性能監視を活かすために
性能監視を活かすために
性能情報を得るのがゴールではない
SNMPによって機器毎の詳細な性能情報を収集できたとしても、この情報を適切に活用することができなければ意味がない。
ともすれば手段が目的化してしまいがちなのは運用管理に限った話ではないが、詳細な性能監視を行うのは、障害の兆候をいち早くつかんで未然に対処するなど、ユーザーに対して提供するサービスの質を向上させるためである。情報収集自体が目的ではないので、最終的なサービスレベルの向上につながらないと意味がないことは忘れてはならない点だ。
異常の兆候をリアルタイムで発信するツールも
データセンターでは、「既に性能情報の収集を始めている」というところも決して少なくはないのだが、そうしたデータセンターでも「性能情報を単に収集し、記録しているだけ」という段階にとどまっているところが多いようだ。この場合、ユーザーからの連絡で障害発生を知り、その対処の過程で収集した正常情報を参照して障害個所を特定する、といった事後対応のための材料として性能情報を利用している。
しかし、リアルタイムで情報分析を行うことができれば、ユーザーからの連絡を待つまでもなく、処理性能やレスポンスが低下しつつある状況をつかみ、問題が顕在化する前に対応を始めることも可能なはずだ。これには、性能監視のためのツールが適切な可視化機能などを備え、リアルタイムで飛び込んでくる性能データから異常の兆候を抽出して的確なアラートを発してくれる必要がある。
市場には既にこうした機能を持つツールも提供されているのだが、SNMPの有用性があまり周知されていないのと同様に、こうした高度なツールの存在を知らないユーザーが少なくないことは残念なことだ。
運用監視ツール側に“平常な状態”を学習させる
クラウドサービスでは、「ユーザーの平常時のリソース使用量はピーク時の半分以下である」という前提に立って、できる限り多数の仮想サーバを物理サーバ上に集約する必要がある。こうしないと物理サーバのリソース利用効率が向上しないためだが、こうした環境でユーザーに提供するサービスレベルを維持するためには、個々の仮想サーバの稼働状況を詳細に監視し、リソース使用量増加の兆候をいち早くつかんだ上でライブマイグレーション等の対応を行う必要がある。
こうした運用を行うためには、仮想サーバレベルでの詳細な性能監視が必須だが、仮想化ソフトウェアの管理ツールでも、リソース割り当ては詳細にできても実際のリソース消費量をリアルタイムにモニタリングしたり、リソース逼迫を的確なタイミングで警告してくれたりといった機能は意外に実装されていなかったりもする。この点からも、性能監視機能が充実した運用監視ツールを別途導入することの意義は大きいといえる。
さらに言えば、的確なアラートを発するためには、単純な閾値方式ではなく、よりインテリジェントな可視化機能が実装されていることが望ましい。システムの処理性能は一定ではなく、様々な要因で変動する。一瞬性能が低下しても、すぐに回復するようであれば特に運用管理者側で対処する必要もない場合も多いだろう。
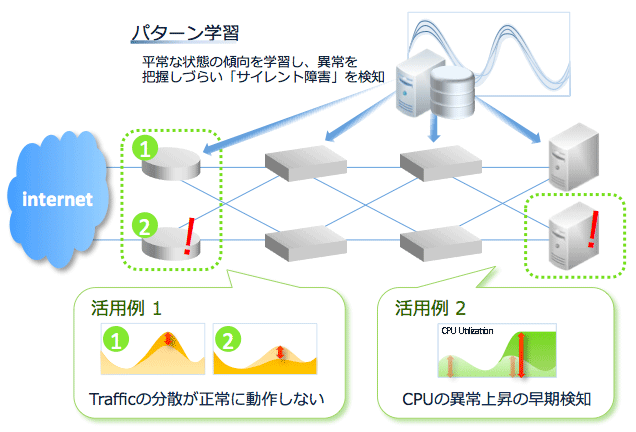
単純なツールではこうしたごく短時間の性能変動も逐一全てを拾ってしまい、アラートを発してしまうため、重要な情報が大量のアラートの山に埋もれてしまうということも起こりかねない。運用監視ツール側に“平常な状態”を学習する機能があれば、細かな変動についてはマスクし、運用管理者が対処すべき重要な変化を捉えたときにのみアラートを発することで、運用管理者の負担を大幅に軽減することが可能になる。
ユーザーの視点からも、問題になるのは性能の絶対値よりもむしろ変動だということがいえる。いつもと同様のレスポンスが得られていれば問題ないので、変動に注目するのは運用管理のアプローチとしても理にかなっている。また、「障害というまでのレベルではないが性能劣化が始まっている」といったいわゆるサイレント障害は、「性能指標の閾値を超えてはいないが、いつもよりは低下している」という状況だと見なせるが、こうしたサイレント障害も、平常時のデータを踏まえたトレンド比較の機能を備えていれば検出できる。
|
|
| 図3:サイレント障害(クリックで拡大) |
“障害が起こる前に解決”が望まれるこれからのデータセンター
現在のデータセンターでは、ユーザーが望む高度な機能を可能な限り低コストで実現しないと競合優位に立つことはできないという厳しい競争環境にある。一般向けにサービスを提供するデータセンター事業者はもちろん、企業内データセンターであってもコスト削減は最優先課題だろう。
ユーザーが期待するサービスレベルを維持しつつ運用管理コストを削減するためには、インテリジェントなツールの活用による作業の自動化が不可欠だが、前述のような高度な解析機能を備える性能監視ツールがあれば、障害発生の連絡を受けてから泥縄的に対処するのとは別次元の効率的な障害対応が可能になる。
こうした体制ができあがってしまえば、ユーザーからはまるで障害が起こる前に解決してしまうかのような高いサービスレベルが実現されることになる。こうしたサービスこそが、これからのデータセンターに望まれているものだろう。
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
