Hadoopコースを攻略しよう(環境構築編)

この記事では、「Tuning Maniax 2014 - 蒼き調律者たち」Hadoopコースに参加される方に向けて、 MapReduceプログラムの開発環境と、Azure HDInsightを使ったHadoopクラスターの構築方法を紹介します。
いざ参戦、チューニング・マニアックスHadoop編
さてこの競技、簡単に言えば以下のようなものです。
総計1TBのWebアクセスログ(を模して生成されたデータ)を解析し、次の3項目を抽出する時間を競う
- アクセス数の多いURL:上位10件
- 多く利用されているユーザーエージェント:上位10件
- URI毎の平均レスポンスタイム:下位10件(時間が長い方から10件)
解析のための環境としては、Microsoft Azure HDInsightサービスをご利用ください。その上で、どのような処理方式を選択されるかは参加者の自由!オーソドックスにJavaで書くも良し。Streaming APIを駆使して自分の得意な言語で楽しむもまた良し。当然HiveやPIGでの挑戦もOKです。
え、Dryadで殴り込み?もちろん大歓迎!
必要になる環境
この競技に参加するには、次のようなものが必要になります。
- Microsoft Azureのサブスクリプション
- MapReduceプログラムの開発や、HDInsightクラスターの作成・ジョブ投入等の作業を実行するためのWindowsマシン(「開発環境」)
- Hadoopクラスターそのもの。
1. については、大会に参加される皆さんは既に用意されていると思いますので、この記事では2.と3.についてその方法を紹介します。
開発環境の作成
まずは、Windowsマシンを一つご用意ください。Azure管理ポータルへアクセスしてHDInsightクラスターを作成するだけならブラウザさえあれば良いのですが、HDInsightを活用する際に欠かせない以下のツールがWindows環境で動作するのです。
- Windows Azure PowerShell
- Microsoft HDInsight Emulator for Windows Azure
これらは、普段お使いのPCにそのままインストールしても構いませんが、「自由にソフトをインストールできない環境である」「Surface 2を使っている」「MacBookで生きている」等の理由でインストールできないこともありましょう。
そういったケースを想定して、今回は開発環境自体もAzure仮想マシンで構築する方法をご紹介します。
