先進ユーザーがリードするHadoop/Spark応用事例~Sparkで5倍の性能アップ~
Sparkはビッグデータソフトウェアのテイラー・スウィフト?それとも北川景子?
2016年2月18日 7:00
2016年2月8日、日本Hadoopユーザー会が東京都内で「Hadoop/Spark Conference 2016」を開催。同イベントではHadoop及び新たな分散処理エンジン「Apache Spark」を軸に、導入事例や関連ソフトウェアの解説など20を超えるセッションに1000名以上が参加した。
午前:キーノート講演
まず冒頭に登壇したのはHadoopユーザー会代表、NTTデータの濱野賢一朗氏だ。濱野氏はHadoopのエコシステムがMapReduceとHDFSのシンプルなセットからリソース管理のYARNやHadoopをSQLで操作できるHiveなどに広がりをみせていることを紹介し、「これはかつてLinuxが通った道」と解説。Linuxの様々なディストリビューションが結果的に収束してきたことになぞらえて、「今のHadoopをめぐる環境は過渡期だ」という見解を述べた。

図1: 拡がるHadoopのエコシステム
次にHadoopコミッタの鯵坂 明氏と小沢健史氏が登壇し、YARNの将来と日本におけるHadoopコミュニティの拡大について解説。「日本におけるHadoop開発コミュニティへの貢献」としてNTTやNTTデータ、ヤフージャパンのエンジニアが多くのコードを提供していることを紹介した。イベントのスポンサーでもあるNTTデータやリクルートテクノロジーズと共に、ベンダー主導ではなくユーザー主導で日本のエンジニアが働いていることを感じさせるスライドであった。
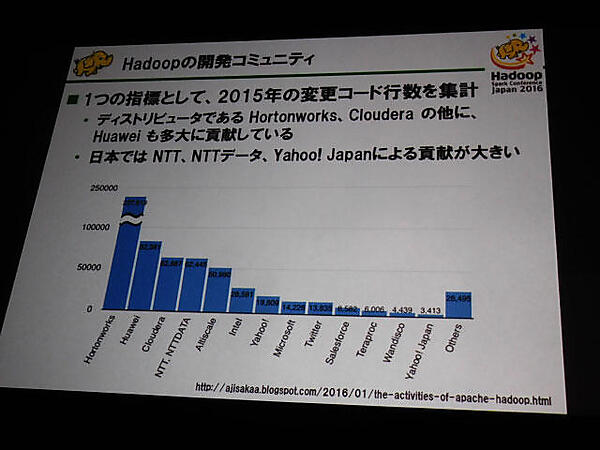
図2: 開発コミュニティの状況。Hadoop御三家以外にもファーウェイが意外と検討している
続いて登壇したのはヤフージャパンの遠藤禎士氏だ。同氏はHadoopを使いこなしているユーザーの立場から「Yahoo! JAPANのデータプラットフォームの全体像と未来」をテーマに、膨大なアクセスをさばくHadoopシステムの概況を解説した。年次数倍規模でデータやアクセスが増大する広告業界などの需要に対応するべく、約6000ノード、120PBの膨大なシステムのチューニングを行っているという。
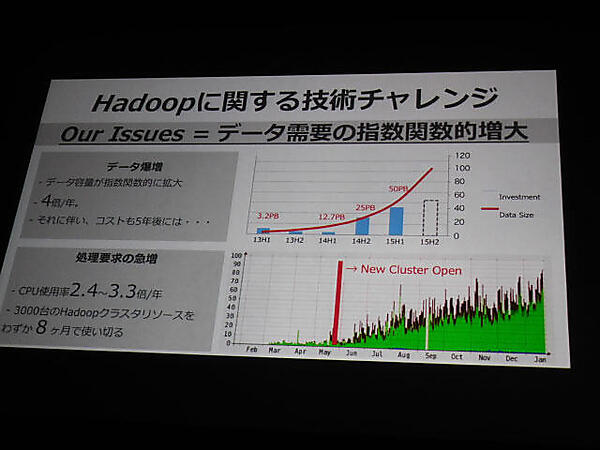
図3: ヤフージャパンにおけるHadoopのチャレンジ
次に登壇したのは、ClouderaのエンジニアTodd Lipcon氏。同氏はHadoop御三家のひとつ、Clouderaが開発をリードする新しいHadoop分散ストレージ「Kudu」を紹介した。KuduはHDFSとHBaseの間を埋める形、すなわち高速のスキャンとランダムアクセスが両立されることを目標に開発が進められているという。また、KuduはHDFSがマスターノードの障害時にSPOF(単一障害点)となる欠点をRaftコンセンサスアルゴリズムで解消できるアーキテクチャーを実装していることも特長の1つと解説した。

