SQLの解析結果を保持する仕組みの違い
SQLの解析結果を保持する仕組みの違い
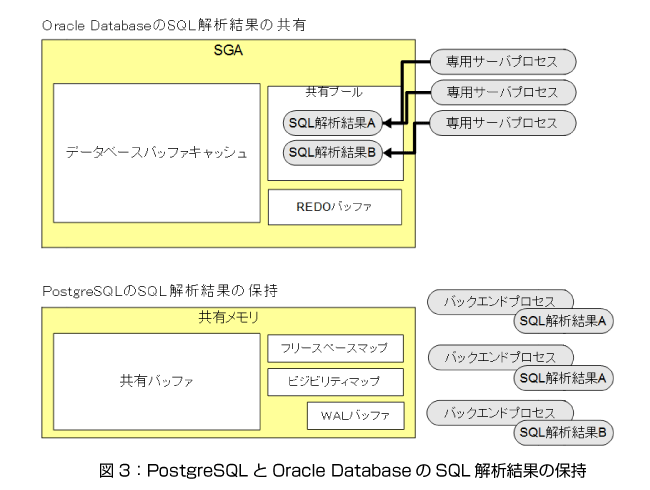
PostgreSQLもOracle Databaseも、SQLに指定されている表や列などがデータベースに存在しているかどうか、アクセスするデータが物理ファイルのどの位置に格納されているのかを確認するという解析処理を実施し、SQLを実行しています。
Oracle DatabaseではSQLの解析結果は共有プールというメモリ上に保管され、共有利用することができます。同じSQLが共有プール上に既に存在している場合、SQLの解析を行う必要はありません。これは、同時に多数のユーザーがOracle Databaseにアクセスした場合に、SQLの解析による性能低下を防ぐ仕組みとして実装されているからです。
一方、PostgreSQLではSQLの構文解析結果を共有する機構は存在しないため、毎回SQLの解析を行うという実装になっています。
読み取り一貫性と同時実行性の仕組み(ロールバックセグメント/追記型構造)の違い
RDBMSにおいて、読み取り一貫性と同時実行性の両立は非常に重要な課題です。読み取り一貫性を保証するため変更処理で表ロックを取得してしまうと同時実行性は低くなりますし、同時実行性を優先して一貫性のないデータを出力しては本末転倒です。
PostgreSQLやOracle Databaseでは読み取り一貫性と同時実行性の両方を実現できる設計となっていますが、実装方法は大きく異なります。
Oracle Databaseでは、DML(INSERT/UPDATE/DELETE)を行って変更する前の情報はロールバックセグメントという領域に保存する仕組みとなっています。あるセッションの変更がコミットされていない時に、ほかのセッションが同じ情報に参照すると、ロールバックセグメントに保存された変更前の情報を使って、参照時に確定されている情報だけを参照することができます。
また、ロールバックセグメントは循環方式で変更前の情報を保存する仕組みのため、変更前の情報を効率よく保存し、読み取り一貫性を実現しています。以前はロールバックセグメントのチューニングは非常に難しいものでしたが、Oracle9iより実装された自動管理UNDO表領域によってチューニングの手間が低減されています。
一方、PostgreSQLではロールバックセグメントのように、変更前の情報を専門に保存する仕組みがありません。PostgreSQLの表データは追記型であるため、更新、削除の場合でも以前の行データは削除されず、ロールバックに必要な情報として残されています。そのため、あるセッションの変更がコミットされていない時に、ほかのセッションが同じ情報に参照すると、以前の行データを参照することで、読み取り一貫性を保証しています。
この実装方法は非常にシンプルですが、追記型であるため表の領域が拡張してしまいます。このため、定期的に不要になったデータを削除するVACUUM処理を行う必要があります。
表が拡張しやすい仕組みと、VACUUM処理の負荷は、8.3で導入されたHOT機構によって大きく改善されています。8.3以降であれば、AUTOVACUUMに処理を任せても高いレベルの性能維持が可能です。
最後に
以上のように、同じRDBMSでありながらPostgreSQLとOracle Databaseにはそれぞれの特徴があり、実装時には特徴を理解しながら活用していくことが必要です。
まだまだ興味深いトピックが多々ありますが、残念ながら紙面の関係上、すべてを記載することができませんでした。両RDBMSの使い方について機会があればまたご説明したいと思います。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