仮想マシンの作成
Azure仮想マシンのギャラリーには、様々な仮想マシンイメージが用意されていますが、おすすめは最新のWindows Server 2012 R2です。
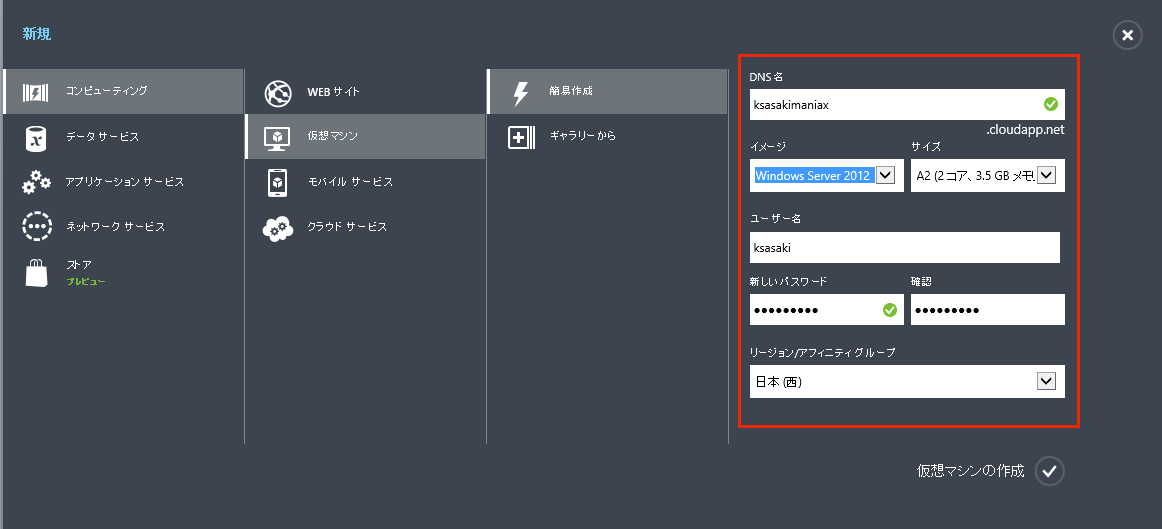
Azure管理ポータルで「新規」→「コンピューティング」→「仮想マシン」→「簡易作成」とクリックし、必要事項を記入します。
※記事中の図をクリックすると拡大表示します。
- 「DNS名」に入力した名前が、仮想マシンのホスト名にもなります。リモートデスクトップ接続する時に、この名前を指定することになります。
- 「イメージ」は”Windows Server 2012 R2 Datacenter”を選択してください。上の図では「R2 Datacenter」の部分が見切れてしまっていますが…
- 「サイズ」は「基本」階層の"A2"(2コア、3.5GBメモリ。以前は”Mサイズ”と呼んでいたもの)あたりがおすすめです。A1(1コア、1.75GBメモリ)では、EclipseやHDInsight Emulatorを動かすには少々不足かもしれません。
- 「ユーザー名」と「新しいパスワード」の部分には、管理者となるユーザーの名前とパスワードを指定します(“Administrator”は無効化されています)。
- 「リージョン/アフィニティグループ」は、仮想マシンの配置場所の指定です。現在、日本には関東と関西の2リージョンありますので、どちらかをお使いください。
※なお、「日本(西)」は東より少々お値段控えめとなっております。
ゲストOSの日本語化
Azure仮想マシンのギャラリーにある標準イメージは、今のところすべて英語版です。簡単に日本語化できますので、方法をご紹介します。
- 仮想マシンが出来上がったら、管理ポータル下の黒帯から「接続」を選んでリモートデスクトップ接続します。
- ログオンしたら、左下のスタートボタンを右クリックして”Control Panel”をクリックします。
- コントロールパネルの”Add a language”をクリックします。
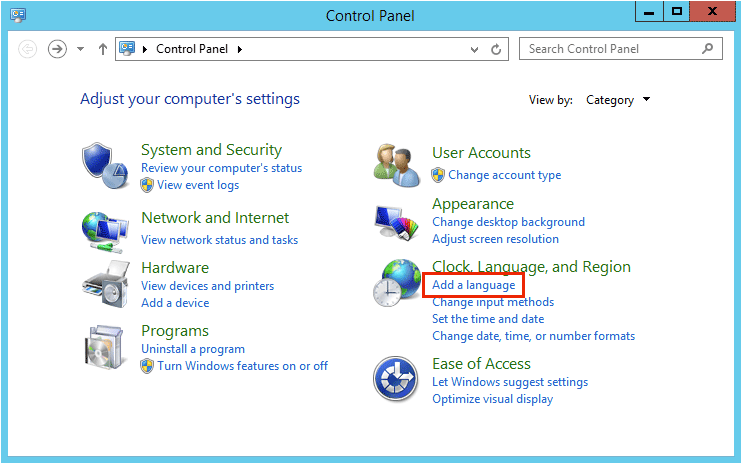
- 次の画面でも”Add a language”をクリックして、日本語を追加します。また、”Move Up”で英語より上に持ってきます。さらに”Options”をクリックします。
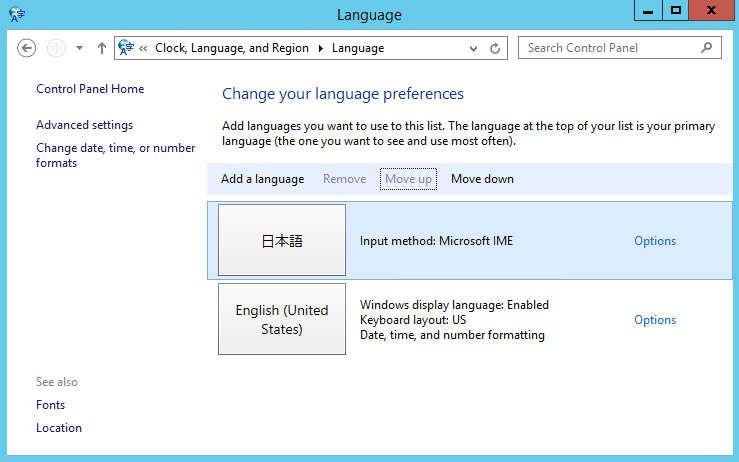
