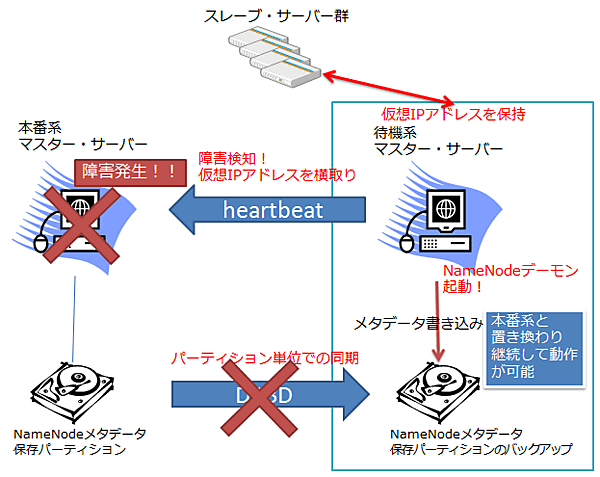
図2に、DRBDとHeartbeatを組み合わせた、マスター・サーバーの2重化構成を示します。DRBDは、NameNodeなどのデーモンが管理しているメタデータ(属性データ)のミラーリングを常時行っています。また、Heartbeatによって、本番系のマスター・サーバーは仮想IPアドレスで動作し、待機系のマスター・サーバーによって常時監視されています。
もし本番系のマスター・サーバーに障害が発生すると、図3に示すように、待機系のマスター・サーバー側でNameNodeなどのデーモンが立ち上がり、即座に仮想IPアドレスが待機系に引き継がれます。このようにして、マスター・サーバーに障害が発生した時にも、Hadoopクラスタは稼働し続けます。
|
|
| 図2: DRBDとHeartbeatを組み合わせた、マスター・サーバーの2重化構成 |

|
|
| 図3: Heartbeatによるフェール・オーバー |
関連記事
仮想環境特化のストレージベンダー、米国Tintriがオールフラッシュストレージを発表
2015年8月21日 20:43
NEC、省電力性能に優れた1Way空冷式スリムサーバなどExpress5800シリーズ3機種を新発売
2013年7月6日 2:00
IIJ、「IIJドキュメントエクスチェンジサービス」の機能を拡充、データを遠隔地に自動バックアップする「DRオプション」を提供開始
2013年8月29日 2:00
EMCジャパン、エントリー向けユニファイド・ストレージ「VNXe3150」を提供開始
2012年10月2日 2:00
EMCジャパン、次世代ITプラットフォームの実現を支援する新製品群とオープンソースに関する取り組みを発表
2015年6月27日 2:00
Red Hat Enterprise Linux 7を知ろう
2015年12月21日 7:00
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