図4: Apache Kuduの位置づけ
続いてSparkのコミッタである猿田浩輔氏が登壇した。日本初開催となる「Spark Conference」のオープニングという形でSparkの現状を解説。参加申し込み時のアンケート結果などから日本でも確実にSparkの導入が拡がっていることを紹介した。
最後に登壇したのはSparkを産み出したスタッフが創業したDatabricksのエンジニア、Raynold Xin氏だ。Xin氏はSparkのバックエンドでコードを実行するエンジンをさらに高速化するオープンソースプロジェクト「Project Tungsten」を紹介。TungstenはJavaのメモリー利用やフロントエンドから渡される実行コードの自動生成とコンパイラーを最適化し、Sparkの処理を10~100倍程度まで高速化することを目標に開発が進められている。従来のインタープリターベースのコードとTungstenが自動生成したコードの実行速度では、約10倍の高速化が可能になったという。
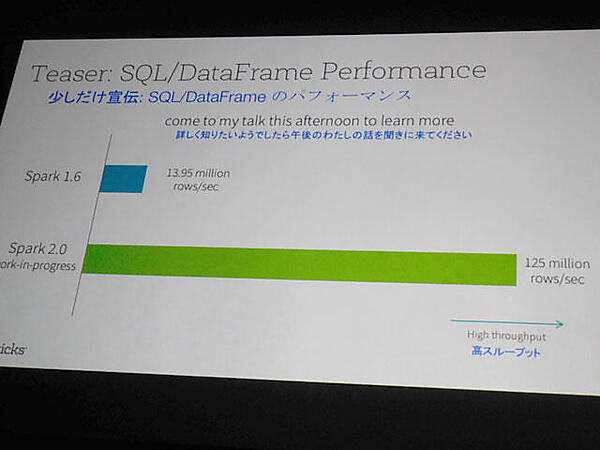
図5: Spark1.6と2.0の性能比較
午後:技術セッション
午後からは行なわれた技術セッションでは、さくらインターネットの須藤武文氏が同社の導入事例を紹介。原価計算処理システムをHadoopからSparkに替えたことで格段に性能が向上したという。須藤氏は「最先端のことはやっていない。単にAsakusa Frameworkを使ってバックエンドをHadoopからSparkに載せ替えただけ」と前置きしながらも、従来は月次や年次で発生する電気代や通信費などの原価計算を日次単位まで落とし込み、データセンターのラックに実装されているサーバー1台単位、さらに接続されるポート単位で計算できるようにした。この部分のバッチ処理をHadoopで行っていたものをSparkに載せ替えることで約5倍の性能向上を実現できたという。

図6: さくらインターネットにおけるSpark導入の効果
イベントを終えて
今回の「Hadoop/Spark Conference 2016」は、すべてユーザー会の会員によるボランティアで計画と実施が行われたという。Doug Cutting氏がヤフーのエンジニアとしてHadoopを作り始めた当時の「ユーザー企業が自分たちが必要とするものを作り上げる」という精神に通じるのだろうか。いわゆるインフラ系とは違う「即ビジネスに結びつく」ソリューションなだけに、日本でもシステムインテグレーターよりもユーザー企業が率先して活用の知見を蓄積していることを考えると、ベンダーよりも遥かにユーザーが知っているという日本では珍しい状況になりそうである。
全体的に1日のイベントとしては快適に運用されており、Hadoopユーザー会の過去数年の苦労が活かされていることを感じることができた。しかし、3ヶ月ごとに出されるというSparkのUpdate、及びそれに伴う技術解説やさらなる拡がりをみせるユーザー事例などを考えると、1日で済むようなイベントは今回限りかもしれない。今年はSparkがより大きくクローズアップされることは間違いないだろう。
ちなみに、前出のRaynold Xin氏によると、USではSparkを「ビッグデータソフトウェアのテイラー・スウィフト」と呼んでおり、日本式に言い直すと「ビッグデータソフトウェアの北川景子」なんだそうだ。これが妥当かの判断は読者のみなさんにお任せしたい。

図7: Sparkはビッグデータソフトウェアのテイラー・スウィフト?

図8: Sparkはビッグデータソフトウェアの北川景子?
この記事をシェアしてください
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