- ”Download and install language pack”をクリックします。

- この状態で、しばらく時間がかかりますのでお待ちください。
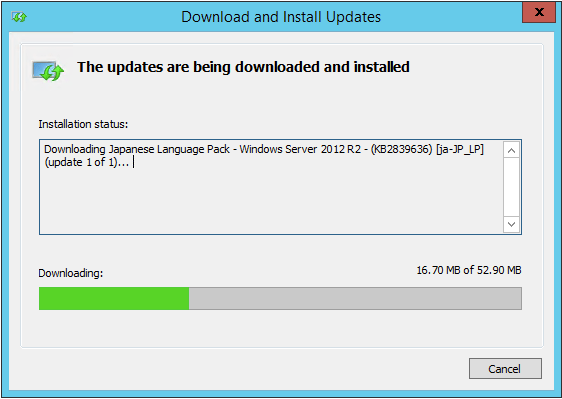
言語パックのインストール後、再度ログオンすると見事日本語環境になっているはずです。実は、ユーザー毎の表示言語を日本語にしただけで、システムロケールは英語のままなのですが、あまり問題ないのでこのまま行くことにします。
Web Platform Installerのインストール
では、必要な各ソフトウェアをインストールしていきます。まずは、”Web Platform Installer(WebPI)”です。これを使うと各種ソフトウェアパッケージを、その依存モジュールと共にダウンロード・インストールしてくれるものです。
このリンクからwpilauncher.exeを実行してください。
> http://go.microsoft.com/fwlink/?LinkId=255386
インストールが完了すると、自動的にWebPIが立ち上がってきます。
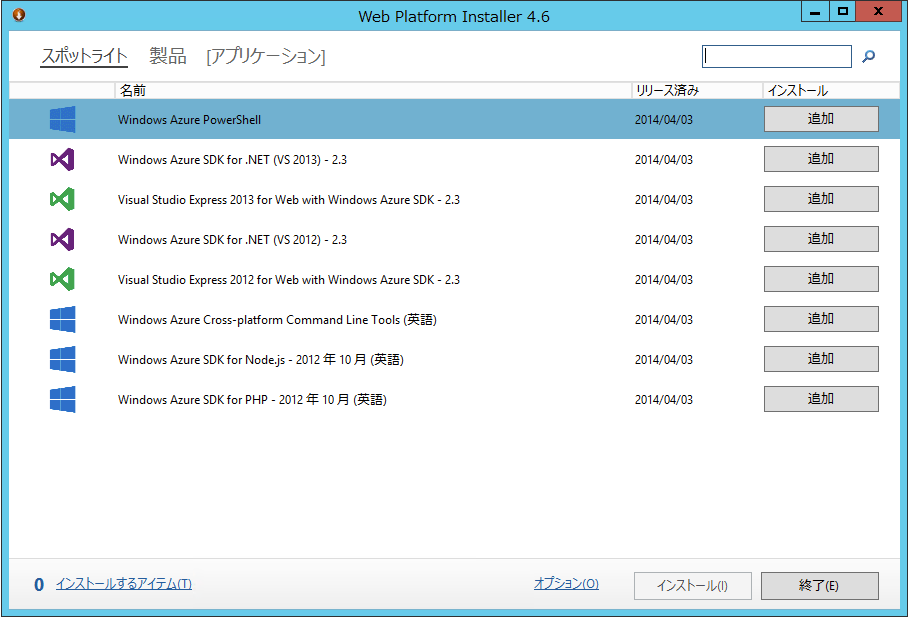
Windows Azure PowerShellと、Microsoft HDInsight Emulator for Windows Azureの二つを「追加」して「インストール」をクリックしてください。

※HDInsight Emulatorは”hdinsight”で検索すると出てきます。
こうなれば完了です。
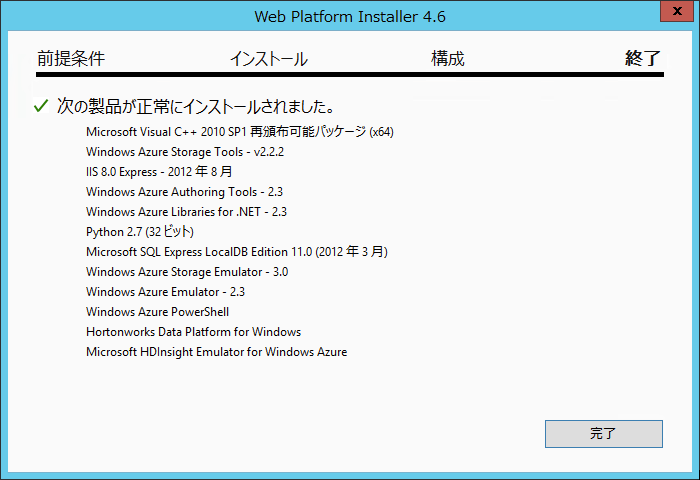
HDInsight EmulatorはC:\Hadoop配下にインストールされます。
また、C:\Hadoop\javaにJDKがインストールされますので、PATHを通しておきましょう。「管理者として実行」したコマンドプロンプトで次のコマンドを実行するのが楽です。
setx PATH "%PATH%;c:\Hadoop\java\bin" /m
Eclipseのインストール
MapReduceプログラムを書くために、Javaの開発環境を用意しましょう。メモ帳+JDKでも良いのですが、楽をするためにここではEclipseを使おうと思います。
“Eclipse IDE for Java Developers”の”Windows 64 Bit”を以下のリンクからダウンロードします。
