Japan Container Daysのキーノートで語られたCA、ヤフージャパン、メルカリの事例
コンテナを含むクラウドネイティブなシステムに関するカンファレンス、「Japan Container Days v18.04」が都内にて開催された。
2018年5月15日 10:51
コンテナを含むクラウドネイティブなシステムに関するカンファレンス、「Japan Container Days v18.04」が都内にて開催された。筆者もスタッフの一員として参加したこのカンファレンスでは、コンテナやKubernetesを中心としたオープンソースソフトウェアに関する技術解説、事例紹介などが行われた。サイバーエージェント、ヤフージャパン、メルカリ、マイクロソフト、グーグル、NEC、NTTなどのエンジニアが講師として登壇し、500名を超える参加者に向けてプレゼンテーションを行った。クラウドネイティブなオープンソースソフトウェアを推進するCloud Native Computing FoundationのCTOもこのカンファレンスのために参加し、CNCFが推進するソフトウェアやそれに向かう道筋などについて解説を行った。
サイバーエージェントの広告事業における事例
カンファレンス冒頭のキーノートセッションに登壇したのは、サイバーエージェントのインフラエンジニア、青山真也氏だ。青山氏はサイバーエージェントのインターネット広告事業部におけるワークロードを、性能要件が非常に高く、高速な処理を要求されると語る。そしてサイバーエージェントのエンジニアが「いつも何か新しいものに挑戦したがる」性格であることも明かした。そこから、Dockerによるコンテナ化への取り組みとKubernetesを利用した社内向けKubernetes-as-a-Service(KaaS)であるAKE(Adtech Container Engine)の開発に繋がったという経緯を説明した。
AKEのフィージビリティスタディは2016年頃から開始したそうで、当時はDocker Swarm、Kubernetes、Mesosなどのオーケストレーションツールが覇権を競い合っている状態であったと、青山氏は振り返った。2017年の7月にはKubernetesからCinderを永続的ストレージとして利用することが可能になり、OpenStackベースのプライベートクラウドを構築しているサイバーエージェントにとっては良いタイミングであったと思われる。ここで注目したいのは、最初のAKEは2名のエンジニアによって開発されたという事実だろう。

サイバーエージェントにおけるAKEの始まり
インフラストラクチャーであるOpenStackの他のコンポーネントとのインテグレーションも進み、現在ではすでに本番環境として15クラスターが稼働中であるという。OpenStackのプロジェクトであるMagnumやRancher、Red Hatに買収されたCoreOSが推進するTectonicなどのツールを使わずにHeatで構築したという部分の背景については、2017年12月に開催されたセミナーで青山氏が解説しているので参考にされたい。

Kubernetesを運用するツールの比較
参考:OpenStackのセミナーでコントリビューターたちが語ったOpenStackの未来
そしてAKEの特徴としてAdd onによる拡張性が紹介された。ログの収集にはElasticsearchとKibanaが、モニタリングにはDatadogとPrometheusが、そしてKubernetesの操作をより簡単にするHelmなどが活用されていると語った。
またコンテナのランタイムに関しても様々な組み合わせがあり、Dockerによるランタイム、CNCFがホストするcri-o、cri-oよりも少し上の位置付けとしてCNCFがインキュベーションするContainerdやrktなどをサポートするという。コンテナランタイムに関しては、同じくサイバーエージェントからスピーカーとして参加されたインフラエンジニアである長谷川誠氏によるセッションを、別記事として紹介したい。
複数のコンテナランタイムをサポート
コンテナで運用されているメルカリの画像認識機能
次に登壇したのは、メルカリの山口拓真氏だ。山口氏は「私はコンテナのエンジニアではなくて機械学習のエンジニアなので」と自己紹介し、会場に集まったエンジニアが主にコンテナに興味があることを意識しながらも、機械学習のプラットフォームとしてコンテナとKubernetesが、メルカリの画像認識において本番運用されていることを紹介した。

メルカリの機械学習エンジニア、山口氏
山口氏は機械学習アルゴリズムの一種であるCNN(Convolutional Neural Network)について、この技術がすでに1980年代に考案されていたことを紹介した。つまり基礎的なアイデアは以前から存在しており、GPUなどの実用的な演算リソースができたことで一気に実用に向かったことを紹介した。
CNNについてはこの記事を参考にされたい。
またメルカリにおける機械学習について、自身が担当した画像認識における要件を紹介。これはGPUを活用した画像認識で、ユーザーが出品を行う際の品物について、撮影された画像から自動的に品物の概要や色に関する情報を付加する機能の要件となるものだ。山口氏は社内のエンジニアから「とりあえずDockerfileを用意してください」とだけ言われたと語り、結果的にGCP、AWSの2つのパブリッククラウドを活用したマイクロサービスが構築された経緯を紹介した。

