WEBrickの構造
WEBrickの構造
残念ながらWEBrickはあまりドキュメントがそろっていませんが、RubyリファレンスマニュアルのWebrickのページ(http://www.ruby-lang.org/ja/man/html/webrick.html)で代表的なクラスのメソッドが解説されています。
先ほどのhttpserver1.rbでは、HTTPServerクラスしか使っていないように見えますが、その中でいくつかのクラスが呼び出されています。
httpserver1.rbで呼び出される流れは図3のようになっています。
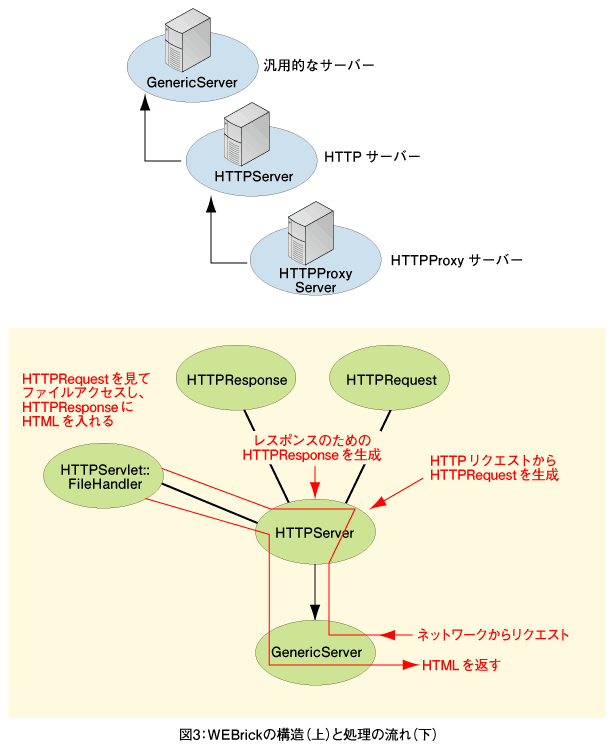
HTTPServerクラスの処理
実はWEBrickはHTTP以外のプロトコルのサーバーも作れるように、GenericServerというクラスを基底にしてHTTPServerクラスを作っています。GenericServerクラスが、TCP/IPの受付などを行い、その上でHTTPServerクラスがHTTP固有の処理を行います。
HTTPServerクラスでは、受け取ったHTTPリクエストからHTTPRequestクラスのオブジェクトを生成します。これにはアクセスしてきたWebブラウザの情報や、アクセス先のURLなどが入っています。さらにレスポンスを入れておくためのHTTPResponseクラスのオブジェクトを生成しておきます。
このHTTPRequestとHTTPResponseを、アクセスされたURLに対応するファイルを取り出すためのクラスであるHTTPServlet::FileHandlerクラスに渡します。
このようにURLとデータをつなげるクラスをハンドラーといい、標準ではHTTPServlet::FileHandler以外に、CGIを扱うHTTPServlet::CGIHandler、PHPのようにHTMLにRubyを埋め込んで処理するHTTPServlet::ERBHandler、直接Rubyのコードを実行するHTTPServlet::ProcHandlerが添付されています。
この部分を自作することで、コンテンツをファイルではなくデータベースに保存するようなWebサーバーを作ることができます。
HTTPServerクラスでは、初期設定ではHTTPServlet::FileHandlerを呼び出すようになっているので、HTTPRequestとHTTPResponseがセットされた後、HTTPServlet::FileHandlerが呼び出され、そこでファイルからHTMLが読み込まれます。この読み込まれたHTMLはMIME-Typeなど必要なヘッダと共にHTTPResponseに入れられ、HTTPServerに戻されます。
HTTPサーバーではこの内容を、HTTPプロトコルにあわせて整形して、クライアントに返します。
このようにWEBrickでは、非常にシンプルな流れでHTTPを処理しています。しかしこれだけでは、あまり動きがピンとこないでしょう。これはHTTPServerがほとんどの処理を自動でやってしまっているためです。
次回は、HTTPServerの動きをもっと詳しく追いながら、本格的なWebサーバーの構築を行います。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