> Eclipse IDE for Java Developers”の”Windows 64 Bitのダウンロード
ダウンロードが完了したら、ZIPファイルのブロックを解除します。
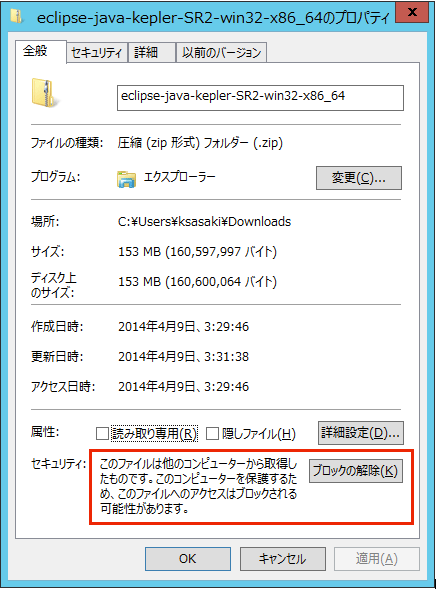
その後、Cドライブのどこか適当な場所へ展開してください。筆者はC:\opt\eclipseに置きました。
※なお、Dドライブには展開しないでください。Azure仮想マシンのDドライブは、BLOBストレージへ永続化されないテンポラリディスクです。再起動したぐらいでは消えませんが、Azure側のメンテナンスのタイミングなどで内容が失われることがあります。
Eclipseに限りませんが、よく使うプログラムは、タスクバーにピン留めしておくと便利です。

ストレージクライアントツールのインストール
HDInsightはBLOBストレージを舞台に動作しますから、何らかのストレージクライアントツールがあると大変便利です。よく利用されるツールとしては、例えば以下のようなものが挙げられます。
どれでもお好きなものをインストールしてください(筆者はたまたまCloudXplorerを利用していますが、もちろん他のツールでも構いません)。
以上で、ローカルマシン(といってもクラウド上にありますが)でMapReduceプログラムを開発・テスト実行するための環境が出来上がりました。
Azure HDInsightクラスターの作成
では、いよいよAzure上に本物のHDInsightクラスターを作成してみましょう。
Windows Azure PowerShellの初期設定
Azure PowerShellを使うと、Azure管理ポータルサイトで行うような各種管理操作(仮想マシンの作成・削除・起動・停止等)を、コマンドラインで行うことができます。もちろん、今回の主題であるHDInsightの操作もばっちりです。
これらの操作は、Azureの「サービス管理API」を呼び出すことで行われるのですが、その際は必ず認証が必要です(匿名のリクエストで仮想マシンの作成や削除ができては困りますから)。
方法は以下の2種類あります。
- Azure Active Directoryで認証する。
- クライアント証明書で認証する。
前者の方が手軽なのですが、認証に有効期限がありますので、定期的にコマンドを発行して更新しなければなりません。
今回は後者の方法をご紹介します(前者の方法は以前、筆者のブログで解説しましたのでよろしければご覧ください)。