機械学習を使った画像認識の要件
構築された画像認識のためのシステムはGCPとAWSをまたがるように構築され、TensorFlow、Redis、Django、Spinnaker、Datadogなどで構成された高度なマイクロサービスとも言えるもので、それを可能にしたのは東京、ロンドン、サンフランシスコに分散された開発拠点が全社的なシステムの刷新時にマイクロサービスを使う方向にシフトしたことが大きいと説明した。
Dockerの使い方についても山口氏自身は「最初は全く素人でした」と説明したが、そこからKubernetesやSpinnakerを組み合わせたシステムの構築を実現したわけで、あらためてメルカリのエンジニアの底力を見せつけた形となった。
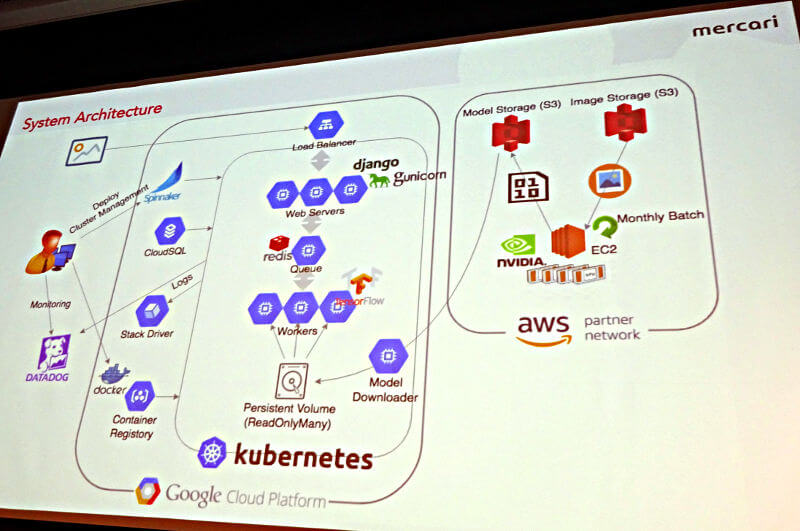
構築された画像認識システムの概要
山口氏は「機械学習エンジニアだけでもマイクロサービスによるシステム構築は可能である」としたうえで、特に実行環境やライブラリ、パッケージが特殊なものを要求しがちなシステムあることから、コンテナによる実装が適していると解説する。このユースケースに接したことで、ビッグデータは別系統のシステムが必要と思われがちな場合においても、マイクロサービスによるシステム構築が可能であると実証できたことはエンジニアにとっても大いに意義のあることであったように思われる。

山口氏によるまとめ
ヤフーの新サービスを支えるコンテナ技術
続いて登壇したヤフージャパンの小澤真佐也氏とヤフージャパンの100%子会社であるゼットラボ(Z Lab)の須田一輝氏の講演は、「Yahoo!ズバトク」というヤフージャパンが展開するサービスにおけるKubernetesの利用と、その土台となったKubernetes-as-a-Serviceに関する内容だ。
OpenStack上に構築された独自パッケージマネージャーとPHPによるアプリケーション開発から、KubernetesとDocker、そしてCIツールであるConcourse、開発言語としてJavaを使った新しいシステムに移行したことによって自動化が進み、巨大なヤフージャパンのデータセンターにおいて、ミスの軽減と効率化が進められたという。

ズバトクを支えるプラットフォーム
特に障害発生時の対応は、セルフヒーリングの機能を活用することで作業効率が向上したことを紹介した。

障害発生の対応が変化
ここでは作業を自動化することがインフラストラクチャーにおいては重要であり、そのための基盤としてKubernetesは十分に利用可能であることを力説した形になった。

自動化が要点
またKubernetesの分散基盤としてetcdが使われているのはよく知られるところだが、そのetcdを利用したCustomResourceDefinitionを積極的に活用して、Kubernetes APIを拡張しているのは、先進的なユースケースとして注目すべきところだろう。
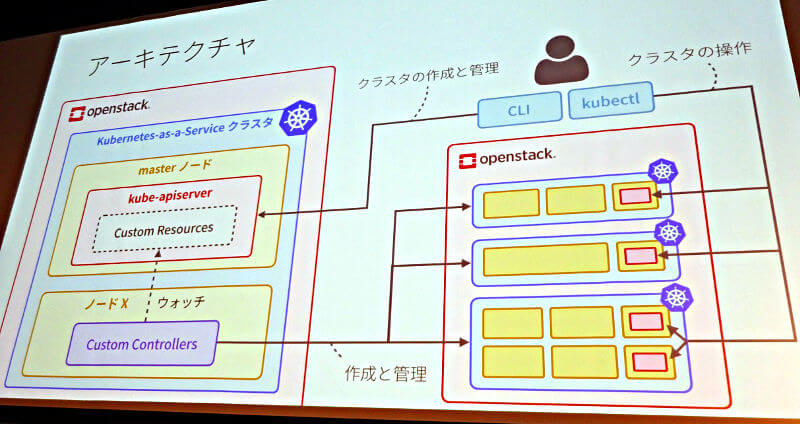
CRDとカスタムコントローラーを使ったシステムの概要
サイバーエージェント、メルカリ、そしてヤフージャパン各社の事例は、コンテナとKubernetesのユースケースとしては先進的なものであるが、機械学習とインフラの自動化に向けた分散システム基盤としての応用は、非常に参考になるものであった。単にPoCとしての利用から、クラウドネイティブなシステムによるビジネスへの直接的なインパクトに視点が移っていることを感じさせるキーノートセッションであった。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