まず、Azure PowerShellを起動してください。デフォルトではスタート画面にはピン留めされていませんので、アプリ一覧画面からアイコンを探すか、スタート画面で「powreshell」で検索してください。そしてピン留めしてしまいましょう。
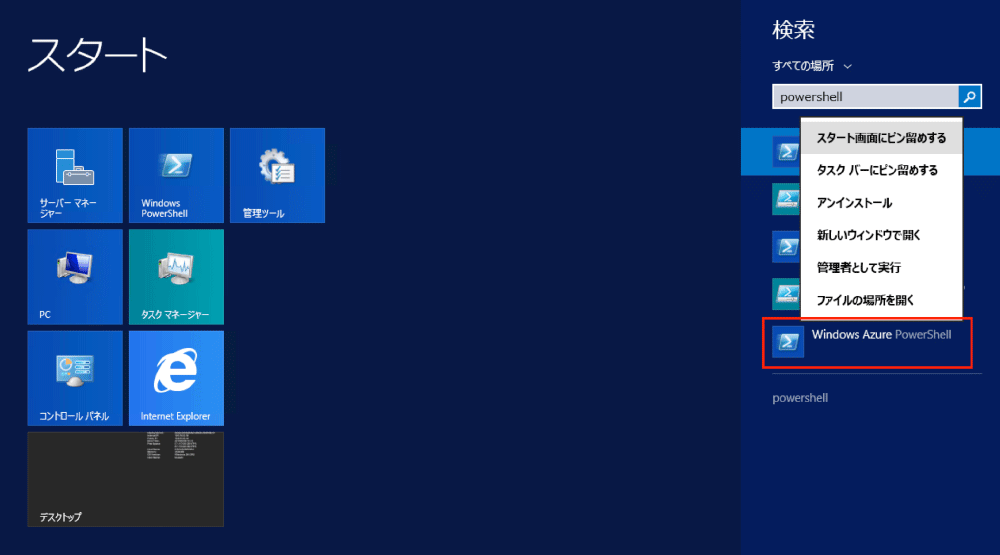
こんなふうに聞かれたら、”A”でお願いします(“R”だと何度も聞かれます…)。

まず、次のコマンドを実行してください。
Get-AzurePublishSettingsFile
すると、Azure管理ポータルのログオン画面が出てきますので、管理ポータルへのログオンに使用するユーザー名とパスワードを入力します。

すると、拡張子が”.publishsettings”のファイルが降ってくるのでこれを保存します。

保存した. publishsettingsファイルを次のコマンドでインポートします。
Import-AzurePublishSettingsFile 先ほど保存した.publishsettings
以上で、Azure PowerShellの初期設定は完了です。
ストレージアカウントの作成
HDInsightはデフォルトのファイルシステムとして、HadoopのHDFSではなく、AzureのBLOBストレージを利用します。そのため、HDInsightのクラスターを作成する前に、ストレージアカウントを作っておきましょう。
また、残念ながらHDInsightはまだ日本リージョンで利用できませんので、東南アジアリージョンを利用してください(事務局から公開される「解析対象ファイルセット」も東南アジアリージョンのストレージアカウントに配置されます)。
作成手順は次の通りです。
- 1. Azure管理ポータルで「新規」→「ストレージ」→「簡易作成」とクリックし、必要事項を記入します。
- 「URL」: 任意の名前を指定します。
- 「場所/アフィニティグループ」: 「東南アジア」を指定します。
- 「レプリケーション」: デフォルトのままでも構いませんが、「ローカル冗長」にすると少しお安くなります。
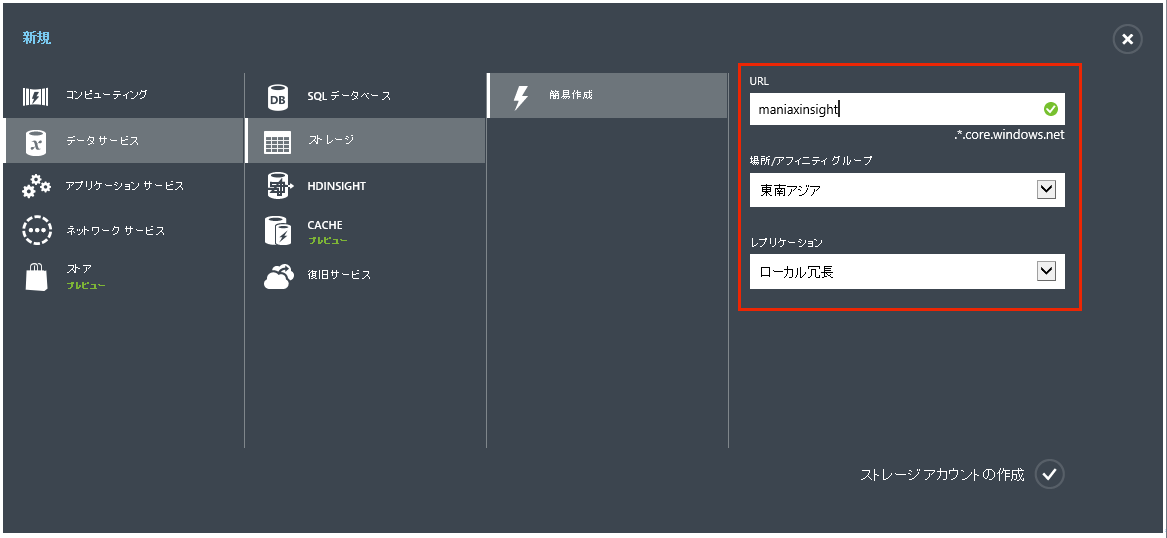
- 2. 「ストレージアカウントの作成」をクリックします
クラスターの作成
ストレージアカウントの作成が完了したら、HDInsightクラスターを作成しましょう。
作成手順は次の通りです。
- 1. Azure管理ポータルで「新規」→「データサービス」→「HDINSIGHT」→「簡易作成」とクリックし、必要事項を記入します。
- 「クラスター名」:これから作成するクラスターの名称を決めます。
- 「クラスターサイズ」:データノードの数を指定します。サイズはA3(L)サイズ固定です。
- 「クラスター ユーザー名」: これは簡易作成する場合”ADMIN”に固定されています。
- 「パスワードの確認」: ADMINユーザーのパスワードです。最低10文字必要です。
- 「ストレージアカウント」: 先ほど作成したストレージアカウントを指定します。ストレージアカウントと同じリージョンに、HDInsightのクラスターも作成されます。
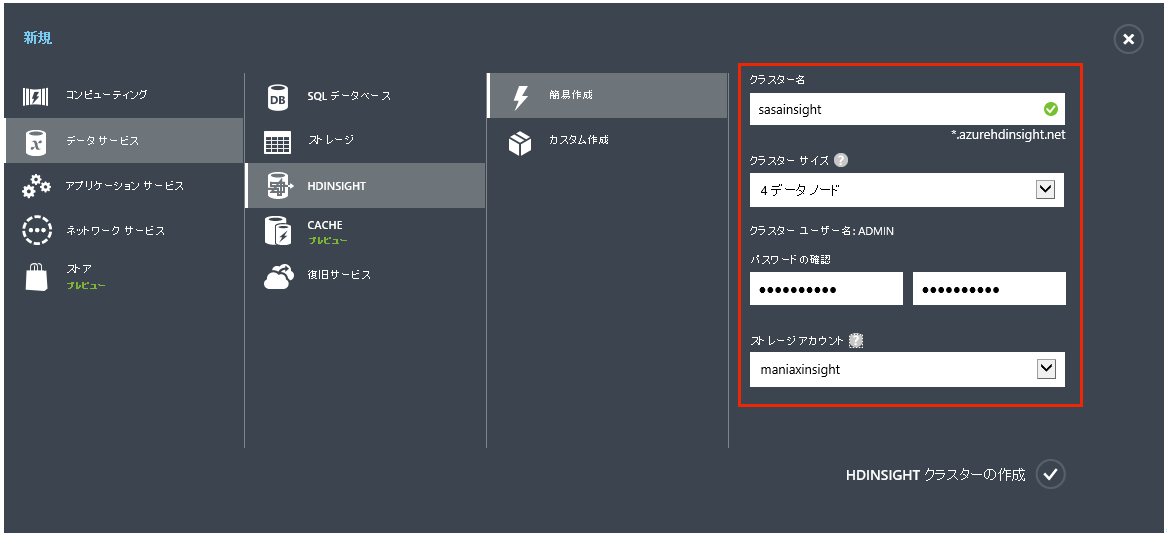
- 2. 「HDINSIGHTクラスターの作成」をクリックすると、クラスターの作成が始まります。
リモートデスクトップの有効化
HDInsightへのジョブ投入は、Azure PowerShellを使ってリモートに行うことができますが、リモートデスクトップを有効化しておくとHadoopのネームノードに直接ログオンしてhadoopやhiveコマンドを使うこともできます。何かと便利ですから、とりあえず有効にしておきましょう。
手順は次の通りです。
- 1. Azure管理ポータルでHDInsightクラスターを選択し、「構成」タブで「リモートを有効にする」をクリックします。
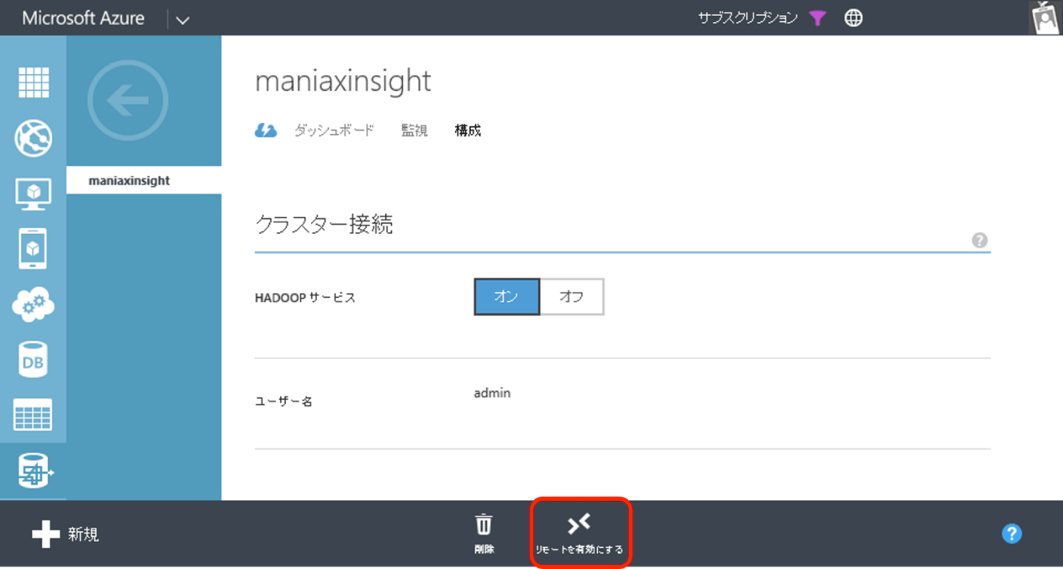
- 2. 「リモートデスクトップの構成」画面でユーザー名・パスワード・有効期限を設定します。なお、ここで指定する「ユーザー」は、クラスター作成時に指定する管理者とは別の「リモートデスクトップ接続専用のユーザー」です。

以上です。設定は数分で有効になります。
「接続」をクリックすると、リモートデスクトップ接続ファイルが降ってきます。これを使ってログオンすると、HDInsightがWindows Server 2012 R2で動いていることがわかります。
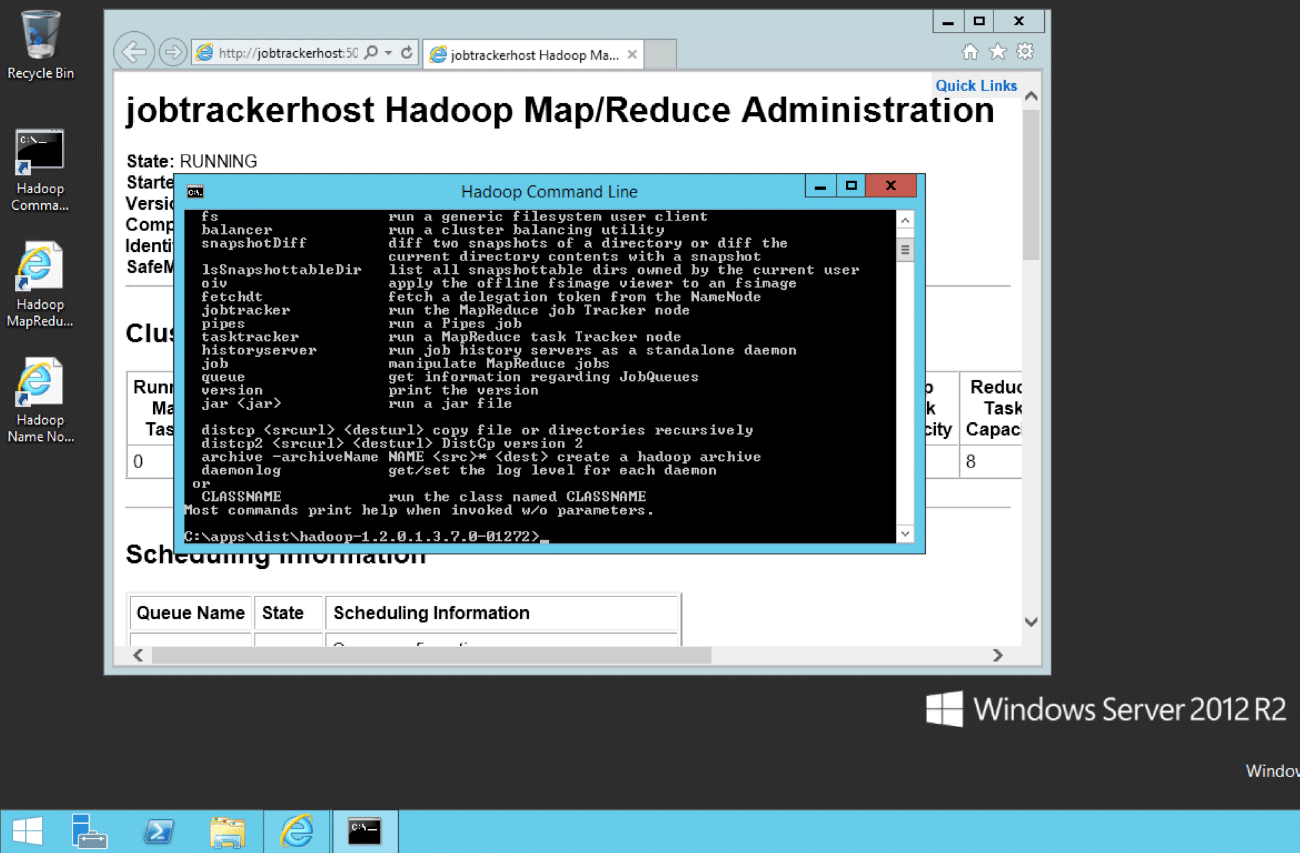
なお、このようにネームノードにログオンして自由にhadoopコマンドを使うことができるのですが、一つ気を付けていただきたいことがあります。HDInsightのノードは、すべてAzureの「Workerロールのインスタンスである」という点です。
Azureをご利用の方ならご存知の通り、Workerロールのインスタンスストレージは、BLOBに永続化されない一時的なディスクです。Azure側のメンテナンス作業などのタイミングで、内容がクリアされてしまうことがありえます。
そのため、例えばネームノード上でジョブ実行用のバッチファイルを作成したりするのはおすすめできません。
サンプルジョブの実行
最後に、HDInsight上でのジョブ実行方法をご紹介します。HDInsightでは、/example/jars/hadoop-examples.jar にいくつかサンプルプログラムが含まれています。
中でも最も基本的で、「MapReduceのHelloWorld」ともいえるWordCountプログラムを実行してみましょう。テキストファイルに含まれる単語の出現回数を計測するものです。
題材としては、これもHDInsightにあらかじめ用意されている、/example/data/gutenberg/davinci.txtを利用し、計測結果は/out/wordcountへ出力するものとしましょう。
手順は次の通りです。
- 1. Azure PowerShellを起動します。
- 2. Get-AzureHDInsightClusterを実行して、先ほど作成した自分のHDInsightクラスターの名前を確認しておきましょう。
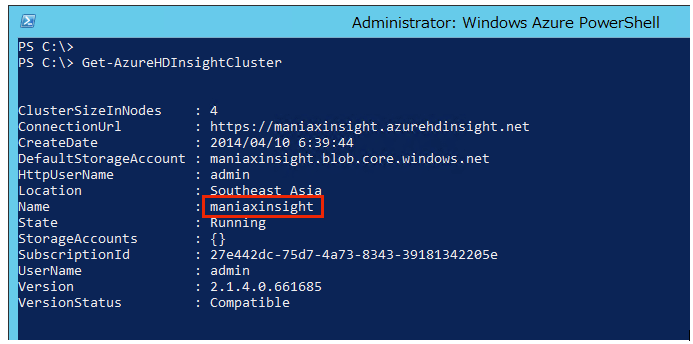
- 3. 次のコマンドを実行します。クラスター名は前の手順で確認した名前を指定します。
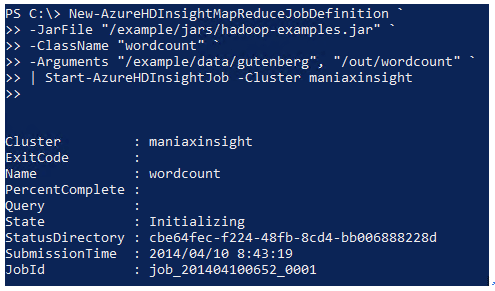
New-AzureHDInsightMapReduceJobDefinition ` -JarFile "/example/jars/hadoop-examples.jar" ` -ClassName "wordcount" ` -Arguments "/example/data/gutenberg", "/out/wordcount" ` | Start-AzureHDInsightJob -Cluster クラスタ名
※PowerShellでは`(バッククォート)が継続行記号です。 - 4. ジョブが投入されると、このような情報が返ってきます。この時点ではまだジョブが走り出しただけであって、完了したわけではありません。
- 5. ジョブの状況を確認してみます。クラスター名とジョブIDを指定して、次のようにコマンドを実行します。
Get-AzureHDInsightJob -Cluster クラスター名 -JobId ジョブID
どうやらジョブは完了しているようです。
では、出力結果を見てみましょう。先ほどインストールしたストレージクライアントツールで、/out/wordcountを見てみます。
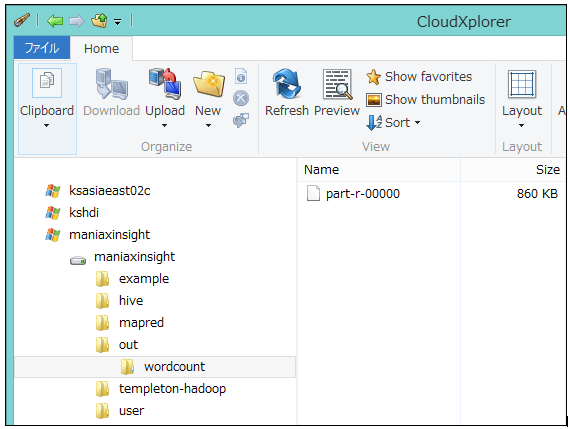
part-r-00000 というファイルが確認できると思います。これが、MapReduceのReduceフェーズの結果として生成されたファイルです。開いてみると、単語とその出現回数が淡々と記録されていることがわかります。
"(Lo)cra" 1 "1490 1 "1498," 1 "35" 1 "40," 1 "A 2 "AS-IS". 1 "A_ 1 "Absoluti 1 (以下略)
なお、Hadoopが出力する個のファイルは改行コードがUNIX式のLFになっています。Windowsのメモ帳で開くと全部つながって一行になってしまうので、IEで開くか、あるいはUNIX式の改行コードに対応した何らかのエディタをお使いください。
筆者は@kaoriyaさんが配布されているGVIMを愛用しています。
次回は
今回は、開発環境の準備とHDInsightのクラスター作成、簡単なサンプルジョブの実行方法までをご紹介しました。次回はチューニング・マニアックスHadoop編の問題に即したMapReduceプログラムの作成方法を解説する予定です。
【関連リンク】



連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- Hadoopコースを攻略しよう(HDInsightによる大量ログ解析編)
- PowerShellを使用したAzureの管理
- Tuning Maniax 2014参加者必見!スタートアップセミナーの資料を一挙掲載
- Windows Server コンテナ始動!
- はじめてのWindows Azure Accelerator for Web Roles
- 上位入賞者たちはどうやってチューニングしたのか!?Tuning Maniax総評
- Build 2013レポートとWindows Azureの2013上半期アップデートを総復習!
- WebMatrixを使ってWordPressを動かそう
- Windows AzureにPythonのアプリケーションをインストールする(クエスト9)
- Windows Azure上にWindowsインスタンスを立ち上げる(クエスト4)